











In Part 1 of our series, we learned about the basic concepts of Retrieval-Augmented Generation (RAG) and saw how this framework functions similar to a digital library. We examined the three main components - Retriever, Ranker, and Generator - in detail and understood how they work together to generate precise and contextually relevant answers.
In this second part, we delve deeper into the technical aspects of RAG. We will look at how RAG is implemented in practice, what different model types exist, and how RAG-enhanced systems differ from traditional Large Language Models (LLMs).
The Two RAG Model Types: Sequence and Token
There are two fundamental approaches when implementing RAG: RAG-Sequence and RAG-Token. Each of these approaches has its specific strengths and is suitable for different use cases.
RAG-Sequence: The Holistic Approach
RAG-Sequence works like a careful author who first studies all relevant sources and then writes a coherent text. The mathematical elegance of this approach lies in its holistic perspective:
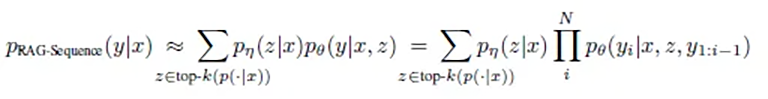
Or simplified: p(answer | question) = sum over all documents( p(document | question) × p(answer | question, document) )
In simple terms, this means:
- The system calculates two values for each potentially relevant document:
- How likely is it that this document is relevant to the question?
- How likely is it that this document leads to the correct answer?
- These probabilities are multiplied and summed across all documents to find the best answer.
The technical process proceeds as follows:
- The system selects the top-K most relevant documents for the query from an index of millions of documents
- The Generator creates a complete potential answer for each of these documents
- These answers are merged based on their calculated probability
Research shows that this approach is particularly effective when it comes to creating coherent, well-structured answers. An interesting detail from the studies: The quality of answers continuously improves as more relevant documents are included.
Research results show that RAG-Sequence performs particularly well on tasks requiring consistent and coherent output. The answers are typically more diverse and nuanced than with other approaches.
This approach is particularly suitable for:
- Summarizing longer texts
- Creating reports
- Answering complex questions that require comprehensive understanding
- Tasks requiring thematic consistency throughout the entire text
RAG-Token: The Granular Approach
RAG-Token works like a conscientious journalist who consults the best possible source for every single sentence and word of their story. The mathematical formulation of this approach reflects this thoroughness:
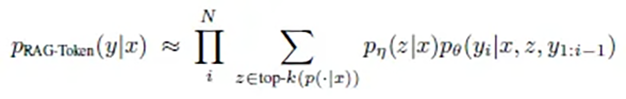
p(answer | question) = product for each word( sum over all documents( p(document | question) × p(word | question, document, previous words) ) )
In practice, this means:
- For each individual word of the answer:
- The most relevant documents are re-evaluated
- The probability for each possible next word is calculated
- The most probable word is chosen based on all available information
- This process repeats word by word, where each new word is influenced by:
- The words written so far
- The original question
- The currently most relevant documents
Research has shown that this approach delivers particularly precise results when it comes to factual accuracy. Interestingly, there is an optimal "sweet spot" in the number of documents considered: About 10 documents per token deliver the best results. More documents don't necessarily lead to better answers but can significantly increase processing time.
Studies have shown that RAG-Token is particularly effective for tasks requiring detailed, fact-based answers. The optimal number of retrieved documents, corresponding to the sweet spot, is typically around 10 documents - as more documents don't necessarily improve results but intensify costs.
This approach is optimal for:
- Detailed technical explanations
- Fact-based answers
- Situations requiring highly specific information
- Cases where different parts of the answer require different sources
The Technical Implementation: The RAG Pipeline
The practical implementation of a RAG system occurs in three main phases: Ingestion, Retrieval, and Generation. Each of these phases plays a crucial role in the quality of the final results.
1. The Ingestion Phase
In this first phase, documents are fed into the system and prepared for later use. The original RAG implementation used a Wikipedia dump with 21 million documents, each split into 100-word chunks. The process proceeds as follows:
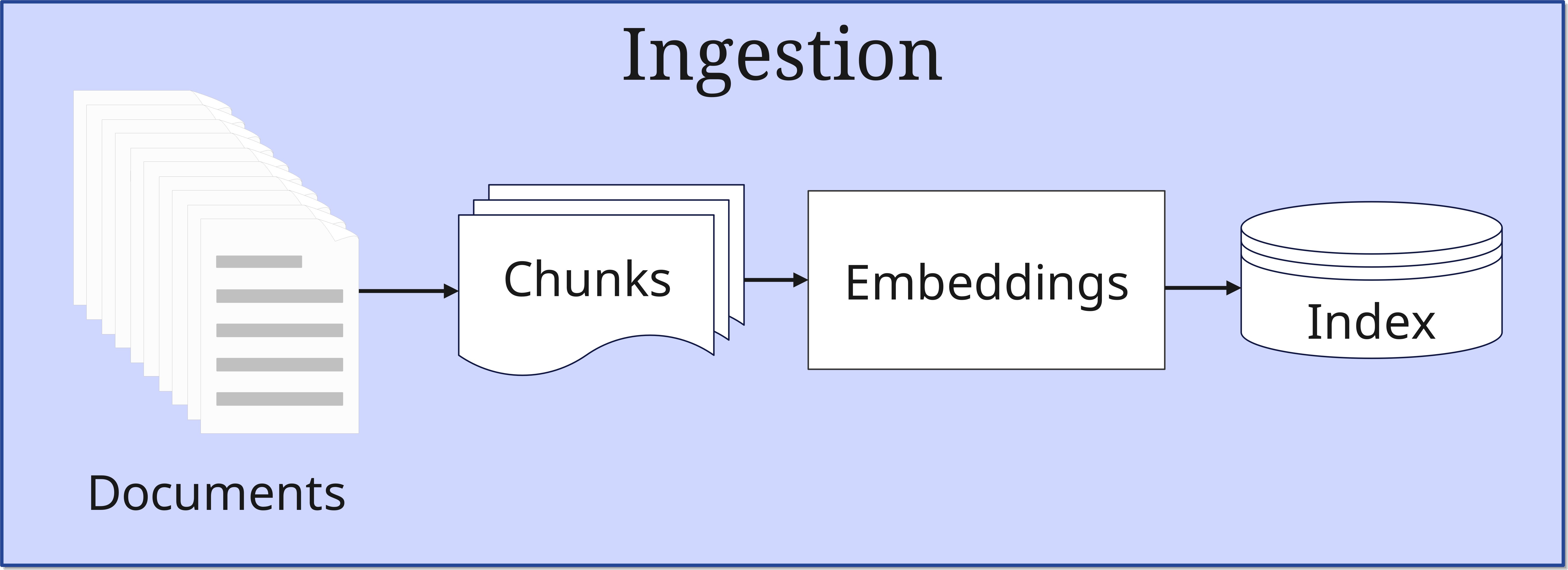
- Document Preparation:
- Documents are split into smaller, manageable pieces (chunks)
- The chunk size is optimized based on the use case
- Embedding Generation:
- Each chunk is converted into a mathematical, multidimensional vector by a BERT-based document encoder (typically up to 1024-dimensional)
- These vectors capture the semantics of the text, meaning not the wording but the meaning (we'll learn more about vectors in a future article about vector databases)
- Indexing:
- The embeddings are stored in a vector database
- A MIPS index (Maximum Inner Product Search) is created for efficient search
- Technologies like FAISS enable fast, approximate search in sublinear time
This process is crucial for the system's later efficiency. The art lies in splitting the documents so that coherent information isn't torn apart, while keeping the chunks small enough to deliver precise results.
2. The Retrieval Phase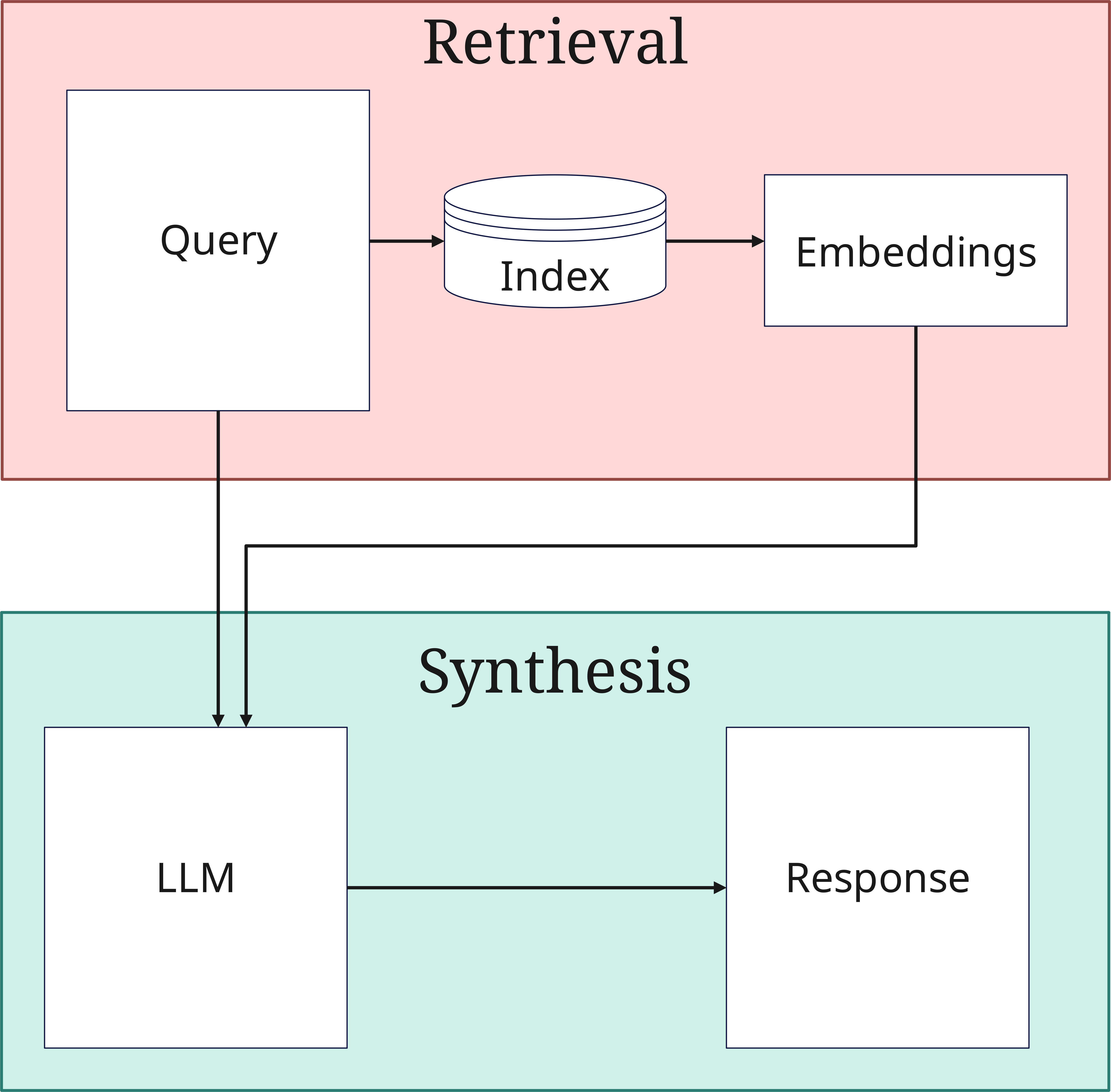
When a query arrives, the retrieval phase begins:
- Query Processing: The query is also converted into a vector. This query is both stored in the vector database by the Retriever and sent directly in its original form to the Generator for answer synthesis
- Similarity Search: The system searches the vector database (Index) for documents similar to those transmitted to the database. Here, the query vectors are compared with those of the indexed documents
- Top-K Selection: The most relevant documents are selected
The number of selected documents (Top-K) is an important parameter that influences the balance between completeness and processing efficiency.
3. The Generation Phase
In the final phase, the found information is processed into an answer:
- Context Integration: The selected Top-K documents are combined with the original query
- Answer Generation: The LLM creates a coherent answer
- Quality Assurance: The answer is checked for consistency and relevance before being output
A Comprehensible Example
Step 1: Creating a Prompt (Query)
Imagine an employee approaching your desk and asking you a question:
"We had a project idea. We want to do xyz. What are the legal guidelines for this?"
This inquiry is a prompt.
Now put yourself in the position of artificial intelligence. The question is clear and direct. But to answer it, you need more context. So you search through all your memory of previous conversations with this employee and thus establish a better reference to the topic, which will lead to a better and more comprehensive understanding of the question.
All the information found is the context. The prompt is now expanded with the context - the historical information is, so to speak, attached to the employee's actual question. The prompt now becomes what is known as an Enhanced Prompt.
As a supervisor, you also consider how exactly the project idea benefits your company. So you think about it some more, maybe ask again, and further supplement the Enhanced Prompt with the insights found. Gradually, the Query is thus completed.
Step 2: Embedding
In the next step, you feed your query into an Embedding Model, which converts it into a 1024-dimensional vector. So not just three-dimensional, but a really unimaginable value for normal people. Through these 1024 dimensions, it is then possible to capture the meaning of the Query fairly accurately. So not the individual words, but the meaning. The Embedding Model now stores this vector in the vector database.
Now the vector database performs a similarity search to the vector of the Query. Found similarity of a document means that it is bookmarked. At the end of the search, the best results are then selected and the corresponding documents, database entries, etc. are referenced.
These found documents and other information are now attached to the Query. Think of it as if you were attaching documents to an already formulated email. This transforms the Enhanced Prompt into an Augmented Prompt.
Step 3: Generating an Answer
This Augmented Prompt now goes together with the original Query to the Generator, more specifically the involved LLM. The LLM now synthesizes an answer from the original query and all the additional information found. This Response then goes back to the employee who is hopefully satisfied with the content.
The RAG Triad: Evaluating Quality
Even though an LLM through RAG has access to the most current information in the information pool and can give very accurate answers, this does not eliminate the risk of hallucinations. There are several reasons for this:
- The Retriever simply doesn't gather enough context (quantitatively), or it gathers wrong information (qualitatively).
- Perhaps the answer isn't fully supported by the gathered context but was too heavily influenced by the LLM and the training data.
- A RAG might gather the relevant information and build a fundamentally correct answer from it, but then the answer might not fit the actual question.
To avoid this, the RAG Triad was developed.
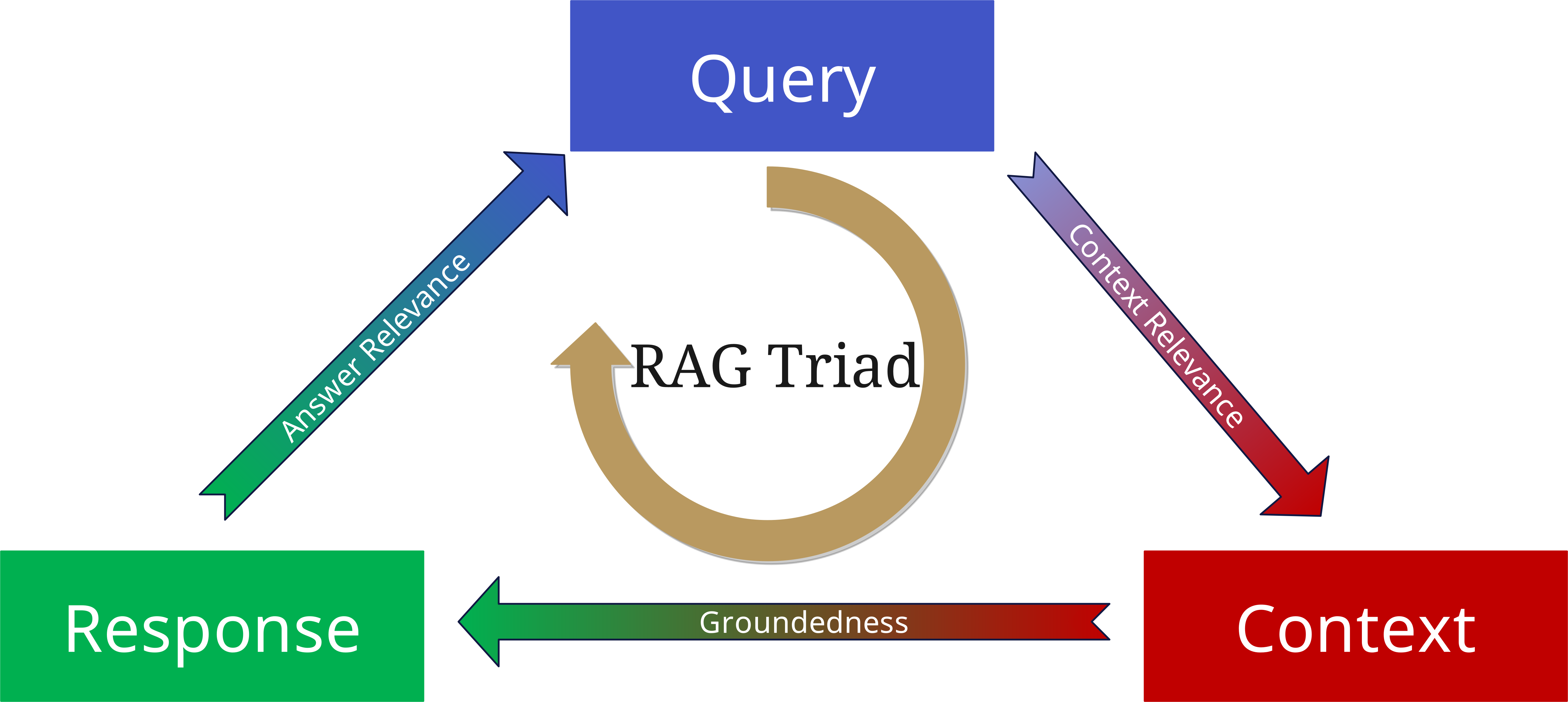
To evaluate the quality of a RAG system, we consider three central aspects:
1. Context Relevance
- How well do the retrieved documents match the query?
- Was the right context found?
- Is the information current and appropriate?
2. Groundedness
- Is the answer actually based on the retrieved documents?
- Are statements supported by the sources?
- Are there hallucinations or unfounded conclusions?
3. Answer Relevance
- Does the generated answer address the original question?
- Is the answer complete and precise?
- Is the depth of information appropriate?
When applying these three aspects again as parameters to the query, context, and generated answer, one can minimize hallucinations and build more reliable and robust RAG-based applications.
LLMs with and without RAG: A Comparison
Traditional LLMs and RAG-enhanced systems fundamentally differ in their way of working:
Traditional LLMs
- Are based exclusively on pre-trained knowledge
- Cannot access new or specific information
- Are more susceptible to hallucinations
- Have a "frozen" state of knowledge
RAG-enhanced Systems
- Combine pre-trained knowledge with external sources
- Can access current and specific information
- Deliver traceable, source-based answers
- Are flexibly expandable
These differences make RAG an ideal solution for enterprise applications where precision, currency, and traceability are crucial.
