











Wenn ein einziges Modul-Update 47 Teams lahmlegt...
Es ist Montagmorgen, 10:30 Uhr. Das Platform-Engineering-Team eines großen Anbieters für Managed Cloud Services hat gerade ein "harmloses" Update des Basismoduls für VM-Instanzen von v1.3.2 auf v1.4.0 veröffentlicht. Die Änderung? Ein neues, aber obligatorisches Freeform-Tag zur Kostenstellenzuordnung von Ressourcen.
Was niemand auf dem Radar hat: Den Senior Engineer, der einst als Entscheidungsträger vehement darauf bestand, sämtliche Terraform-Module in einem einzigen Git-Repository abzulegen. “Versionierung ist zuviel Micromanagement. So ist es aufgeräumter. Und macht weniger Arbeit”, hat er damals gesagt.
Der gleiche Montag, 15:00 Uhr nachmittags: 47 Teams von unterschiedlichen Kunden melden bisher, dass ihre CI/CD-Pipelines fehlschlagen. Der Grund? Ihre Root-Module referenzieren die vom Anbieter bereitgestellten, aktualisierten Module, aber niemand hat die neuen Parameter in den eigenen Root-Modulen implementiert. Die Compliance-Prüfung des Anbieters ist aktiv und lehnt die Terraform-Runs wegen fehlender obligatorischer Tags ab. Was als Verbesserung geplant war, hat sich in einen organisationsweiten Stillstand mit massiver Außenwirkung auf Hostingkunden verwandelt.
Willkommen in der Welt der Modulabhängigkeiten bei Terraform @ Scale.
Die versteckte Komplexität verschachtelter Module
Terraform-Module sind das Rückgrat jeder skalierbaren Infrastructure-as-Code-Implementierung. Sie fördern Wiederverwendbarkeit, kapseln Best Practices und reduzieren Duplikation. Doch mit wachsender Modultiefe entsteht eine versteckte Komplexität, die selbst erfahrene Teams überraschen kann.
Der Ripple-Effect: Warum Modultiefe zur Falle wird
Das Problem lässt sich an einem einfachen Beispiel illustrieren: Stellen wir uns eine vierstufige Modulhierarchie vor, wie sie in größeren Organisationen häufig anzutreffen ist. Beginnen wir ganz oben, mit einem einzelnen Root-Modul:
![]()
Dieses Modul ruft andere Module auf:
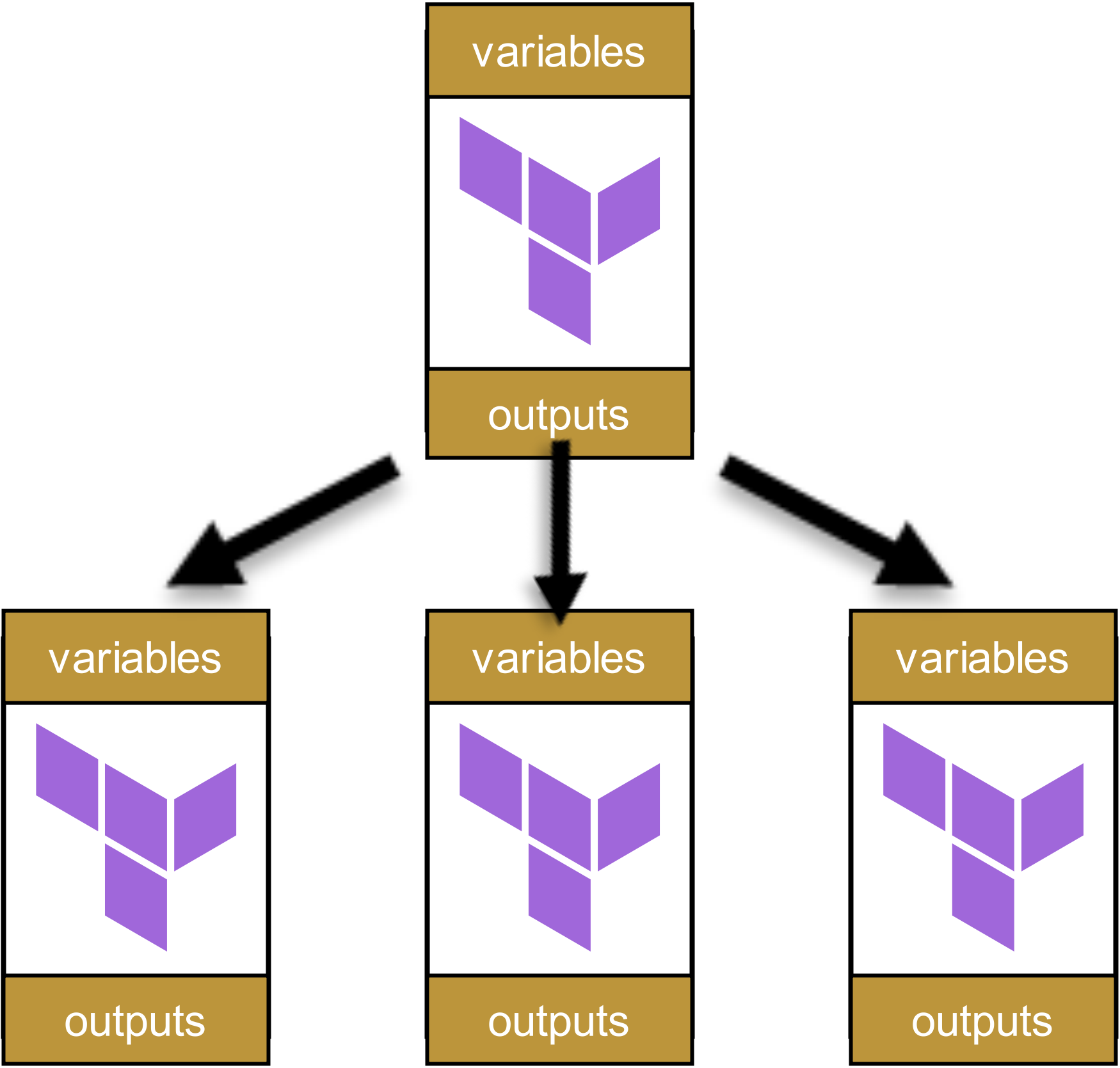
Diese wiederum rufen andere Module auf, die ihrerseits wieder Module aufrufen. Es entsteht ein Dependency Tree, ungefähr so:
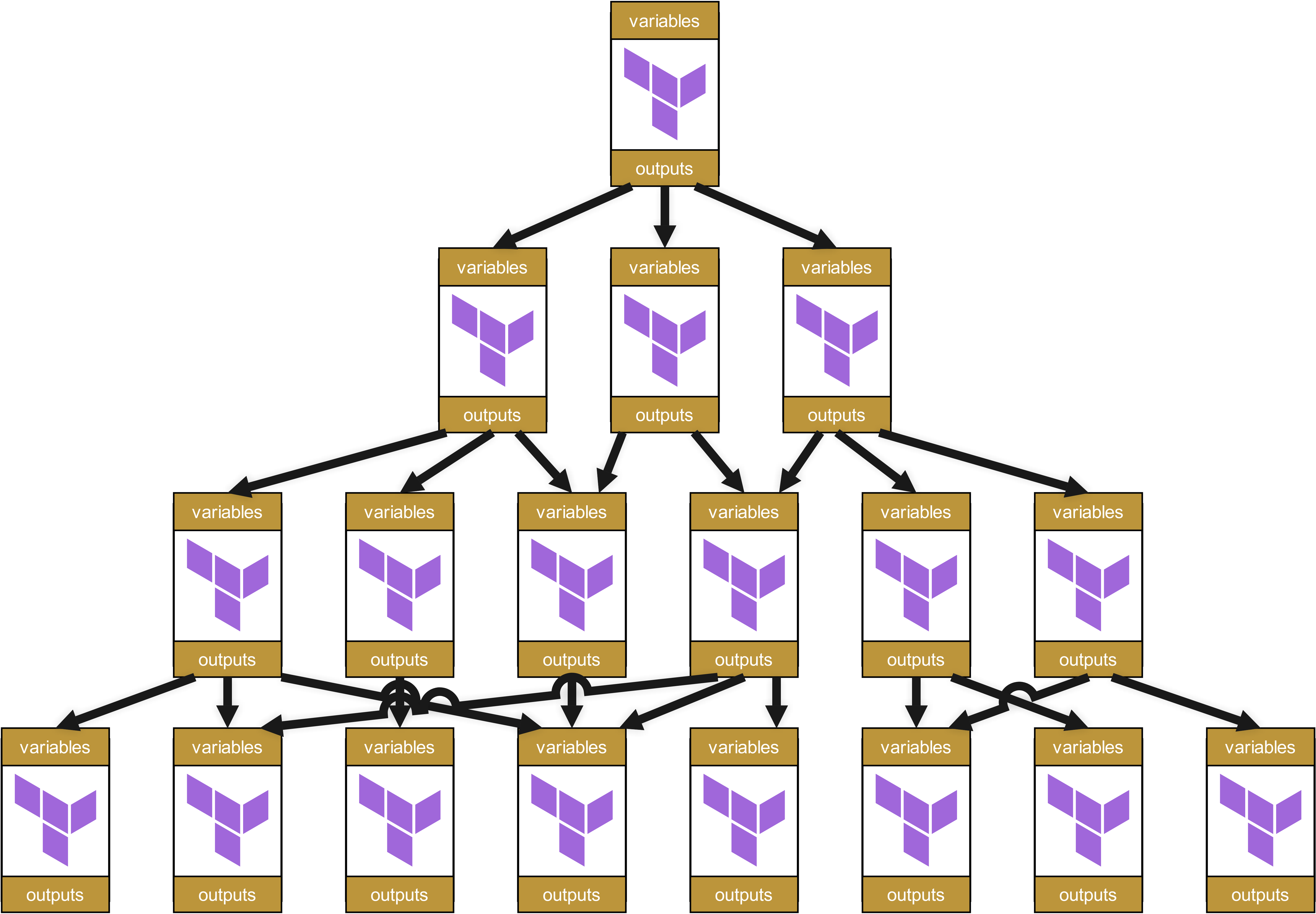
Auf den ersten Blick wirkt diese Struktur ordentlich und gut organisiert. Jedes Modul hat klar definierte Variablen und Outputs, die sauber zwischen den Ebenen weitergegeben werden.
Sieht doch ganz gut aus, oder nicht? Naja …
Viel Spaß beim Debuggen und Fixen, wenn es irgendwo ein Problem gibt.
Denn je weiter unten in der Hierarchie sich eine Änderung befindet, desto größer wird der sogenannte "Ripple Effect" bis nach ganz oben. Überlegen Sie: Wass passiert, wenn sich in einem Basis-Modul ganz unten etwas am Code ändert, sei es ein neuer obligatorischer Parameter, ein geänderter Output-Name oder eine veränderte Validierungsregel. Was passiert dann?
Stellen wir uns daher vor, auf der untersten Ebene gibt es jetzt einen Change in einem Modul.
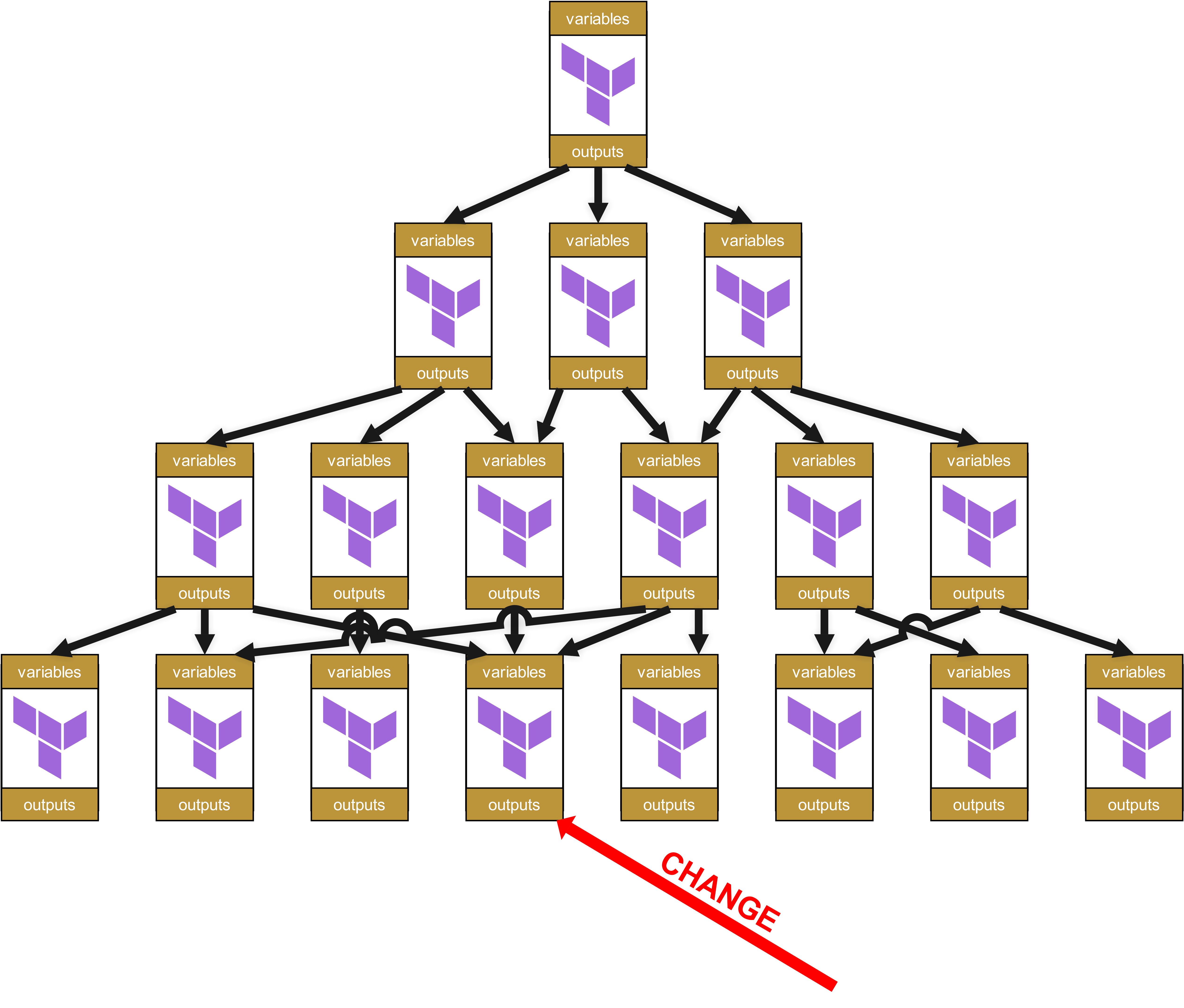
Auf der organisatorischen Ebene braucht es den ganzen Baum hinauf bis zur Wurzel jeweils Change Requests für alle davon abhängigen Module und die Infrastrukturen, in welchen diese abhängigen Module benutzt werden.
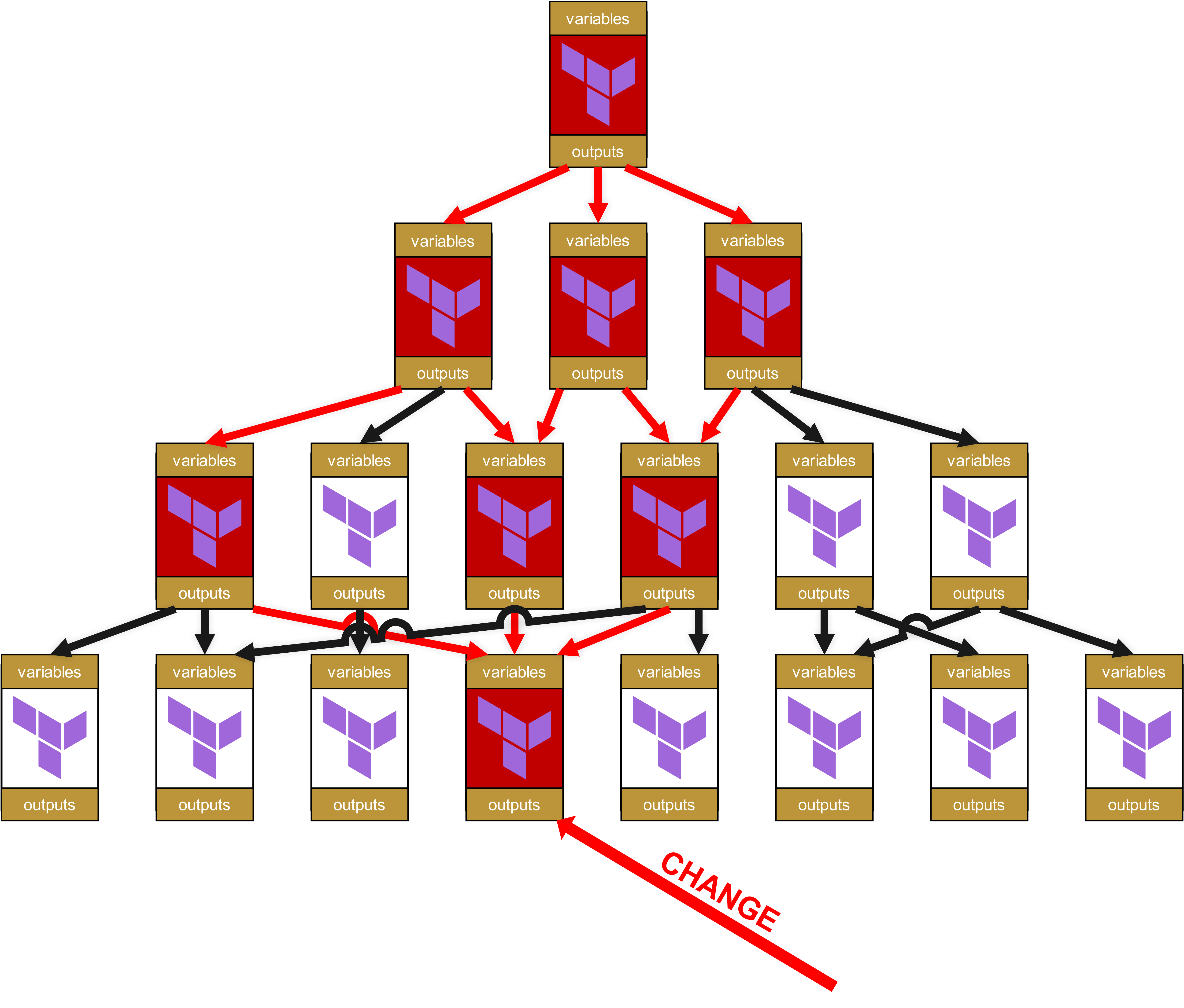
Oha, hier schlummert bereits großes Potenzial zur Freude. Denn Sie haben richtig gelesen: Es gibt also nicht nur Auswirkungen bis ganz nach oben, sondern die kleine Änderung in dem Modul ganz unten sorgt dafür, dass alle jetzt rot markierten Module neu durch die Testpipeline geschickt werden müssen. Und besser noch, denn ich sagte bereits “Change Request”: Für jede Infrastruktur, in welcher ein rot markiertes Modul unmittelbar oder auch nur mittelbar über Dependencies (rote Pfeile) eingesetzt wird, ist ein umfassender Change Request notwendig. Das heißt dann auch, dass man andere Teams oder gar Kunden darüber informieren muss, dass diese wiederum ihre eigenen Infrastrukturen umfassend testen müssen.
Hinzu kommt auf der technischen Ebene, dass sich schnell eine absurde Menge an Overhead ansammelt. Denn jedes der Module hat seine eigenen Variablen und seine eigenen Outputs, die hoch und runter weitergereicht werden müssen. Die Struktur im State-File wird zunehmend grauenvoller und kundenunfreundlicher mit Pfaden wie module.<resource>.module.<resource>.module.<resource>.... Dies ist nicht nur optisch unschön, sondern auch operativ relevant, weil solche überlangen Pfade das manuelle State-Troubleshooting erschweren.
Und hier hatten wir ja auch noch vereinfacht, denn wir haben nur von einem Root-Modul gesprochen. In der Praxis hat aber jedes Team und jeder Kunde mindestens eines, wahrscheinlich sogar ziemlich viele davon:
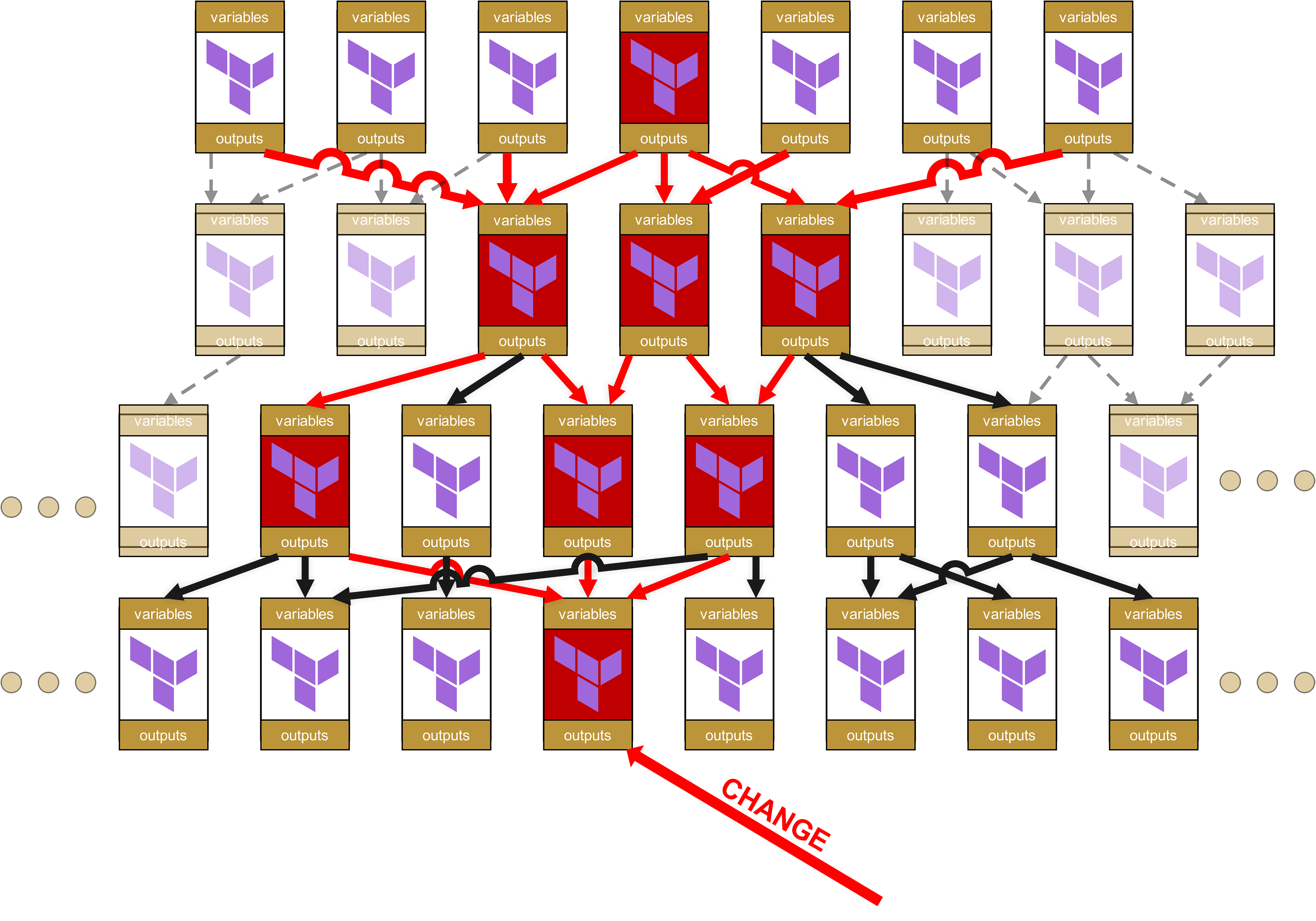
Irgendwann wird es für den Kunden mehr Codeaufwand, ein Modul zu benutzen und zu verwalten, als die Ressourcen selbst direkt anzufahren.
Und was dann passiert, ist klar:
-
Erst Neuerfinden von Rädern,
-
dann Shadow-IT,
-
dann Chaos im Betrieb. Und dies führt schließlich in
-
ein businesskritisches Problem.
Die Alternative: Flache Modulorganisation
Deshalb sollten Modulhierarchien so flach wie möglich gehalten werden. Eine Modulorganisation ähnlich Value Streams ist daher naheliegend – von hierarchischer Infrastruktur-Organisation ist in den meisten Fällen abzuraten.
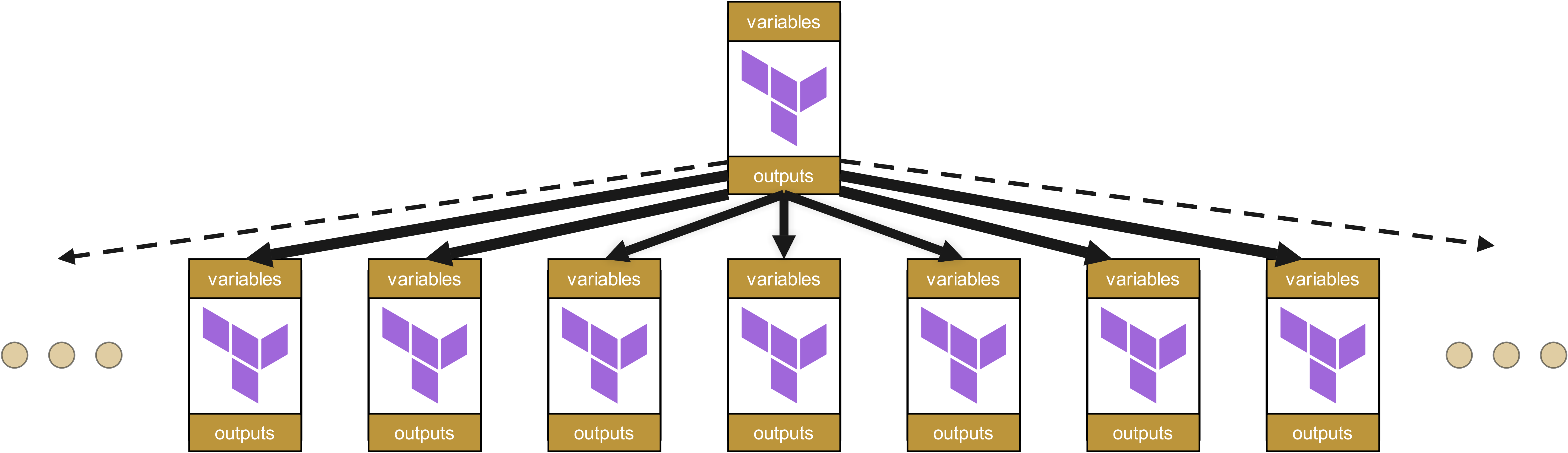
Bei flachen Strukturen wirken sich Änderungen nur auf direkt abhängige Module aus, nicht auf eine ganze Kaskade von Abhängigkeiten. Dies reduziert sowohl den Wartungsaufwand als auch das Risiko unerwarteter Seiteneffekte erheblich.
Aber auch hier existiert die Schönheit der Idee nur beim ersten Blick.
Das Pendel schlägt zu weit: Warum völlig flache Strukturen versagen
Bevor Sie nun alle Ihre Module in eine einzige Ebene zerren, sollten Sie innehalten. Denn das andere Extrem der völlig flache Modulorganisationen führt zu eigenen, nicht minder gravierenden Problemen.
Ohne eine gewisse hierarchische Struktur entsteht schnell das, was wir als "Infrastructure-as-Copy&Paste" bezeichnen. Teams beginnen, nahezu identische Module für geringfügig unterschiedliche Anforderungen zu entwickeln, statt bestehende Abstraktionen zu nutzen. Was einst als wiederverwendbares oci-compute-module begann, fragmentiert in oci-compute-web, oci-compute-api, oci-compute-batch und dutzende weitere Varianten. Wieviele genau? Das werden Sie nie wissen, ohne Ihre Kunden zu fragen. Und all diese undefiniert vielen Modulmutationen teilen zu >80% den gleichen Code, haben aber trotzdem alle ihre subtilen Unterschiede, die eine spätere Konsolidierung extrem erschweren.
Das Resultat? Wartungsalpträume par excellence.
Ein Sicherheitsupdate muss nun in -zig verschiedenen "Compute-Modulen" eingespielt werden, statt in einem zentralen Basis-Modul. Fixes werden deshalb generell inkonsistent implementiert. Standards driften auseinander. Das DRY-Prinzip (Don't Repeat Yourself) wird zum Gespött, während Entwickler das Rad in endlosen Variationen neu erfinden. Die Compliance geht den Bach runter, und zeitverzögert die Security-Zertifizierung ihres Unternehmens irgendwann hinterher.
Besonders tückisch: Die Inkompatibilitäten bleiben oft monate, manchmal sogar jahrelang unbemerkt, bis plötzlich ein unternehmensweites Compliance-Update ansteht. Oder die Migration eines Kunden von einem Cloud-Provider zu einem anderen. Dann stellt sich heraus, dass sich scheinbar "identische" Module in kritischen Details unterscheiden. Dann wird auch ein vermeintlich einfaches Blue/Green-Deployment zum Mammutprojekt.
Das Dreischichtenmodell: Fluch und Segen zugleich
In unseren vorherigen Artikeln haben wir bereits das bewährte Dreischichtenmodell vorgestellt. Lassen Sie es uns nochmals kurz rekapitulieren:
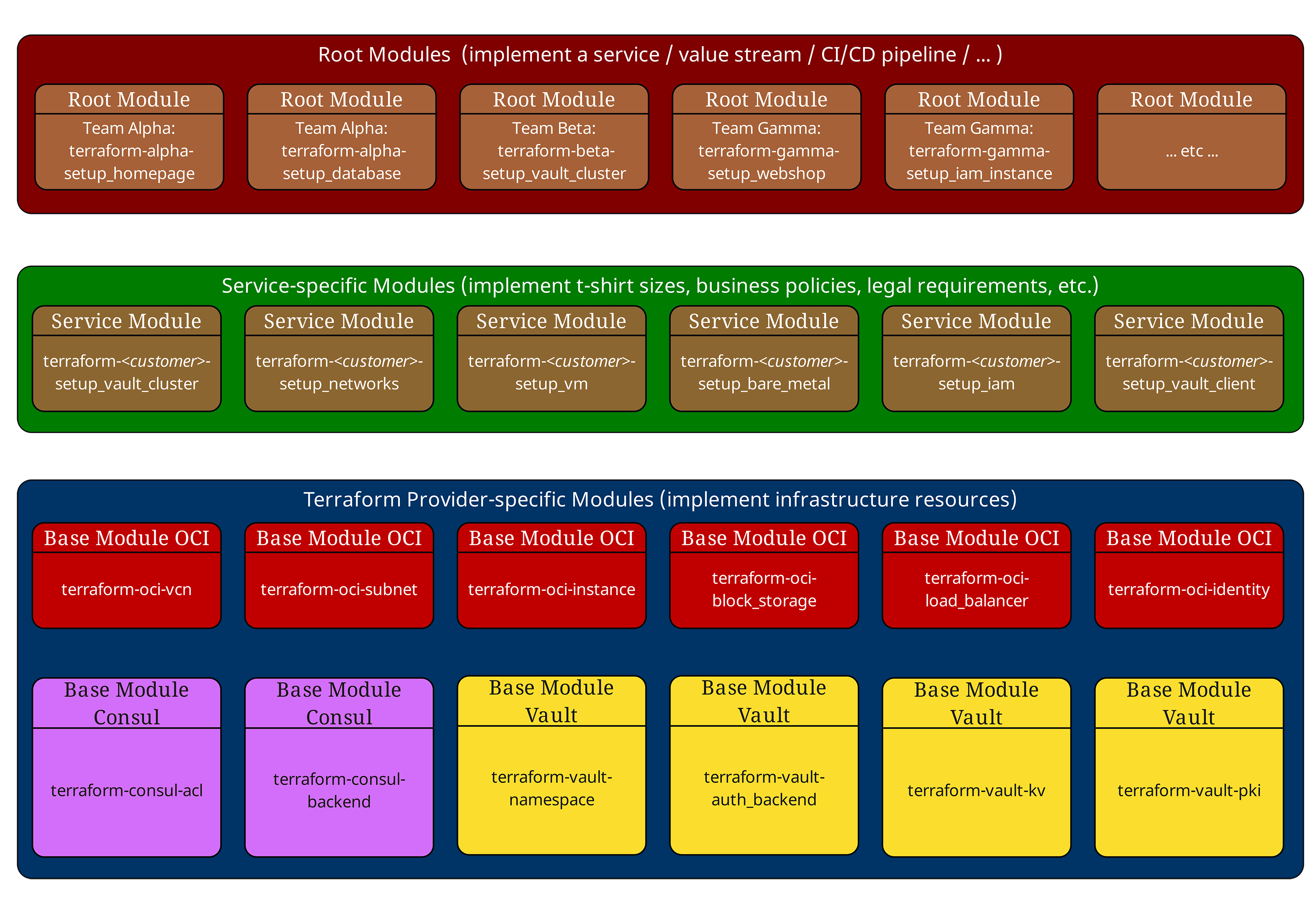
Root-Module (Oben, rot) orchestrieren die gesamte Infrastruktur einer Umgebung. Sie definieren Provider-Konfigurationen, Backend-Settings und rufen Service-Module auf.
Service-Module (Mitte, grün) implementieren Unternehmensstandards und "T-Shirt-Größen". Sie enthalten keine direkten Ressourcendeklarationen, sondern kombinieren und konfigurieren ausschließlich Basis-Module. Service-Module enthalten auch bewusst keine Provider- oder Backend-Konfigurationen und sollten keine Provider-abhängigen Seiteneffekte haben. So bleiben sie in unterschiedlichen Root-Kontexten wiederverwendbar.
Basis-Module (Unten, blau) sprechen direkt mit Cloud-Providern und implementieren atomare Infrastrukturkomponenten wie VMs, Netzwerke oder Datenbanken.
Diese Struktur funktioniert hervorragend - bis die Abhängigkeiten wirklich komplex werden. Und das wird der Segen leicht wieder zum Fluch.
Beispiel einer typischen Modulhierarchie
Betrachten wir eine reale Modulstruktur aus einem Kundenprojekt:
# Root Module - Production Environment
module "web_application" {
source = "git::https://gitlab.ict.technology/modules//services/web-application?ref=v2.1.0"
environment = "production"
instance_size = "large"
high_availability = true
region = "eu-frankfurt-1"
}
module "database_cluster" {
source = "git::https://gitlab.ict.technology/modules//services/mysql-cluster?ref=v1.8.3"
environment = "production"
storage_tier = "premium"
backup_enabled = true
}
Das Service-Modul web-application sieht intern so aus:
# Service Module - services/web-application/main.tf
locals {
instance_configs = {
small = { ocpus = 2, memory_gb = 8, storage_gb = 50 }
medium = { ocpus = 4, memory_gb = 16, storage_gb = 100 }
large = { ocpus = 8, memory_gb = 32, storage_gb = 200 }
}
config = local.instance_configs[var.instance_size]
}
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.3.2"
instance_count = var.high_availability ? 3 : 1
shape_config = {
ocpus = local.config.ocpus
memory_in_gbs = local.config.memory_gb
}
compartment_id = var.compartment_id
}
module "load_balancer" {
source = "git::https://gitlab.ict.technology/modules//base/oci-loadbalancer?ref=v2.0.1"
backend_instances = module.compute_instances.instance_ids
compartment_id = var.compartment_id
}
module "networking" {
source = "git::https://gitlab.ict.technology/modules//base/oci-networking?ref=v1.5.7"
vcn_cidr = var.environment == "production" ? "10.0.0.0/16" : "10.1.0.0/16"
availability_domains = var.high_availability ? 3 : 1
compartment_id = var.compartment_id
}
Bereits hier sehen wir das erste Problem: Transitive Abhängigkeiten. Das Root-Module sieht nur die angezogenen Service-Module. Es "weiß" nicht, welche Basis-Module tatsächlich verwendet werden oder in welchen Versionen.
Und raten Sie mal, wofür Terraform keine native Unterstützung bietet: Das Management solcher transitiver Abhängigkeiten. Sie haben bei unserem Dependency Tree von weiter oben keine Möglichkeit, mit Bordmitteln von Terraform herauszufinden, welche Abhängigkeiten rot gefärbt werden und wofür Sie überall Change Requests einreichen müssen.
Alles, was Ihnen Terraform hier bietet, ist eine ungenügende Implementation der Ausgabe eines Dependency-Graphen von oben nach unten, aber nicht von unten nach oben - terraform graph. Und sobald Remote States mit ins Spiel kommen, ist es selbst damit vorbei, denn terraform graph kann nur ein einzelnes Statefile verwalten.
Workarounds und nutzbare Ansätze mit externen Tools sind möglich, aber auch alles andere als unmittelbar zum Ziel führend - und ironischerweise ausgerechnet bei Verwendung von Terraform Enterprise oft nicht einfach integrierbar:
-
Statisches Scannen der Module mit terraform-config-inspect oder einfacher HCL-Analyse in CI, um eine Liste aller Refs in den URLs der Modul-Sources samt Versionen zu extrahieren. Das lässt sich pro Commit als Artefakt publizieren.
-
Policies in Sentinel/Conftest/OPA oder Checkov/TFLint, die verbieten, Module ohne feste Ref zu referenzieren, die Mischversionen pro Umgebung detektieren und z. B. “nur Patch-Upgrades” in Maintenance-Fenstern erlauben.
-
Ein kleines internes “Module SBOM” je Root-Run erzeugen und versionieren. Dies setzt wiederum voraus, dass jedes Service- und Basis-Modul über einen eigenen SBOM verfügt, aber damit beantworten Sie dann die kritischsten Fragen operativ:
-
Welche Version eines Moduls wird tatsächlich verwendet?
-
Warum nutzt ein Modul eine ältere Version eines anderen Moduls?
-
Wie wirkt sich ein Update eines Moduls auf alle abhängigen Module aus?
-
Gibt es Sicherheitsupdates, die in einem der Module fehlen?
-
Aber die fehlende Abhängigkeitsverwaltung von Terraform ist nicht das größte Problem. Es kommt noch dicker.
Das Versionsverfolgungsproblem: Terraforms größte Schwäche
Einer der frustrierendsten Aspekte von Terraform ist das vollständige Fehlen einer nativen Modulversionsverfolgung. Während terraform version die Version des Terraform-Binaries anzeigt, gibt es keine eingebaute Funktionalität für etwas wie dieses:
# Those commands do NOT exist in Terraform terraform modules list terraform modules version terraform dependencies show
Auch Terraform Enterprise bietet hier zum Zeitpunkt der Erstellung dieses Artikels keine Lösung, welche die Bezeichnung "Enterprise" verdient - ein Armutszeugnis für eine Software mit “Enterprise” im Namen, die schnell hunderttausende Dollar pro Jahr an Subscription-Gebühren kostet.
Warum ist das ein Problem?
Stellen Sie sich vor, Sie haben diese Modulstruktur in Produktion:
Production Infrastructure (deployed: 2024-09-01) ├── Root Module: production-env (v1.0.0) │ ├── Service Module: web-application (v2.1.0) │ │ ├── Base Module: oci-compute (v1.3.2) │ │ ├── Base Module: oci-loadbalancer (v2.0.1) │ │ └── Base Module: oci-networking (v1.5.7) │ └── Service Module: mysql-cluster (v1.8.3) │ ├── Base Module: oci-compute (v1.2.8) ← Different version! │ └── Base Module: oci-storage (v3.1.0)
Kritische Fragen ohne einfache Antworten, die wir bereits weiter oben im Text im Zusammenhang mit den Modul-SBOMs stellten:
-
Welche Version von oci-compute wird tatsächlich verwendet?
-
Warum nutzt mysql-cluster eine ältere Version von oci-compute?
-
Wie wirkt sich ein Update von oci-compute auf alle abhängigen Module aus?
-
Gibt es Sicherheitsupdates, die in einem der Module fehlen?
Real-World Impact: Der MySQL-Cluster-Vorfall
Ein konkretes Beispiel aus der Praxis: Ein Kunde hatte einen kritischen Sicherheitspatch für das oci-compute Basis-Modul implementiert, der eine Schwachstelle in der Metadata-Service-Konfiguration behob. Das Update wurde nur im web-application Service-Modul eingespielt, während das mysql-cluster Service-Modul weiterhin die alte, verwundbare Version referenzierte.
Das Ergebnis? Ein Penetrationstest drei Monate später deckte die Sicherheitslücke in den Datenbankservern auf - eine Lücke, die das Team bereits "gepatcht" glaubte.
Im nächsten Kapitel werden wir uns deshalb passende Lösungsansätze für die Versionsverfolgung von Terraform-Modulen ansehen.
