











When a single module update cripples 47 teams...
It is Monday morning, 10:30 a.m. The platform engineering team of a major managed cloud services provider has just released a "harmless" update to the base module for VM instances, from v1.3.2 to v1.4.0. The change? A new but mandatory freeform tag for cost center allocation of resources.
What nobody has on the radar: the senior engineer who once insisted vehemently, as a decision-maker, that all Terraform modules should be placed in a single Git repository. “Versioning is too much micromanagement. This way it is tidier. And it requires less work,” he said at the time.
The same Monday, 3:00 p.m.: 47 teams from different customers have so far reported that their CI/CD pipelines are failing. The reason? Their root modules reference the provider’s updated modules, but nobody has implemented the new parameters in their own root modules. The provider’s compliance check is active and rejects the Terraform runs due to missing mandatory tags. What was planned as an improvement has turned into an organization-wide standstill with massive external impact on hosting customers.
Welcome to the world of module dependencies in Terraform @ Scale.
The hidden complexity of nested modules
Terraform modules are the backbone of any scalable Infrastructure-as-Code implementation. They promote reusability, encapsulate best practices, and reduce duplication. But as module depth increases, hidden complexity emerges that can surprise even experienced teams.
The ripple effect: Why module depth becomes a trap
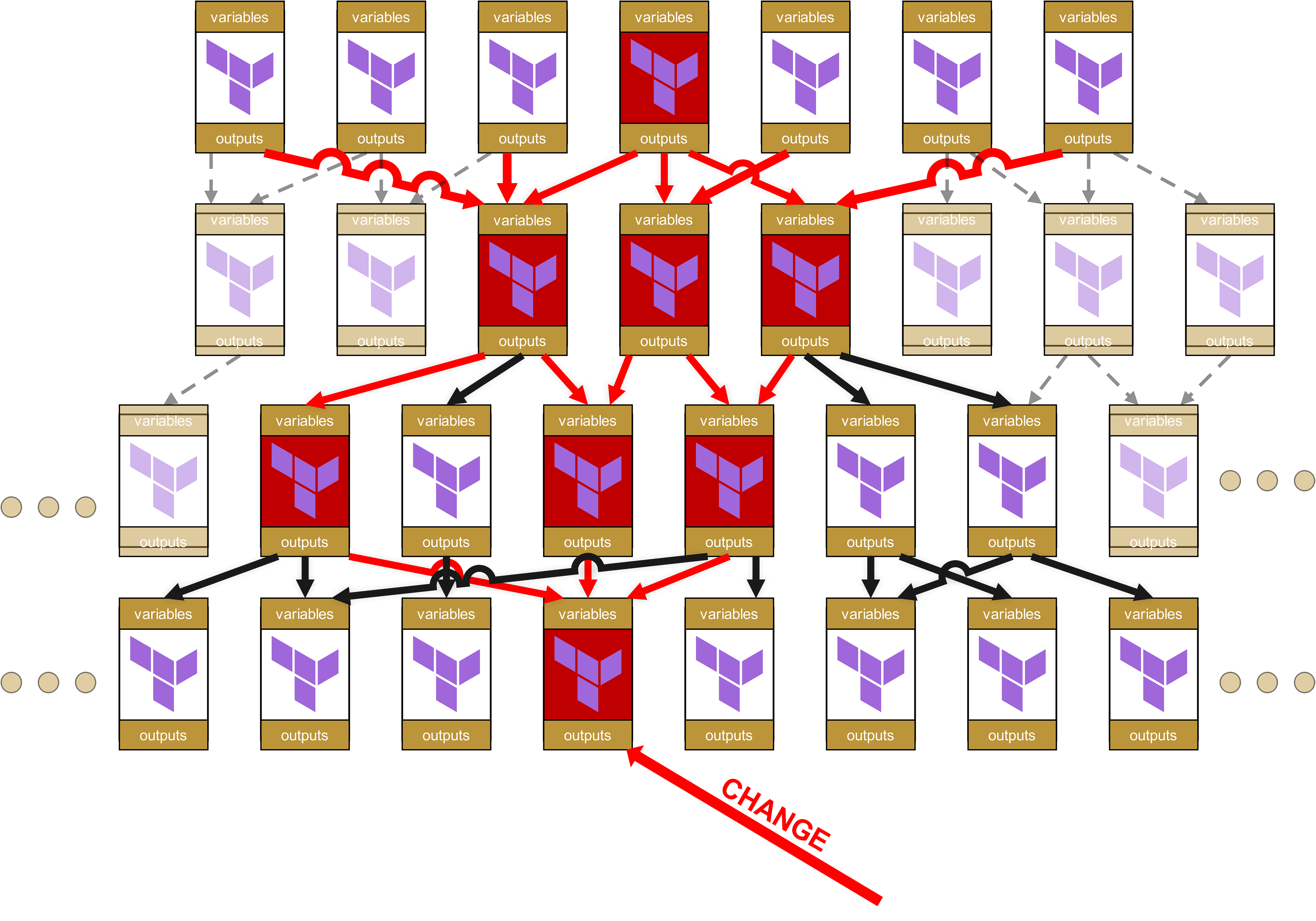
The problem can be illustrated with a simple example: imagine a four-level module hierarchy, as is often found in larger organizations. Let us start at the top, with a single root module:
![]()
This module calls other modules:
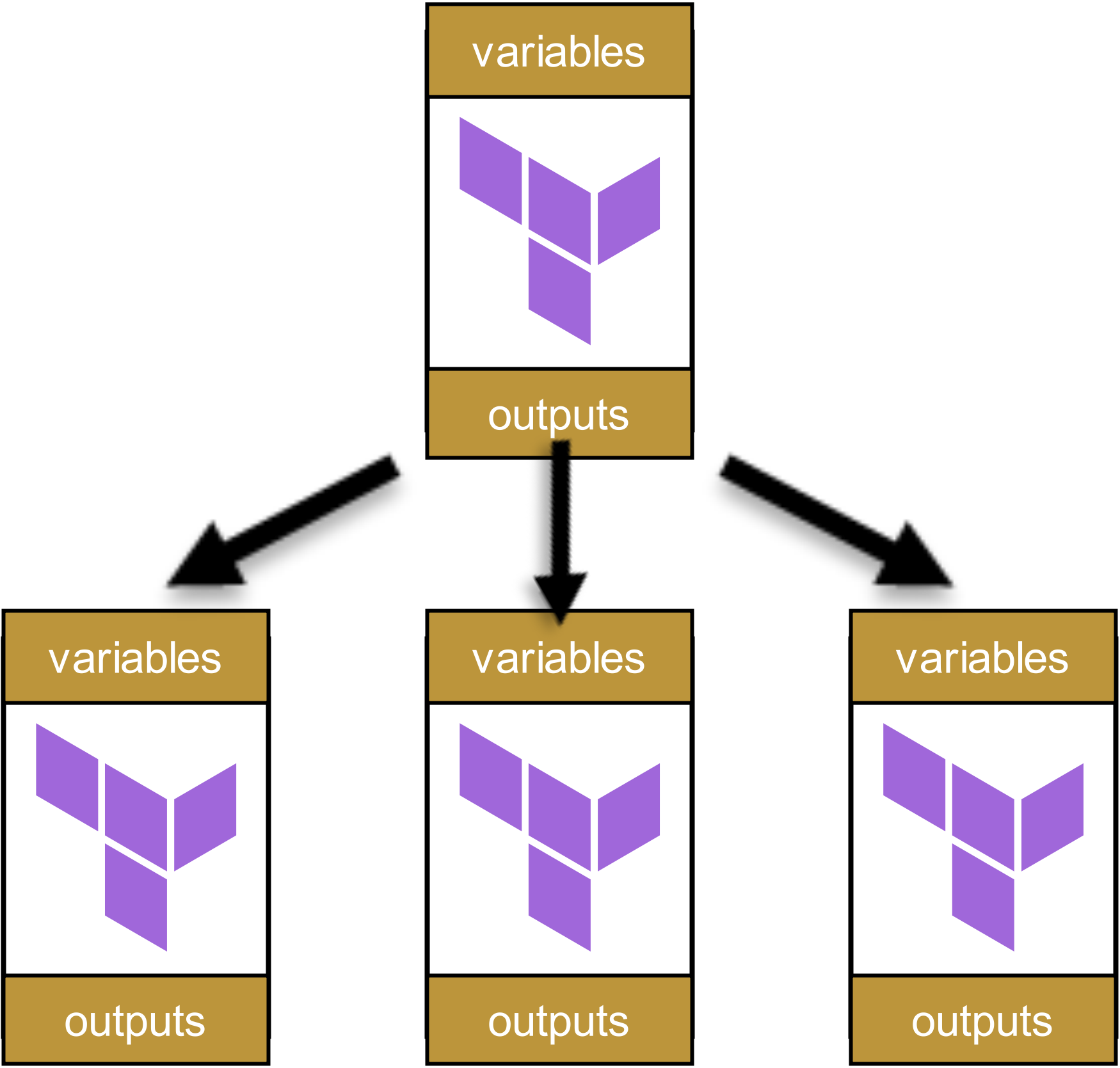
These in turn call other modules, which themselves call further modules. A dependency tree emerges, something like this:
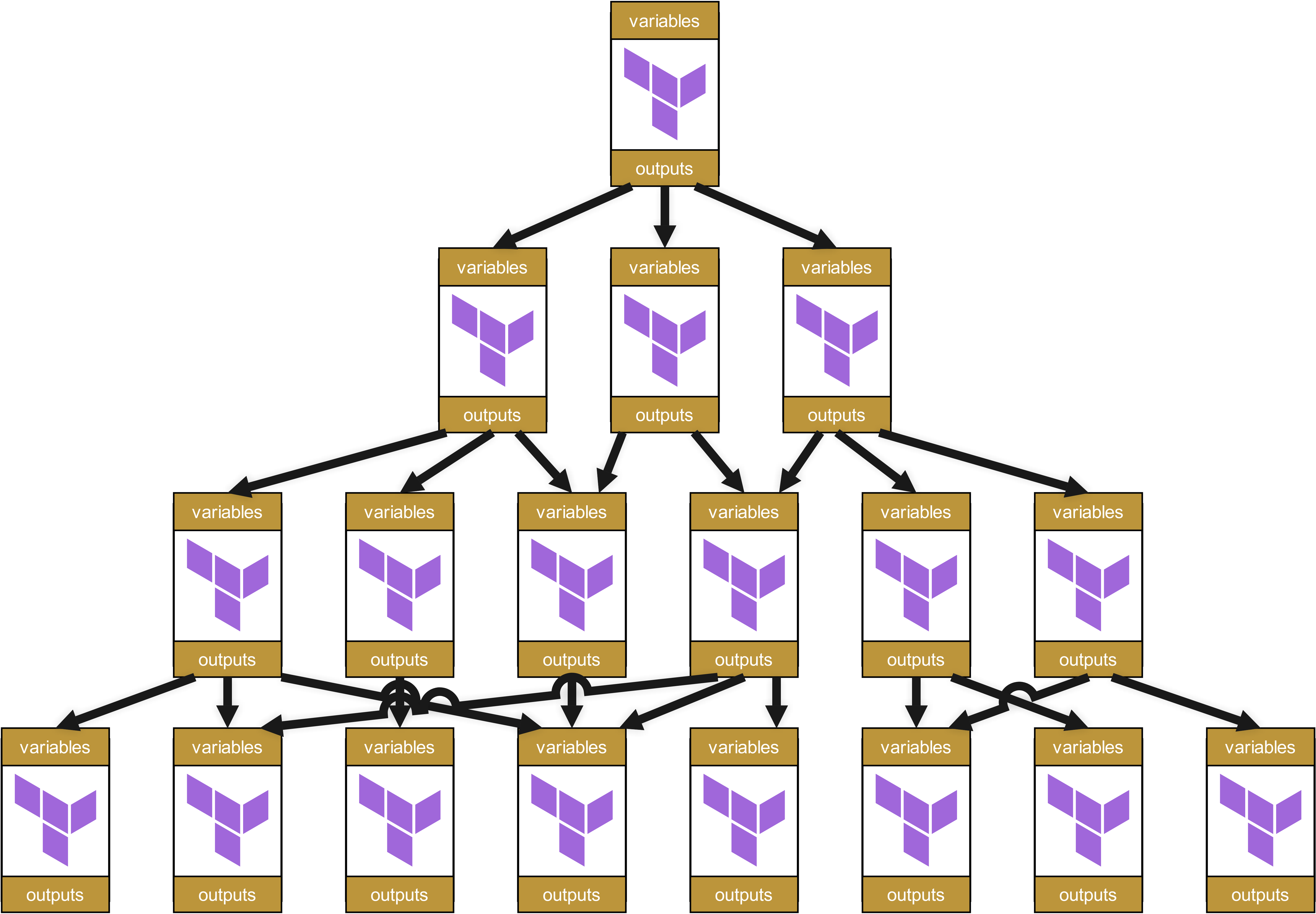
At first glance, this structure looks neat and well organized. Each module has clearly defined variables and outputs, passed cleanly between the layers.
Looks good, does it not? Well …
Good luck debugging and fixing if something goes wrong.
Because the further down in the hierarchy a change occurs, the greater the so-called "ripple effect" all the way to the top. Consider: what happens if something changes in a base module at the very bottom - whether it is a new mandatory parameter, a changed output name, or a modified validation rule. What happens then?
So let us assume there is now a change in a module on the lowest level.
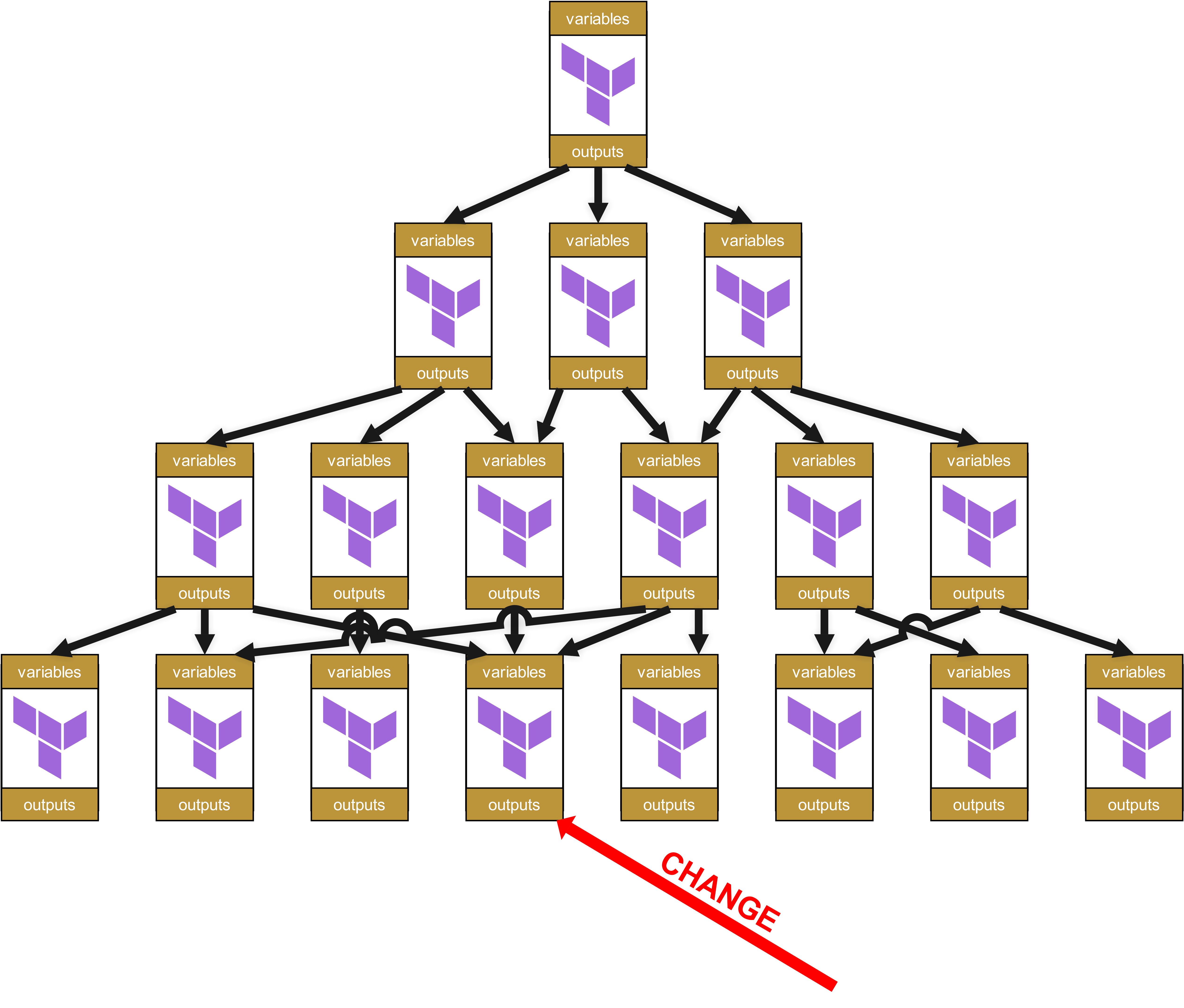
On the organizational level, change requests are now needed all the way up the tree to the root for all dependent modules and the infrastructures in which these dependent modules are used.
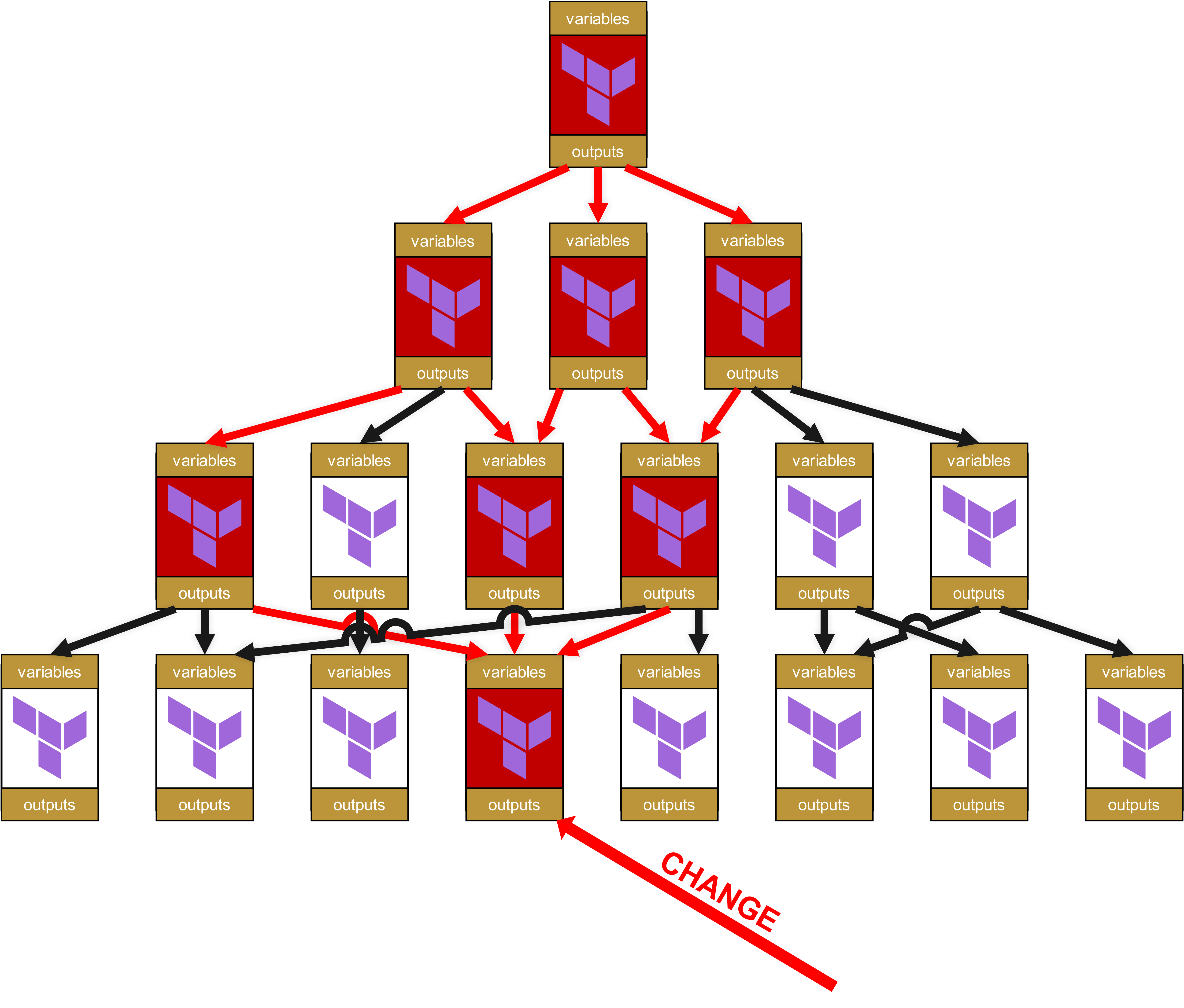
Oh dear, plenty of potential for joy here. Because you read that correctly: there are not only impacts all the way to the top, but that small change in the module at the very bottom means that all the now red-marked modules have to be pushed through the test pipeline again. And better yet, since I already said “change request”: for every infrastructure in which a red-marked module is used directly or indirectly via dependencies (red arrows), a comprehensive change request is necessary. This also means that you have to inform other teams or even customers that they in turn need to thoroughly test their own infrastructures.
In addition, on the technical level, an absurd amount of overhead quickly accumulates. Each module has its own variables and its own outputs that need to be passed up and down. The structure in the state file becomes increasingly horrendous and customer-unfriendly, with paths like module.<resource>.module.<resource>.module.<resource>.... This is not only visually unattractive, but also operationally relevant, because such overly long paths make manual state troubleshooting more difficult.
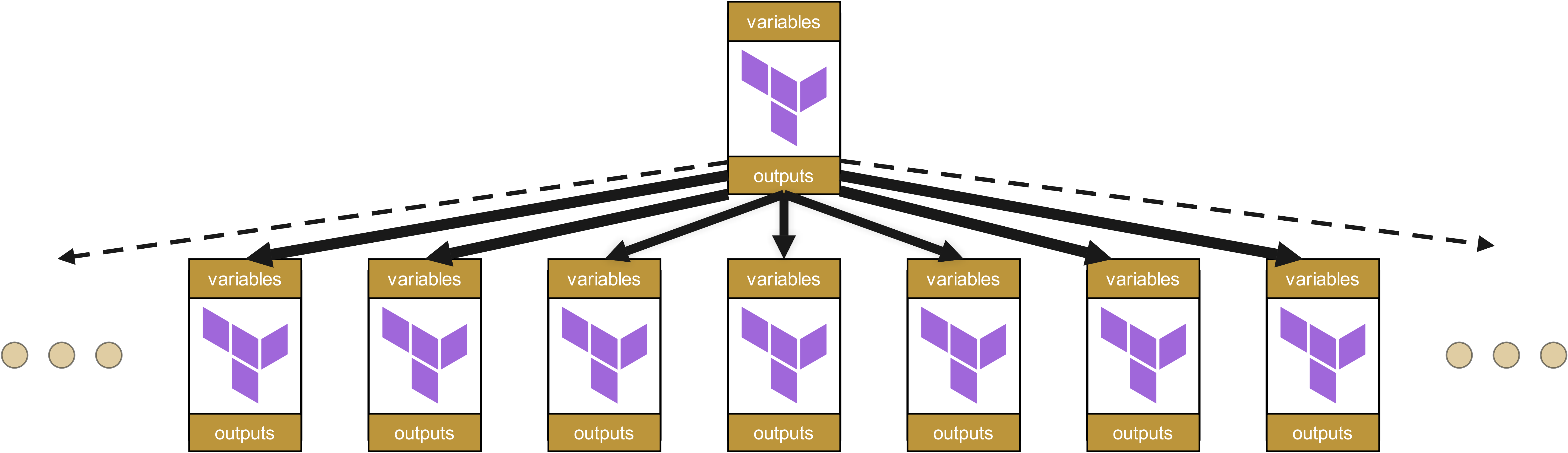
And here we have even simplified, since we have only spoken of one root module. In practice, however, each team and each customer has at least one, and probably quite a few of them:
At some point, for the customer, it becomes more effort in terms of code to use and manage a module than to directly provision the resources themselves.
And what happens then is clear:
-
First reinventing wheels,
-
then shadow IT,
-
then chaos in operations. And this finally leads to
-
a business-critical problem.
The alternative: Flat module organization
Module hierarchies should therefore be kept as flat as possible. A module organization similar to value streams is thus obvious, hierarchical infrastructure organization is inadvisable in most cases.
With flat structures, changes affect only directly dependent modules, not an entire cascade of dependencies. This significantly reduces both maintenance effort and the risk of unexpected side effects.
But here too, the elegance of the idea exists only at first glance.
The pendulum swings too far: Why completely flat structures fail
Before you drag all your modules into a single layer, you should pause. Because the other extreme of completely flat module organizations leads to its own, no less serious problems.
Without a certain hierarchical structure, what we call "Infrastructure-as-Copy&Paste" quickly emerges. Teams start developing almost identical modules for slightly different requirements instead of using existing abstractions. What once began as a reusable oci-compute-module fragments into oci-compute-web, oci-compute-api, oci-compute-batch and dozens of other variants. How many exactly? You will never know without asking your customers. And all these undefined numbers of module mutations share more than 80% of the same code, yet still all have their subtle differences that make later consolidation extremely difficult.
The result? A maintenance nightmare par excellence.
A security update now has to be applied to umpteen different "compute modules" instead of a central base module. Fixes are therefore generally implemented inconsistently. Standards drift apart. The DRY principle (Don't Repeat Yourself) becomes a laughing stock, while developers reinvent the wheel in endless variations. Compliance goes down the drain, and with a delay, your company’s security certification follows at some point.
Particularly insidious: incompatibilities often remain unnoticed for months, sometimes even years, until suddenly a company-wide compliance update is due. Or a customer's migration from one cloud provider to another. Then it turns out that supposedly "identical" modules differ in critical details. Then even an ostensibly simple blue/green deployment becomes a mammoth project.
The three-layer model: curse and blessing at the same time
In our previous articles, we already introduced the proven three-layer model. Let us briefly recap it:
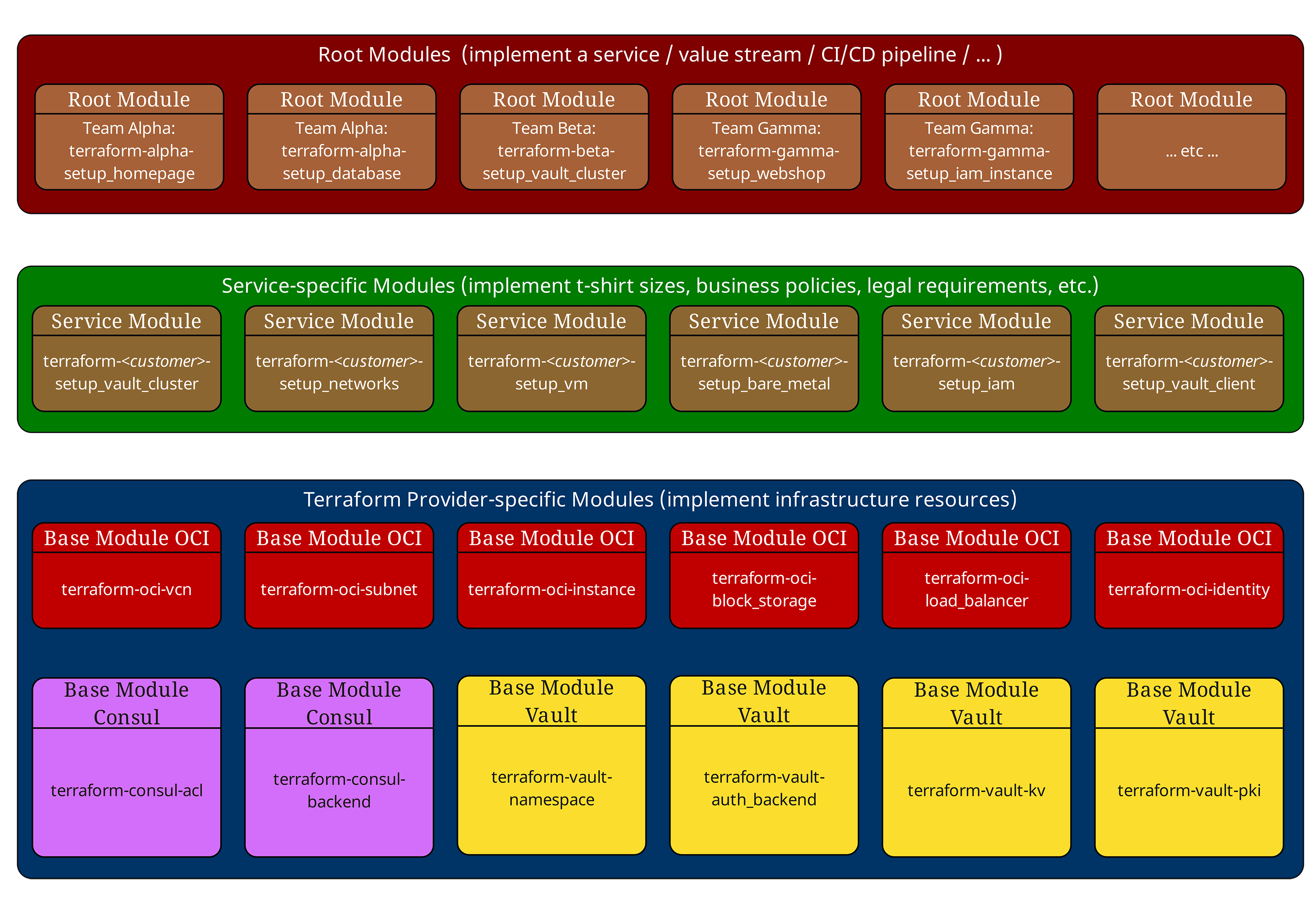
Root modules (top, red) orchestrate the entire infrastructure of an environment. They define provider configurations, backend settings, and call service modules.
Service modules (middle, green) implement company standards and "T-shirt sizes". They do not contain direct resource declarations, they only combine and configure base modules. Service modules also deliberately contain no provider or backend configurations and should have no provider-dependent side effects. This keeps them reusable in different root contexts.
Base modules (bottom, blue) interact directly with cloud providers and implement atomic infrastructure components such as VMs, networks, or databases.
This structure works excellently until the dependencies become truly complex. And then the blessing easily turns back into a curse.
Example of a typical module hierarchy
Let us look at a real module structure from a customer project:
# Root Module - Production Environment
module "web_application" {
source = "git::https://gitlab.ict.technology/modules//services/web-application?ref=v2.1.0"
environment = "production"
instance_size = "large"
high_availability = true
region = "eu-frankfurt-1"
}
module "database_cluster" {
source = "git::https://gitlab.ict.technology/modules//services/mysql-cluster?ref=v1.8.3"
environment = "production"
storage_tier = "premium"
backup_enabled = true
}
The service module web-application looks like this internally:
# Service Module - services/web-application/main.tf
locals {
instance_configs = {
small = { ocpus = 2, memory_gb = 8, storage_gb = 50 }
medium = { ocpus = 4, memory_gb = 16, storage_gb = 100 }
large = { ocpus = 8, memory_gb = 32, storage_gb = 200 }
}
config = local.instance_configs[var.instance_size]
}
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.3.2"
instance_count = var.high_availability ? 3 : 1
shape_config = {
ocpus = local.config.ocpus
memory_in_gbs = local.config.memory_gb
}
compartment_id = var.compartment_id
}
module "load_balancer" {
source = "git::https://gitlab.ict.technology/modules//base/oci-loadbalancer?ref=v2.0.1"
backend_instances = module.compute_instances.instance_ids
compartment_id = var.compartment_id
}
module "networking" {
source = "git::https://gitlab.ict.technology/modules//base/oci-networking?ref=v1.5.7"
vcn_cidr = var.environment == "production" ? "10.0.0.0/16" : "10.1.0.0/16"
availability_domains = var.high_availability ? 3 : 1
compartment_id = var.compartment_id
}
We already see the first problem here: transitive dependencies. The root module sees only the service modules it pulls in. It does not "know" which base modules are actually used or in which versions.
And guess what Terraform does not offer native support for: the management of such transitive dependencies. With our dependency tree from above, you have no built-in way in Terraform to find out which dependencies are colored red and where you have to submit change requests.
All Terraform offers you here is an inadequate implementation of outputting a dependency graph from top to bottom, but not from bottom to top - terraform graph. And as soon as remote states come into play, even that is over, because terraform graph can only handle a single state file.
Workarounds and usable approaches with external tools are possible, but they are anything but straightforward - and, ironically, especially when using Terraform Enterprise, often not easy to integrate:
-
Static scanning of modules with terraform-config-inspect or simple HCL analysis in CI to extract a list of all refs in the URLs of module sources including versions. This can be published per commit as an artifact.
-
Policies in Sentinel/Conftest/OPA or Checkov/TFLint that prohibit referencing modules without a fixed ref, detect mixed versions per environment, and for example allow "patch upgrades only" during maintenance windows.
-
Create a small internal "module SBOM" for each root run and version it. This in turn requires that every service and base module has its own SBOM, but with it you then answer the most critical operational questions:
-
Which version of a module is actually used?
-
Why does a module use an older version of another module?
-
How does an update of one module affect all dependent modules?
-
Are there security updates missing in any of the modules?
-
But Terraform’s lack of dependency management is not the biggest problem. It gets even worse.
The version tracking problem: Terraform’s greatest weakness
One of the most frustrating aspects of Terraform is the complete lack of native module version tracking. While terraform version shows the version of the Terraform binary, there is no built-in functionality for anything like this:
# Those commands do NOT exist in Terraform terraform modules list terraform modules version terraform dependencies show
Terraform Enterprise also does not provide a solution here at the time of writing that deserves the designation "Enterprise" - a disgrace for software with “Enterprise” in its name that quickly costs hundreds of thousands of dollars per year in subscription fees.
Why is this a problem?
Imagine you have this module structure in production:
Production Infrastructure (deployed: 2024-09-01) ├── Root Module: production-env (v1.0.0) │ ├── Service Module: web-application (v2.1.0) │ │ ├── Base Module: oci-compute (v1.3.2) │ │ ├── Base Module: oci-loadbalancer (v2.0.1) │ │ └── Base Module: oci-networking (v1.5.7) │ └── Service Module: mysql-cluster (v1.8.3) │ ├── Base Module: oci-compute (v1.2.8) ← Different version! │ └── Base Module: oci-storage (v3.1.0)
Critical questions without simple answers, which we already raised earlier in the text in connection with the module SBOMs:
-
Which version of oci-compute is actually being used?
-
Why does mysql-cluster use an older version of oci-compute?
-
How does an update of oci-compute affect all dependent modules?
-
Are there security updates missing in any of the modules?
Real-world impact: The MySQL cluster incident
A concrete real-world example: a customer had implemented a critical security patch for the oci-compute base module that fixed a vulnerability in the metadata service configuration. The update was applied only in the web-application service module, while the mysql-cluster service module continued referencing the old, vulnerable version.
The result? A penetration test three months later uncovered the security gap in the database servers - a gap the team already believed to be "patched".
In the next chapter we will therefore look at suitable approaches for version tracking of Terraform modules.
