











Quand une simple mise à jour de module paralyse 47 équipes...
Nous sommes lundi matin, 10h30. L’équipe de Platform Engineering d’un grand fournisseur de Managed Cloud Services vient de publier une mise à jour « inoffensive » du module de base pour les instances VM, passant de la version v1.3.2 à la v1.4.0. Le changement ? Un nouveau tag Freeform obligatoire pour l’affectation des ressources à des centres de coûts.
Ce que personne n’a anticipé : l’ingénieur senior qui, autrefois en tant que décideur, avait insisté avec véhémence pour déposer tous les modules Terraform dans un seul dépôt Git. « La gestion de versions, c’est trop de micro-management. Comme ça, c’est plus ordonné. Et cela demande moins de travail », avait-il dit à l’époque.
Le même lundi, à 15h00 : 47 équipes de clients différents signalent déjà que leurs pipelines CI/CD échouent. La raison ? Leurs root-modules référencent les modules mis à jour par le fournisseur, mais personne n’a implémenté les nouveaux paramètres dans ses propres root-modules. Le contrôle de conformité du fournisseur est actif et rejette les exécutions Terraform en raison des tags obligatoires manquants. Ce qui devait être une amélioration s’est transformé en un arrêt organisationnel complet avec un impact massif sur les clients d’hébergement.
Bienvenue dans le monde des dépendances entre modules avec Terraform @ Scale.
La complexité cachée des modules imbriqués
Les modules Terraform sont l’épine dorsale de toute mise en œuvre d’Infrastructure-as-Code à l’échelle. Ils favorisent la réutilisabilité, encapsulent les bonnes pratiques et réduisent la duplication. Mais plus la profondeur de la hiérarchie augmente, plus une complexité cachée apparaît, pouvant surprendre même les équipes expérimentées.
L’effet domino : pourquoi la profondeur des modules devient un piège
Le problème peut être illustré par un exemple simple : imaginons une hiérarchie de modules à quatre niveaux, comme on en trouve souvent dans les grandes organisations. Commençons tout en haut, avec un seul root-module :
![]()
Ce module appelle d’autres modules :
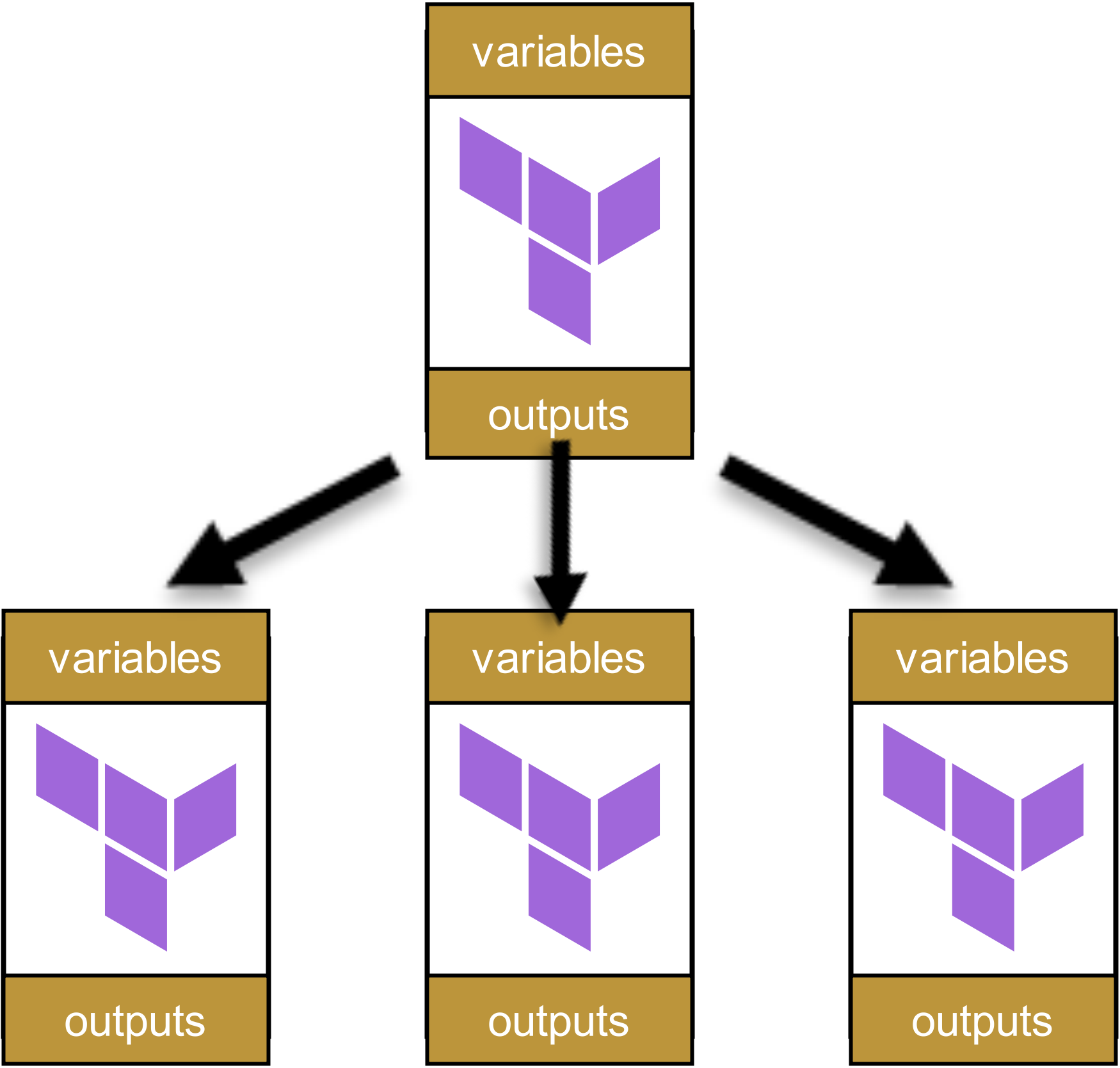
Ces modules appellent eux-mêmes d’autres modules, qui à leur tour appellent encore d’autres modules. Il en résulte un arbre de dépendances, ressemblant à ceci :
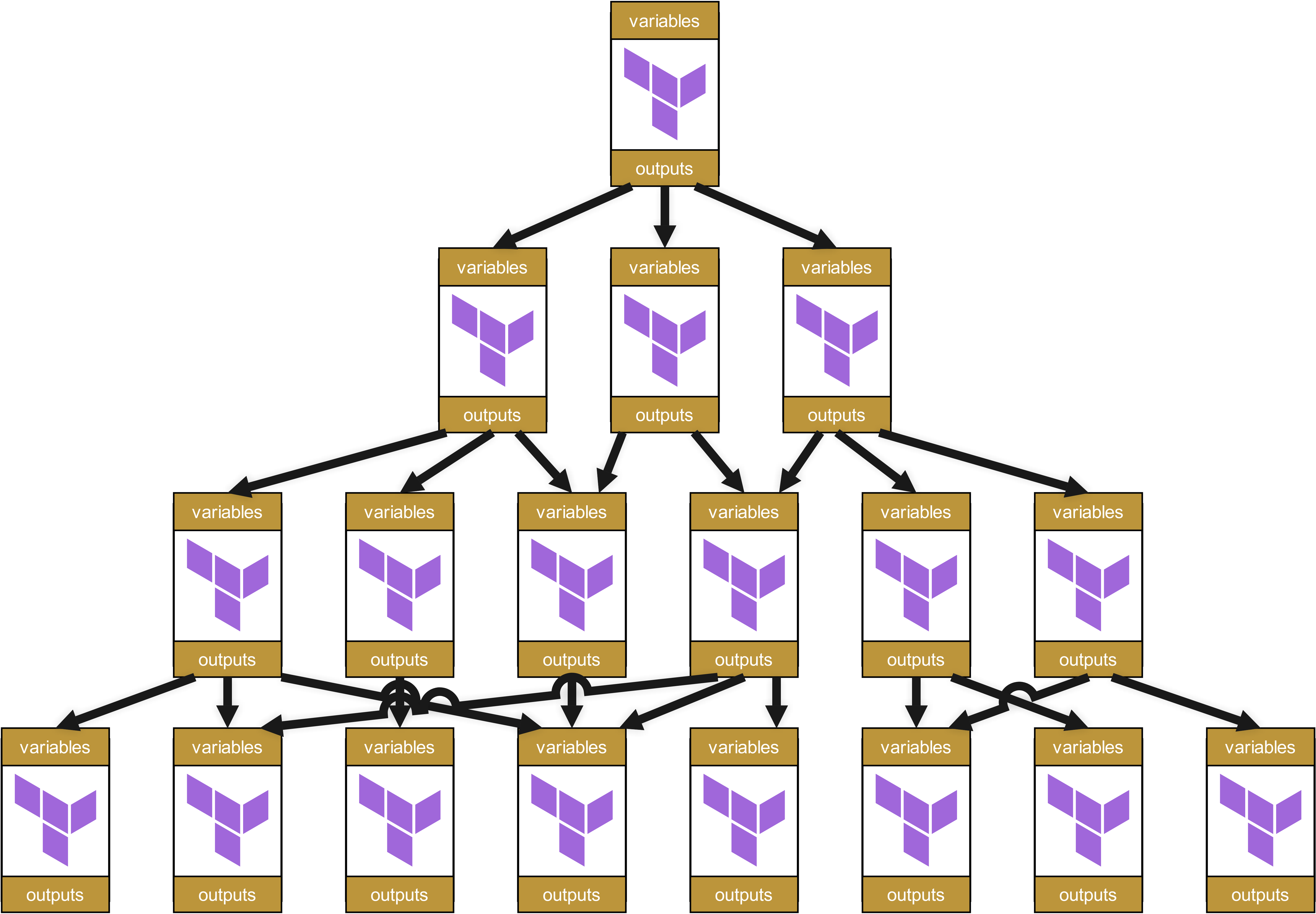
À première vue, cette structure semble propre et bien organisée. Chaque module a des variables et outputs clairement définis, transmis proprement entre les niveaux.
Cela paraît bien, n’est-ce pas ? Eh bien…
Amusez-vous à déboguer et corriger quand un problème survient.
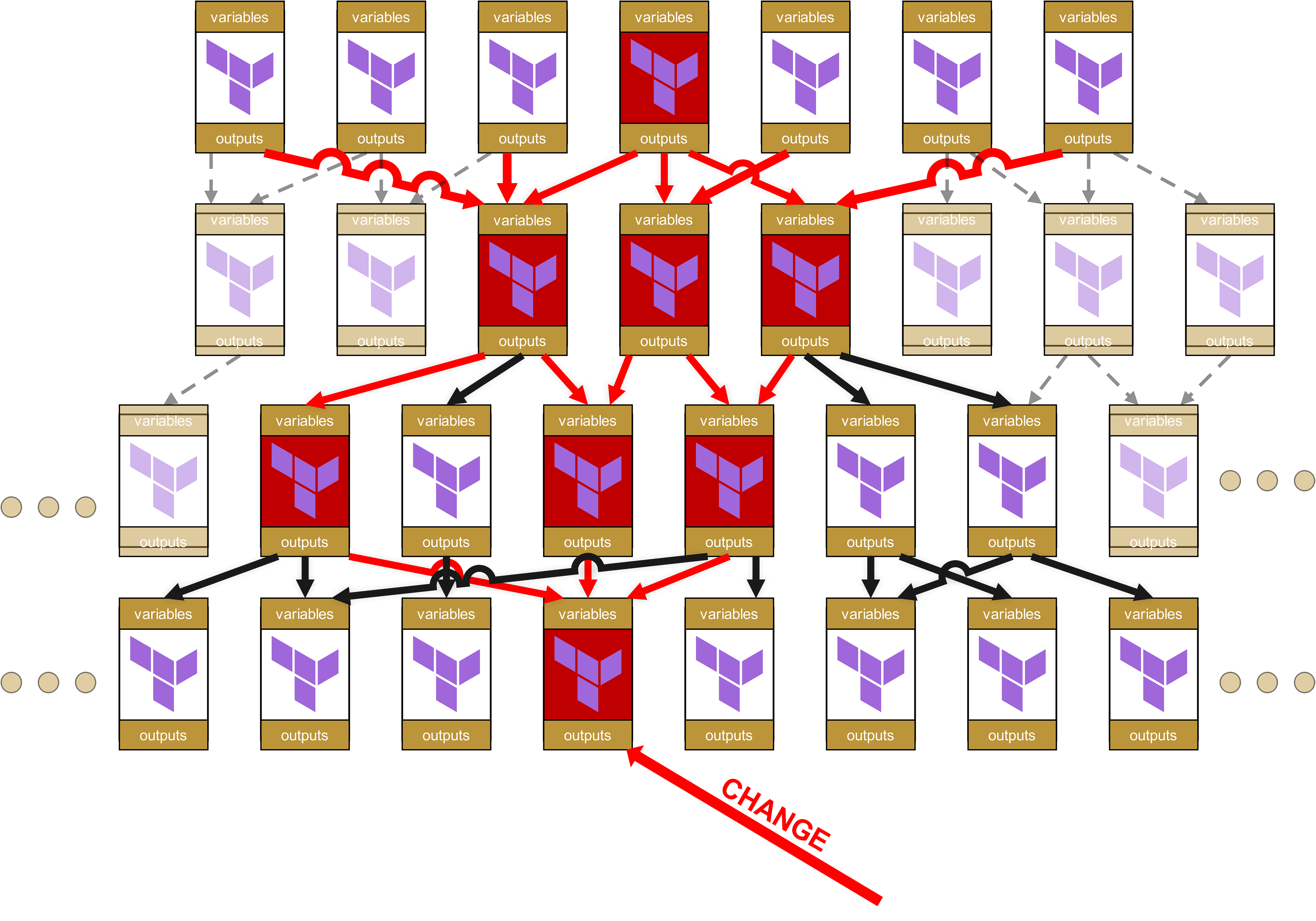
Car plus une modification se situe bas dans la hiérarchie, plus grand sera l’« effet domino » jusqu’au sommet. Réfléchissez : que se passe-t-il si, dans un module de base tout en bas, on modifie du code, par exemple en ajoutant un paramètre obligatoire, en changeant un nom d’output ou en modifiant une règle de validation ? Que se passe-t-il alors ?
Imaginons donc qu’au niveau le plus bas un changement intervienne dans un module.
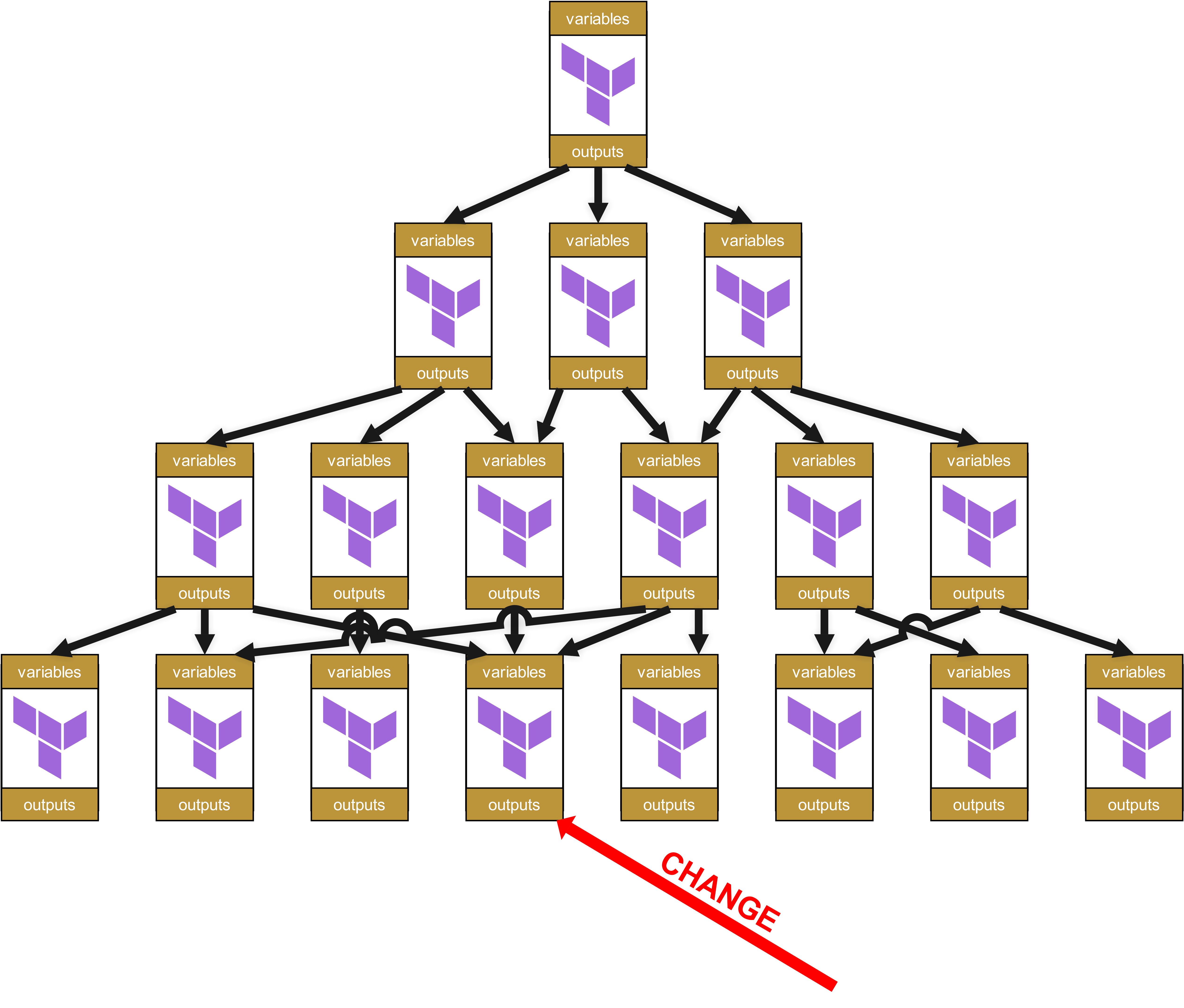
Au niveau organisationnel, il faut alors remonter tout l’arbre jusqu’à la racine, avec des Change Requests pour tous les modules dépendants et les infrastructures dans lesquelles ces modules dépendants sont utilisés.
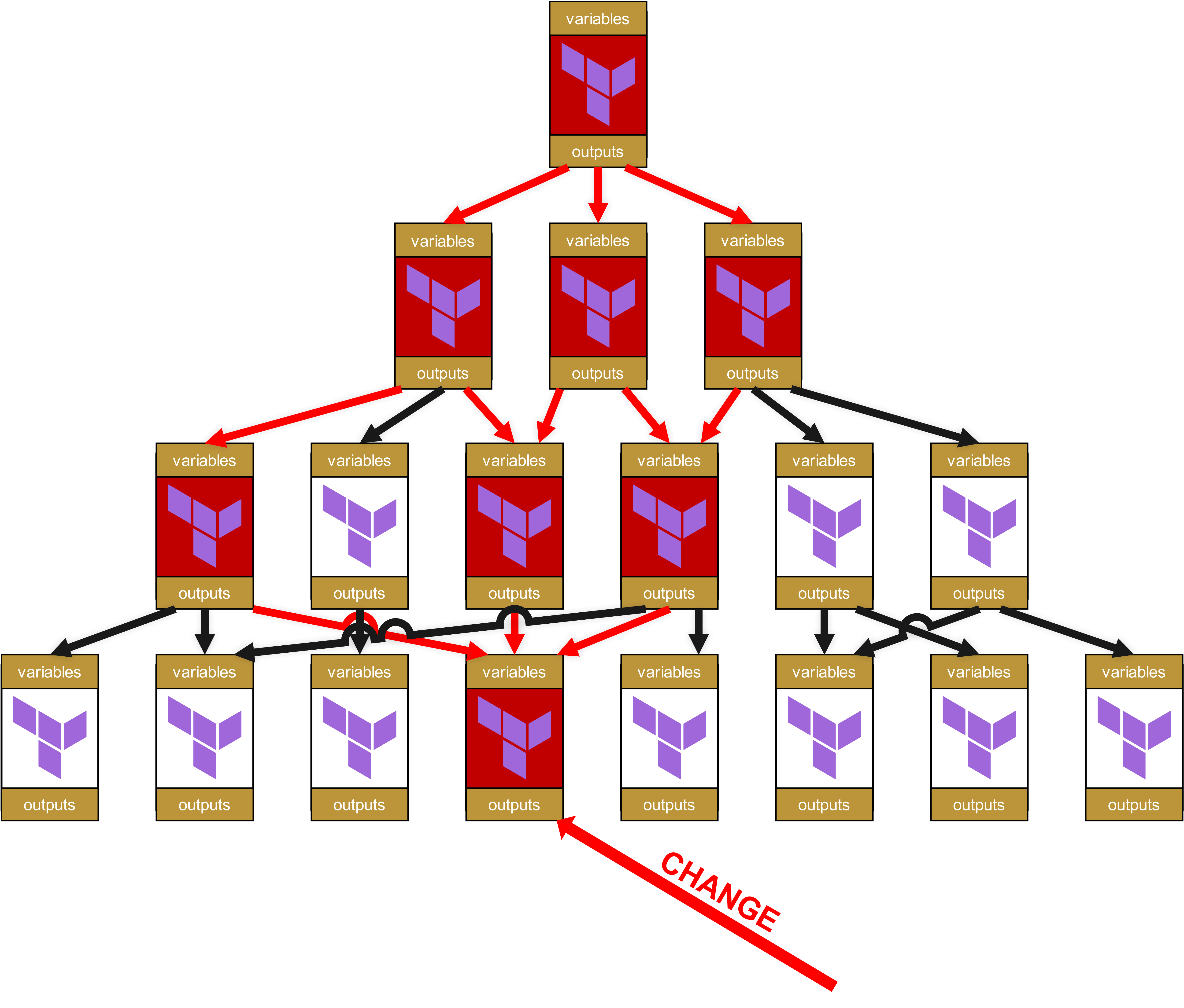
Oh là, un joli potentiel de réjouissance se profile déjà. Car vous avez bien lu : il n’y a pas seulement des impacts jusqu’au sommet, mais la petite modification dans le module tout en bas fait que tous les modules marqués en rouge doivent repasser par la pipeline de tests. Et mieux encore, puisque j’ai déjà parlé de « Change Request » : pour chaque infrastructure dans laquelle un module marqué en rouge est utilisé directement ou même indirectement via des dépendances (flèches rouges), une Change Request complète est nécessaire. Cela signifie également qu’il faut informer d’autres équipes ou même des clients, afin qu’ils testent eux-mêmes leurs propres infrastructures.
À cela s’ajoute, sur le plan technique, qu’une quantité absurde d’overhead s’accumule rapidement. Car chacun de ces modules a ses propres variables et ses propres outputs, qu’il faut transmettre de haut en bas et inversement. La structure du State-File devient de plus en plus cauchemardesque et peu conviviale pour le client, avec des chemins du type module.<resource>.module.<resource>.module.<resource>.... Ce n’est pas seulement inesthétique, mais aussi opérationnellement problématique, car de tels chemins trop longs compliquent fortement le dépannage manuel du State.
Et nous avions simplifié la situation, car nous n’avons parlé que d’un seul root-module. En pratique, chaque équipe et chaque client en possède au moins un, probablement même plusieurs :
À un moment donné, pour le client, il devient plus coûteux en termes de code d’utiliser et de gérer un module que de créer directement les ressources lui-même.
Et ce qui se passe ensuite est évident :
-
D’abord, on réinvente la roue,
-
puis on voit apparaître de la shadow-IT,
-
ensuite, le chaos opérationnel. Et cela conduit finalement à
-
un problème critique pour l’entreprise.
L’alternative : organisation plate des modules
C’est pourquoi les hiérarchies de modules doivent être maintenues aussi plates que possible. Une organisation des modules analogue aux Value Streams est donc logique – une organisation hiérarchique de l’infrastructure est à éviter dans la plupart des cas.
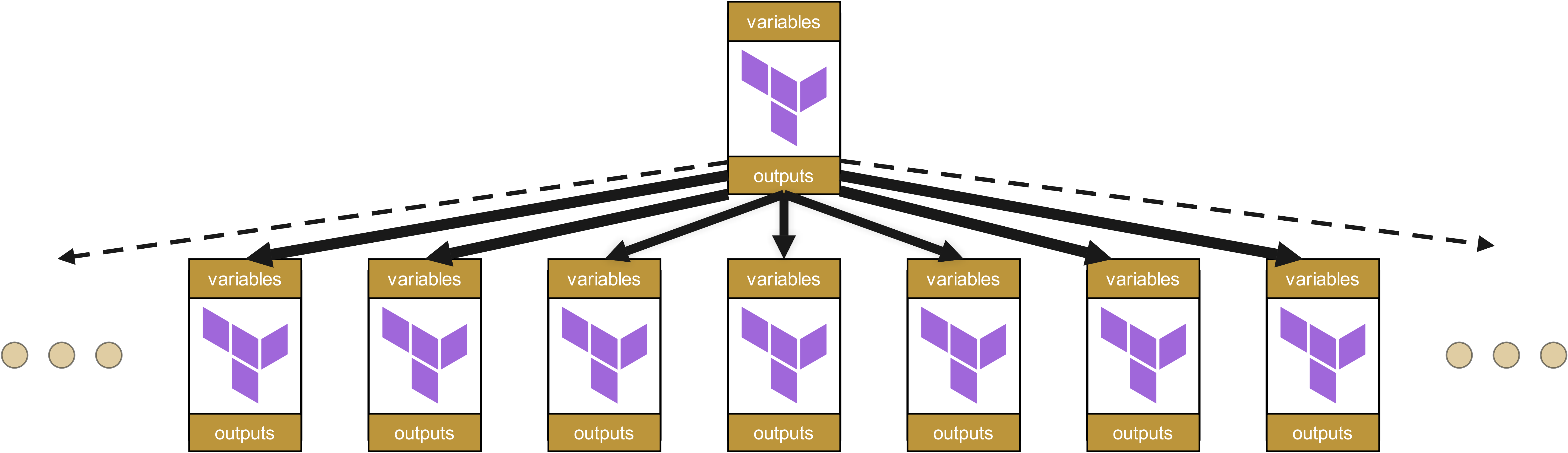
Dans des structures plates, les changements n’affectent que les modules directement dépendants, et non pas toute une cascade de dépendances. Cela réduit considérablement la charge de maintenance ainsi que le risque d’effets secondaires inattendus.
Mais ici aussi, la beauté de l’idée n’existe qu’au premier regard.
Le pendule va trop loin : pourquoi des structures totalement plates échouent
Avant de tirer tous vos modules vers un seul niveau, vous devriez marquer une pause. Car l’autre extrême, celui des organisations totalement plates, entraîne ses propres problèmes, tout aussi graves.
Sans une certaine structure hiérarchique, apparaît rapidement ce que nous appelons « Infrastructure-as-Copy&Paste ». Les équipes commencent à développer des modules presque identiques pour des besoins légèrement différents, au lieu d’utiliser les abstractions existantes. Ce qui avait commencé comme un module réutilisable oci-compute-module se fragmente en oci-compute-web, oci-compute-api, oci-compute-batch et des dizaines d’autres variantes. Combien exactement ? Vous ne le saurez jamais sans demander à vos clients. Et toutes ces mutations de modules indéfinies partagent à >80 % le même code, mais possèdent néanmoins chacune leurs subtiles différences, rendant toute consolidation ultérieure extrêmement difficile.
Le résultat ? Des cauchemars de maintenance par excellence.
Une mise à jour de sécurité doit désormais être intégrée dans une multitude de « Compute-Modules » différents, au lieu d’un module central de base. Les correctifs sont donc généralement implémentés de manière incohérente. Les standards dérivent. Le principe DRY (Don’t Repeat Yourself) devient la risée générale, tandis que les développeurs réinventent la roue dans d’innombrables variantes. La conformité s’effondre, et avec un certain retard, la certification de sécurité de votre entreprise finit par suivre le même chemin.
Particulièrement perfide : les incompatibilités restent souvent inaperçues pendant des mois, voire des années, jusqu’à ce qu’une mise à jour de conformité à l’échelle de l’entreprise soit nécessaire. Ou lors de la migration d’un client d’un Cloud Provider vers un autre. C’est alors que l’on découvre que des modules supposément « identiques » diffèrent sur des points critiques. Et un déploiement Blue/Green apparemment simple devient alors un projet mammouth.
Le modèle à trois couches : à la fois bénédiction et malédiction
Dans nos articles précédents, nous avons déjà présenté le modèle éprouvé à trois couches. Résumons-le brièvement :
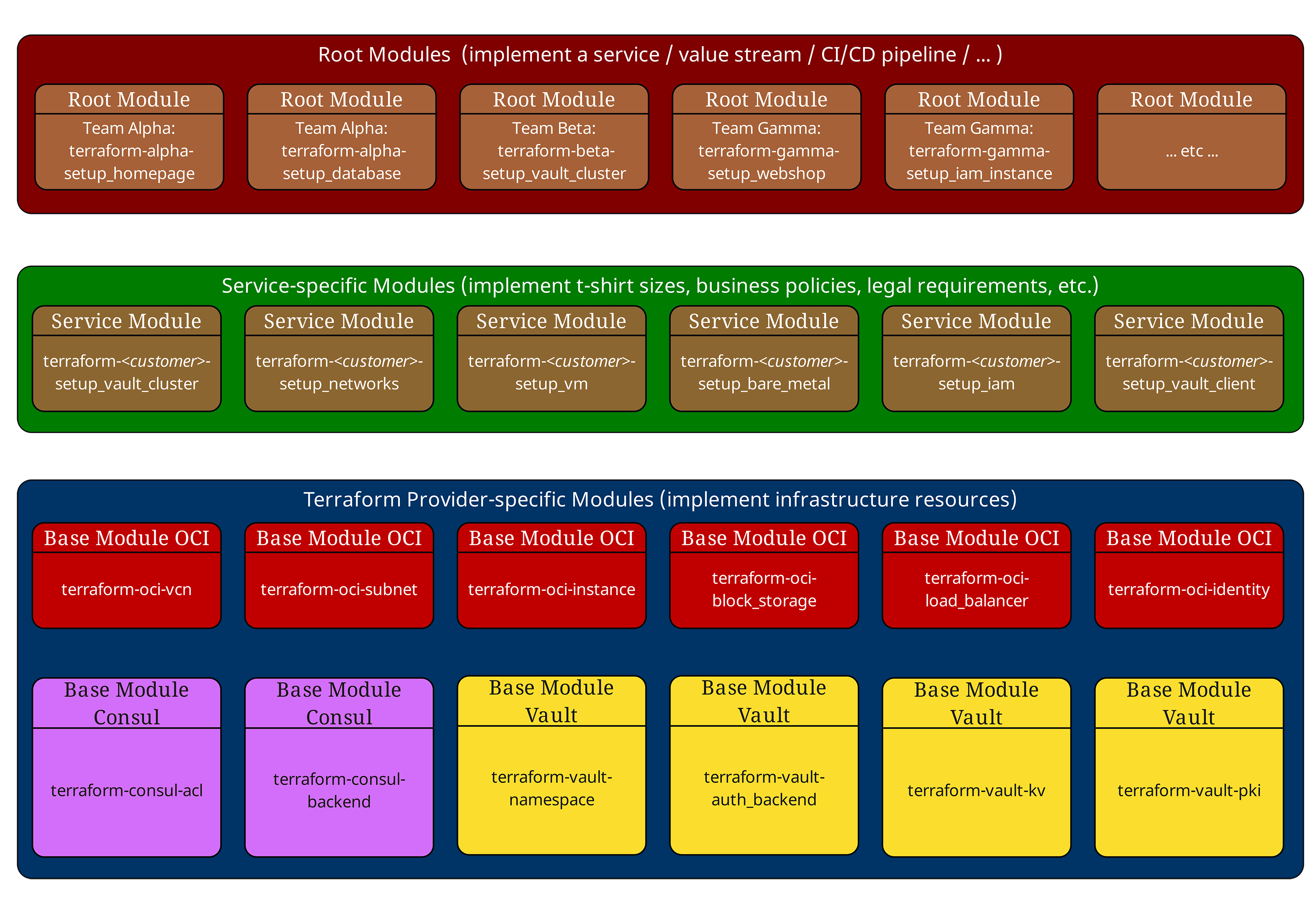
Root-Modules (En haut, rouge) orchestrent l’ensemble de l’infrastructure d’un environnement. Ils définissent les configurations des Providers, les paramètres Backend et appellent les Service-Modules.
Service-Modules (Au milieu, vert) implémentent les standards de l’entreprise et les « tailles T-Shirt ». Ils ne contiennent aucune déclaration de ressource directe, mais combinent et configurent uniquement des Base-Modules. Les Service-Modules ne contiennent volontairement ni configurations de Provider ni paramètres Backend et ne doivent pas avoir d’effets secondaires dépendants du Provider. Ils restent ainsi réutilisables dans différents contextes Root.
Base-Modules (En bas, bleu) dialoguent directement avec les Cloud Providers et implémentent des composants d’infrastructure atomiques tels que les VM, réseaux ou bases de données.
Cette structure fonctionne à merveille - jusqu’à ce que les dépendances deviennent vraiment complexes. Et alors, la bénédiction se transforme facilement en malédiction.
Exemple d’une hiérarchie de modules typique
Considérons une structure de modules réelle issue d’un projet client :
# Root Module - Production Environment
module "web_application" {
source = "git::https://gitlab.ict.technology/modules//services/web-application?ref=v2.1.0"
environment = "production"
instance_size = "large"
high_availability = true
region = "eu-frankfurt-1"
}
module "database_cluster" {
source = "git::https://gitlab.ict.technology/modules//services/mysql-cluster?ref=v1.8.3"
environment = "production"
storage_tier = "premium"
backup_enabled = true
}
Le Service-Module web-application ressemble en interne à ceci :
# Service Module - services/web-application/main.tf
locals {
instance_configs = {
small = { ocpus = 2, memory_gb = 8, storage_gb = 50 }
medium = { ocpus = 4, memory_gb = 16, storage_gb = 100 }
large = { ocpus = 8, memory_gb = 32, storage_gb = 200 }
}
config = local.instance_configs[var.instance_size]
}
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.3.2"
instance_count = var.high_availability ? 3 : 1
shape_config = {
ocpus = local.config.ocpus
memory_in_gbs = local.config.memory_gb
}
compartment_id = var.compartment_id
}
module "load_balancer" {
source = "git::https://gitlab.ict.technology/modules//base/oci-loadbalancer?ref=v2.0.1"
backend_instances = module.compute_instances.instance_ids
compartment_id = var.compartment_id
}
module "networking" {
source = "git::https://gitlab.ict.technology/modules//base/oci-networking?ref=v1.5.7"
vcn_cidr = var.environment == "production" ? "10.0.0.0/16" : "10.1.0.0/16"
availability_domains = var.high_availability ? 3 : 1
compartment_id = var.compartment_id
}
Dès ici, nous voyons apparaître le premier problème : dépendances transitives. Le Root-Module ne « voit » que les Service-Modules qu’il appelle. Il ne « sait » pas quels Base-Modules sont réellement utilisés ni dans quelles versions.
Et devinez pour quoi Terraform n’offre aucun support natif : la gestion de ces dépendances transitives. Dans notre Dependency Tree ci-dessus, vous n’avez aucun moyen avec les outils intégrés de Terraform de déterminer quelles dépendances deviennent marquées en rouge et pour lesquelles vous devez déposer des Change Requests.
Tout ce que Terraform vous fournit ici, c’est une implémentation insuffisante de la sortie d’un graphe de dépendances de haut en bas, mais pas de bas en haut - terraform graph. Et dès que des Remote States entrent en jeu, même cela ne fonctionne plus, car terraform graph ne peut gérer qu’un seul Statefile.
Des contournements et des approches exploitables avec des outils externes sont possibles, mais ils sont loin d’être directs – et ironiquement, ils sont souvent difficiles à intégrer précisément lorsque vous utilisez Terraform Enterprise :
-
Scan statique des modules avec terraform-config-inspect ou analyse HCL simple dans la CI afin d’extraire une liste de toutes les références dans les URLs des sources de modules avec leurs versions. Cette liste peut être publiée comme artefact à chaque commit.
-
Policies dans Sentinel/Conftest/OPA ou Checkov/TFLint, qui interdisent de référencer des modules sans ref fixe, détectent les versions mélangées par environnement et permettent, par exemple, uniquement des « patch-upgrades » pendant les fenêtres de maintenance.
-
Générer un petit « Module SBOM » interne pour chaque Root-Run et le versionner. Cela suppose à son tour que chaque Service- et Base-Module dispose de son propre SBOM, mais vous répondez alors opérationnellement aux questions critiques :
-
Quelle version d’un module est réellement utilisée ?
-
Pourquoi un module utilise-t-il une version plus ancienne d’un autre module ?
-
Quel est l’impact de la mise à jour d’un module sur tous les modules dépendants ?
-
Y a-t-il des mises à jour de sécurité manquantes dans l’un des modules ?
-
Mais l’absence de gestion des dépendances dans Terraform n’est pas le plus gros problème. Le pire reste à venir.
Le problème du suivi des versions : la plus grande faiblesse de Terraform
L’un des aspects les plus frustrants de Terraform est l’absence totale d’un suivi natif des versions de modules. Alors que terraform version affiche la version du binaire Terraform, il n’existe aucune fonctionnalité intégrée pour quelque chose de ce genre :
# Ces commandes n’existent pas dans Terraform terraform modules list terraform modules version terraform dependencies show
Terraform Enterprise n’apporte pas non plus de solution digne de ce nom au moment de la rédaction de cet article – un constat affligeant pour un logiciel portant « Enterprise » dans son nom, et qui coûte rapidement des centaines de milliers de dollars par an en frais de souscription.
Pourquoi est-ce un problème ?
Imaginez que vous ayez cette structure de modules en production :
Production Infrastructure (deployed: 2024-09-01) ├── Root Module: production-env (v1.0.0) │ ├── Service Module: web-application (v2.1.0) │ │ ├── Base Module: oci-compute (v1.3.2) │ │ ├── Base Module: oci-loadbalancer (v2.0.1) │ │ └── Base Module: oci-networking (v1.5.7) │ └── Service Module: mysql-cluster (v1.8.3) │ ├── Base Module: oci-compute (v1.2.8) ← Different version! │ └── Base Module: oci-storage (v3.1.0)
Des questions critiques sans réponses simples, que nous avons déjà posées plus haut dans le texte à propos des SBOMs de modules :
-
Quelle version de oci-compute est réellement utilisée ?
-
Pourquoi mysql-cluster utilise-t-il une version plus ancienne de oci-compute ?
-
Quel est l’impact d’une mise à jour de oci-compute sur tous les modules dépendants ?
-
Y a-t-il des mises à jour de sécurité manquantes dans l’un des modules ?
Impact dans le monde réel : l’incident du cluster MySQL
Un exemple concret issu de la pratique : un client avait implémenté un patch de sécurité critique pour le Base-Module oci-compute, qui corrigeait une vulnérabilité dans la configuration du Metadata Service. La mise à jour avait été intégrée uniquement dans le Service-Module web-application, tandis que le Service-Module mysql-cluster continuait de référencer l’ancienne version vulnérable.
Résultat ? Un test de pénétration, trois mois plus tard, a révélé la faille de sécurité sur les serveurs de bases de données – une faille que l’équipe croyait déjà « corrigée ».
Dans le prochain chapitre, nous examinerons donc des approches adaptées pour le suivi des versions des modules Terraform.
