











Quando un singolo aggiornamento di un modulo blocca 47 team...
È lunedì mattina, ore 10:30. Il team di Platform Engineering di un grande fornitore di Managed Cloud Services ha appena rilasciato un "innocuo" aggiornamento del modulo di base per le istanze VM dalla versione v1.3.2 alla v1.4.0. La modifica? Un nuovo, ma obbligatorio Freeform-Tag per l’assegnazione dei costi alle risorse.
Ciò che nessuno aveva previsto: il Senior Engineer che un tempo, come decision maker, aveva insistito con forza affinché tutti i moduli Terraform venissero archiviati in un unico repository Git. “La versioning è troppo micromanagement. Così è più ordinato. E richiede meno lavoro”, aveva detto allora.
Lo stesso lunedì, ore 15:00: 47 team di clienti diversi segnalano che le loro pipeline CI/CD falliscono. Il motivo? I loro Root-Module fanno riferimento ai moduli aggiornati forniti dal provider, ma nessuno ha implementato i nuovi parametri nei propri Root-Module. Il controllo di conformità del provider è attivo e respinge i Terraform-Runs a causa dei tag obbligatori mancanti. Ciò che era stato pianificato come un miglioramento si è trasformato in un blocco organizzativo su larga scala con un impatto esterno massiccio sui clienti di hosting.
Benvenuti nel mondo delle dipendenze tra moduli in Terraform @ Scale.
La complessità nascosta dei moduli annidati
I moduli Terraform sono la spina dorsale di ogni implementazione Infrastructure-as-Code scalabile. Promuovono il riuso, incapsulano le best practice e riducono la duplicazione. Tuttavia, con l’aumentare della profondità dei moduli nasce una complessità nascosta che può sorprendere anche i team più esperti.
L’effetto domino: perché la profondità dei moduli diventa una trappola
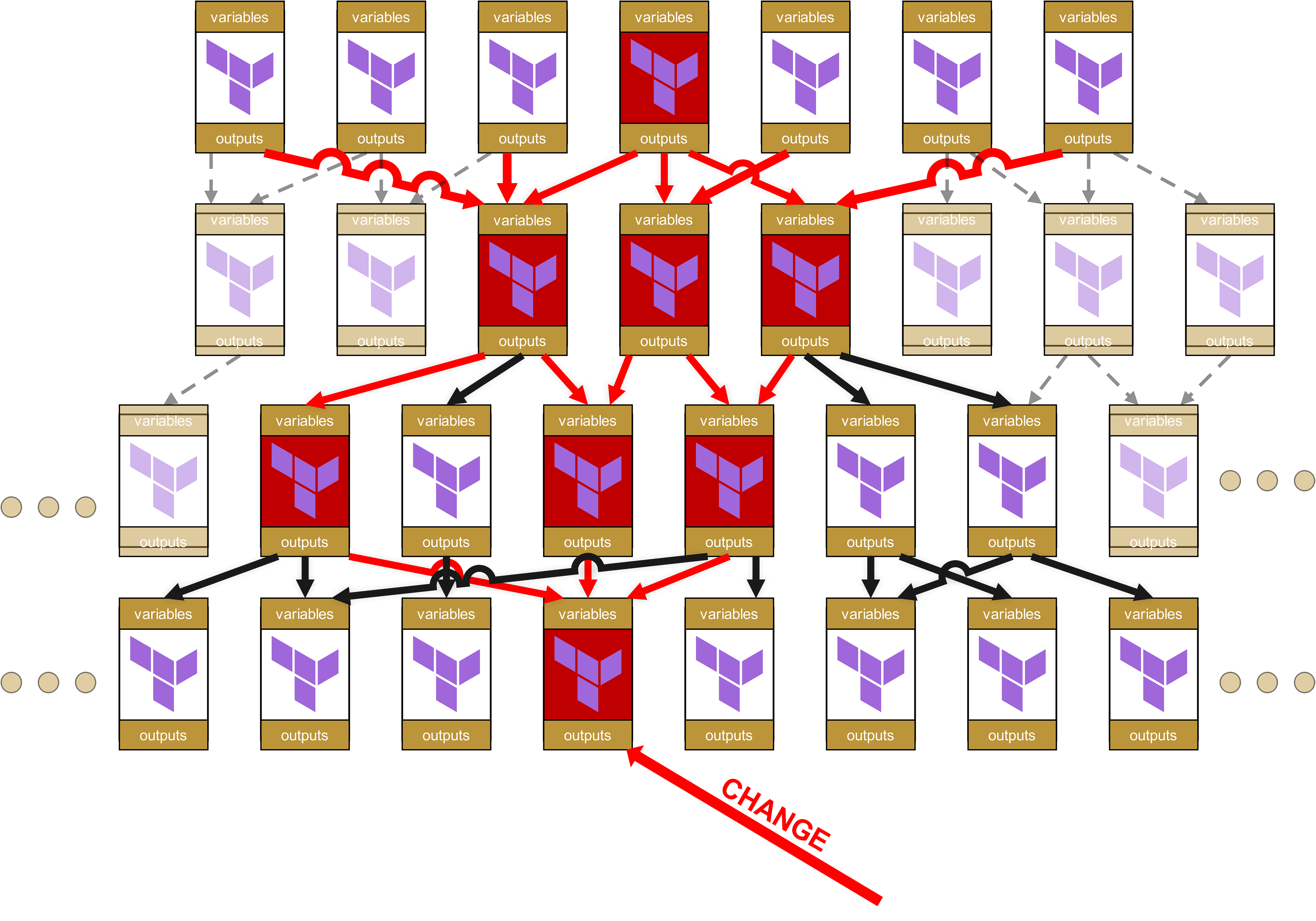
Il problema può essere illustrato con un semplice esempio: immaginiamo una gerarchia di moduli a quattro livelli, come spesso si riscontra nelle grandi organizzazioni. Partiamo dall’alto, con un singolo Root-Modul:
![]()
Questo modulo richiama altri moduli:
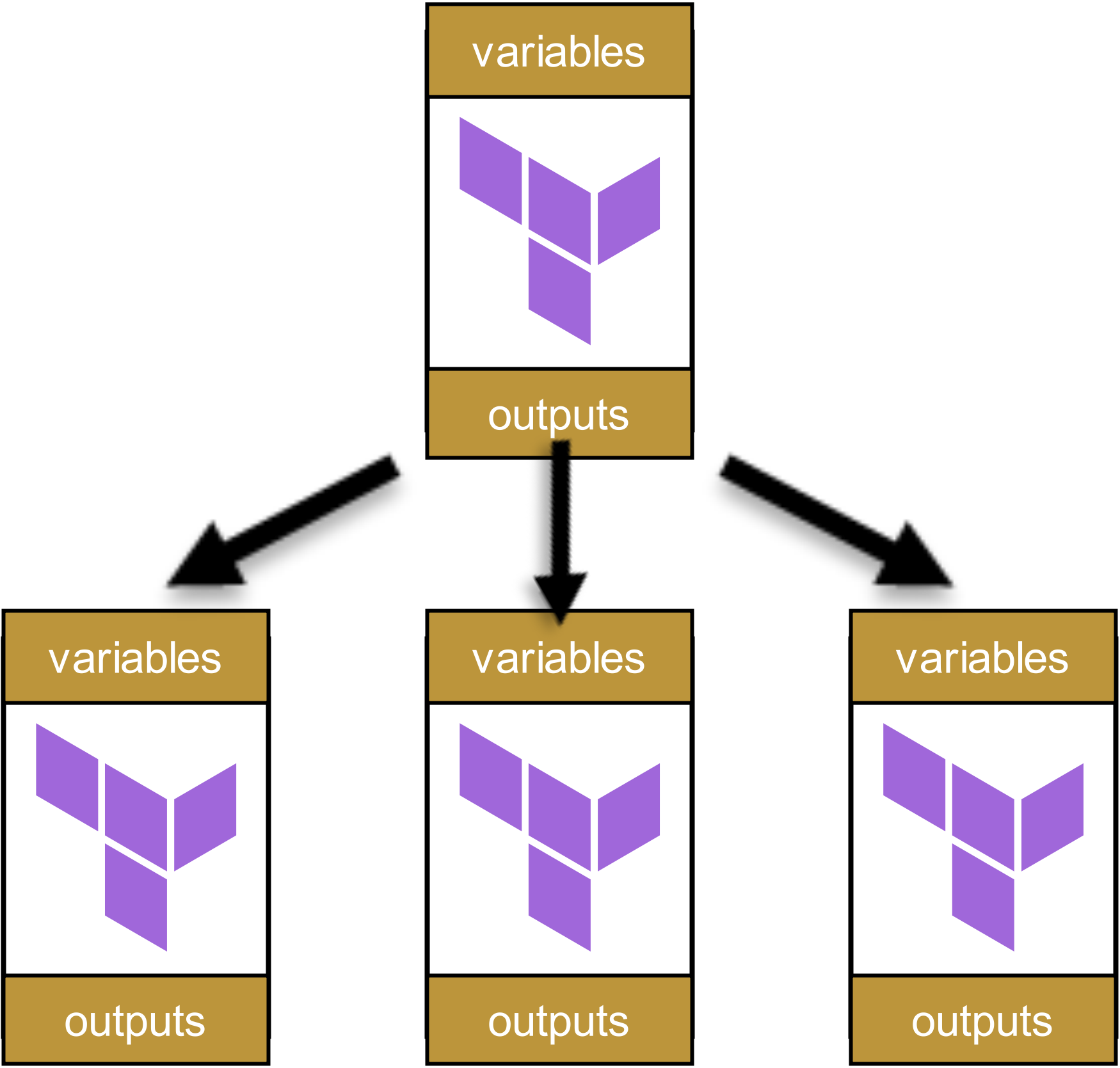
Questi a loro volta richiamano altri moduli, che a loro volta richiamano ulteriori moduli. Si crea così un Dependency Tree, più o meno come questo:
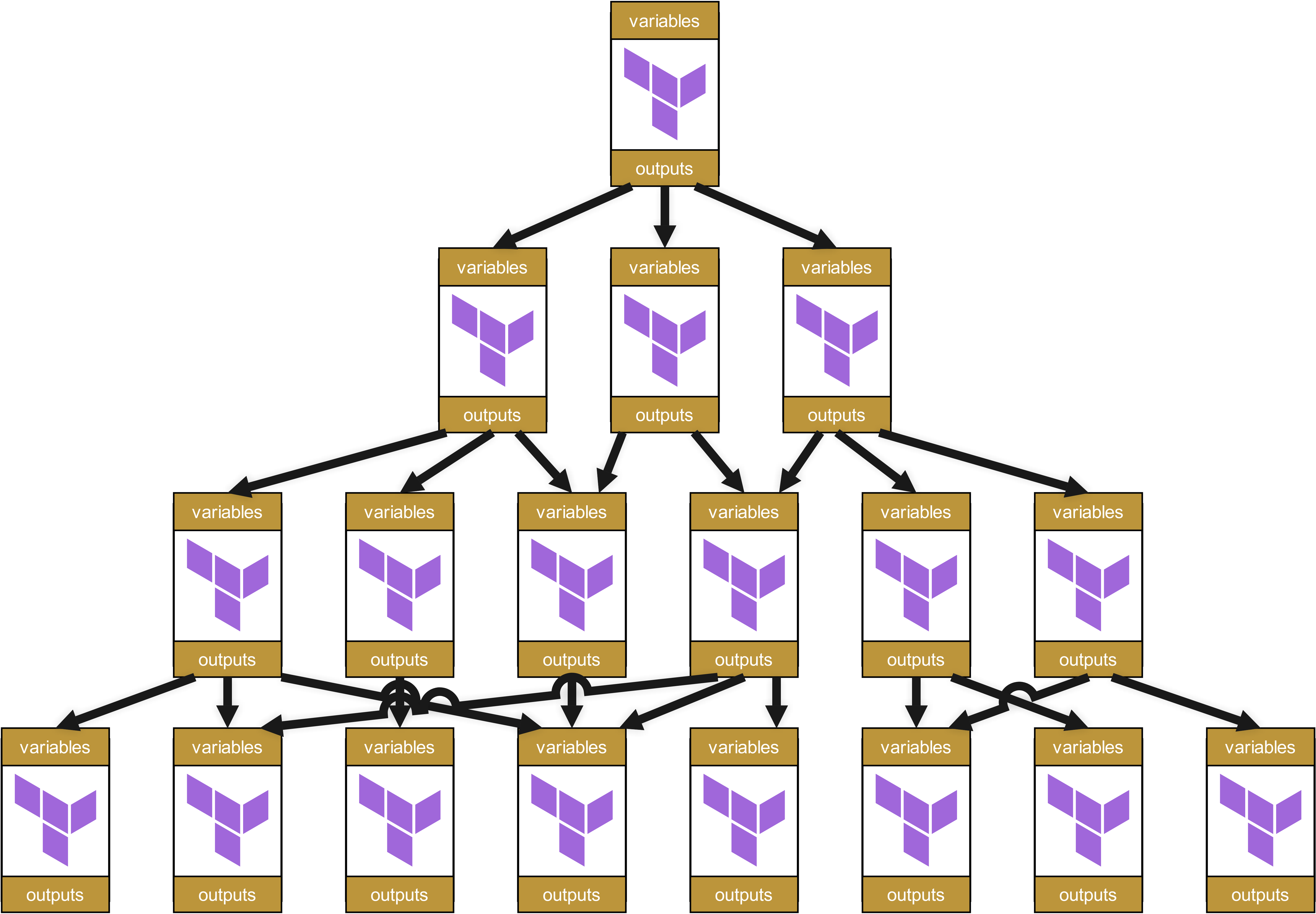
A prima vista questa struttura appare ordinata e ben organizzata. Ogni modulo ha variabili e output chiaramente definiti, che vengono trasmessi correttamente tra i livelli.
Sembra tutto a posto, o no? Beh…
Buon divertimento a fare debug e fix quando da qualche parte si presenta un problema.
Infatti, più in basso nella gerarchia si verifica una modifica, maggiore sarà il cosiddetto "Ripple Effect" fino in cima. Riflettete: cosa succede se in un modulo di base, situato in basso, cambia qualcosa nel codice, che sia un nuovo parametro obbligatorio, un nome di output modificato o una regola di validazione alterata? Cosa succede allora?
Immaginiamo quindi che al livello più basso si verifichi un cambiamento in un modulo.
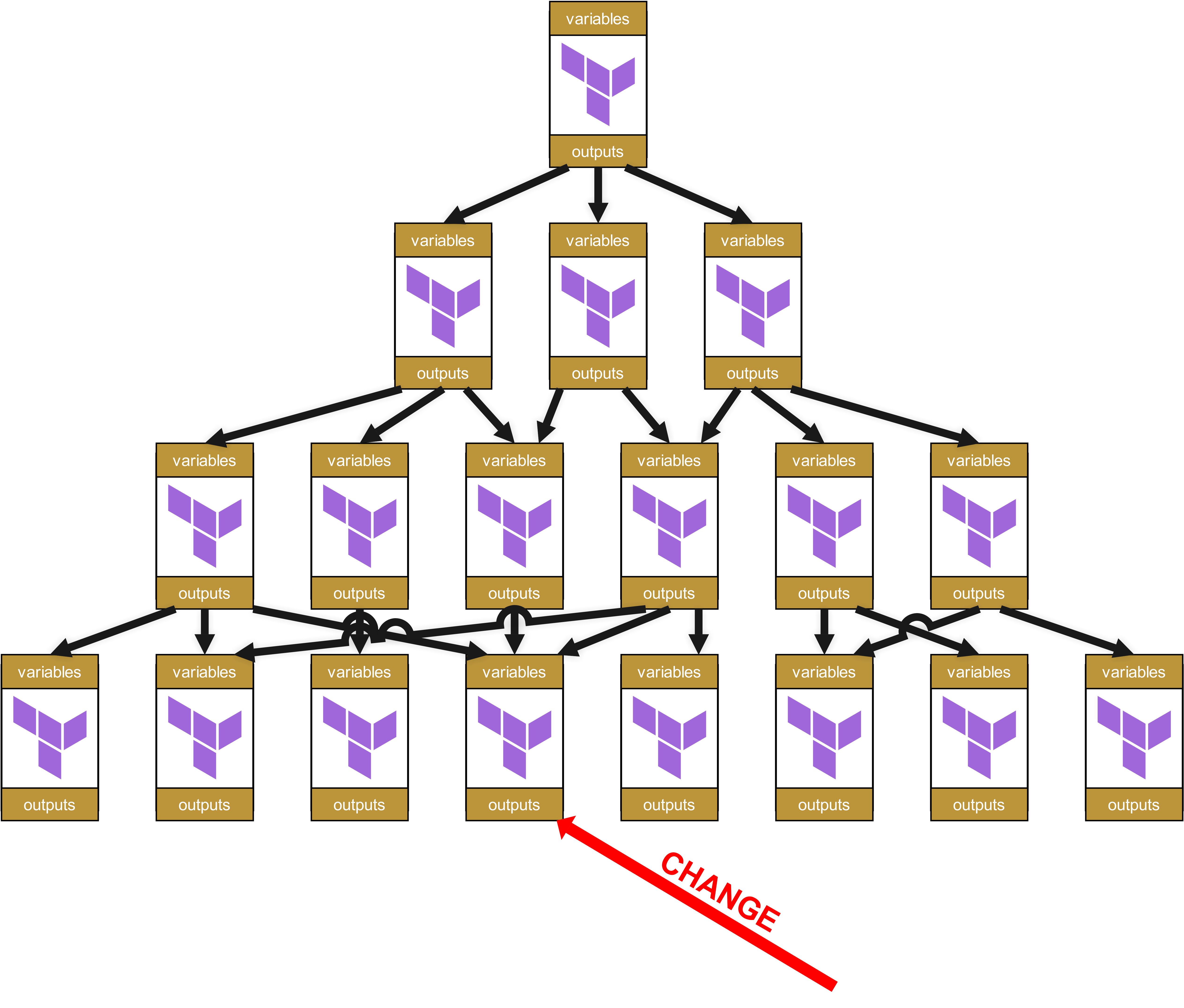
A livello organizzativo sono necessari Change Request lungo tutto l’albero fino alla radice per tutti i moduli dipendenti e per le infrastrutture in cui tali moduli dipendenti vengono utilizzati.
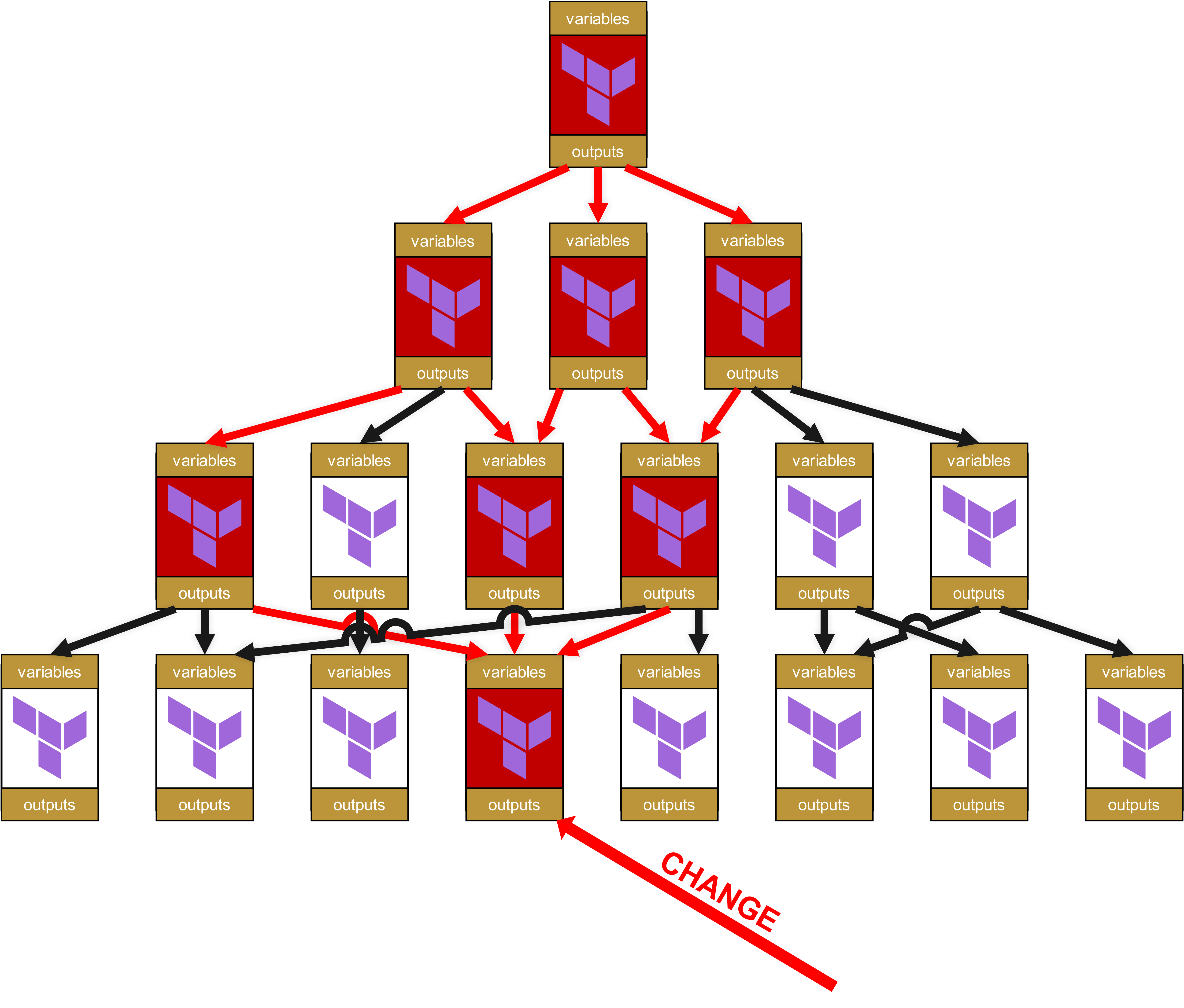
Eh già, qui si cela un grande potenziale di “divertimento”. Perché avete letto bene: non ci sono solo ripercussioni fino in cima, ma la piccola modifica in quel modulo in basso fa sì che tutti i moduli ora segnati in rosso debbano passare di nuovo attraverso la test pipeline. E ancora meglio, poiché ho già parlato di “Change Request”: per ogni infrastruttura in cui un modulo segnato in rosso viene utilizzato direttamente o indirettamente tramite dipendenze (frecce rosse), è necessario un Change Request completo. Ciò significa anche dover informare altri team o persino clienti, affinché a loro volta eseguano test completi sulle proprie infrastrutture.
A ciò si aggiunge, sul piano tecnico, che si accumula rapidamente un’enorme quantità di overhead. Infatti, ciascun modulo ha le proprie variabili e i propri output, che devono essere trasmessi su e giù. La struttura nello State-File diventa sempre più orribile e poco user-friendly per il cliente, con percorsi del tipo module.<resource>.module.<resource>.module.<resource>.... Non si tratta solo di un problema estetico, ma anche operativo, poiché tali percorsi eccessivamente lunghi rendono più difficile il troubleshooting manuale dello state.
E qui avevamo anche semplificato, perché abbiamo parlato solo di un Root-Modul. Nella pratica, però, ogni team e ogni cliente ne ha almeno uno, probabilmente parecchi di più:
A un certo punto, per il cliente diventa più oneroso in termini di codice utilizzare e gestire un modulo piuttosto che creare direttamente le risorse.
E ciò che accade dopo è chiaro:
-
prima si ricomincia a reinventare la ruota,
-
poi si sviluppa una Shadow-IT,
-
quindi subentra il caos operativo. E infine tutto ciò sfocia in
-
un problema critico per il business.
L’alternativa: Organizzazione piatta dei moduli
Per questo motivo le gerarchie di moduli dovrebbero essere mantenute il più possibile piatte. Un’organizzazione dei moduli simile ai Value Stream è quindi la scelta più naturale - un’organizzazione gerarchica dell’infrastruttura è nella maggior parte dei casi sconsigliabile.
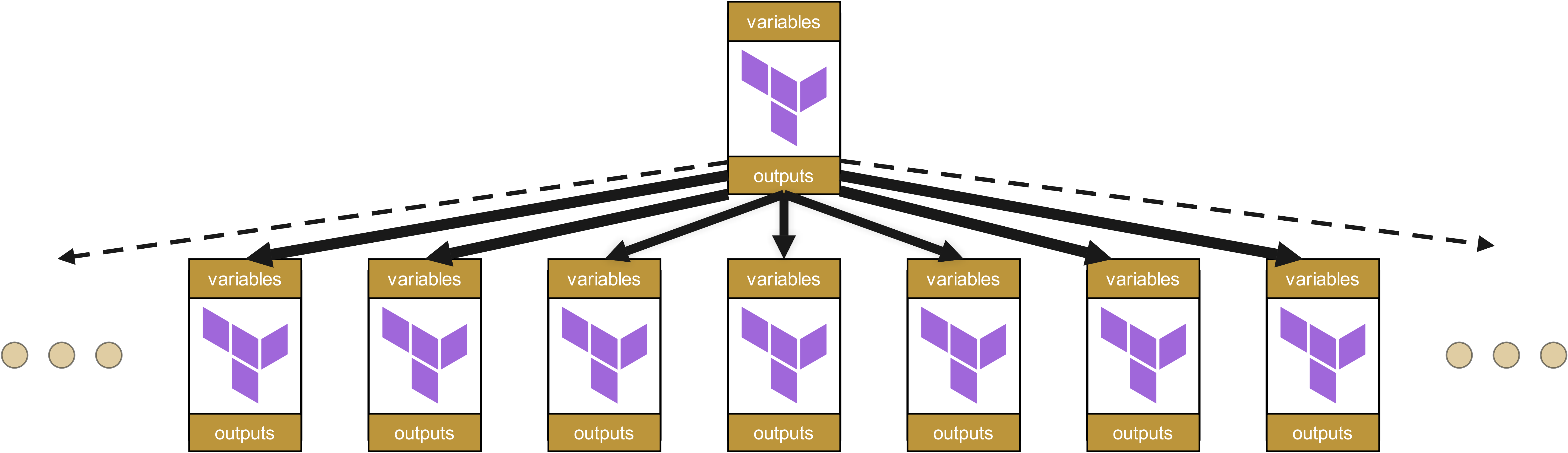
Nelle strutture piatte le modifiche hanno effetto solo sui moduli direttamente dipendenti, e non su un’intera cascata di dipendenze. Questo riduce notevolmente sia lo sforzo di manutenzione sia il rischio di effetti collaterali imprevisti.
Ma anche qui la bellezza dell’idea esiste solo a un primo sguardo.
Il pendolo oscilla troppo: perché strutture completamente piatte falliscono
Prima di trascinare tutti i vostri moduli su un unico livello, dovreste fermarvi a riflettere. Infatti l’altro estremo delle organizzazioni di moduli completamente piatte porta con sé problemi altrettanto gravi.
Senza una minima struttura gerarchica nasce rapidamente ciò che definiamo "Infrastructure-as-Copy&Paste". I team iniziano a sviluppare moduli quasi identici per requisiti solo leggermente differenti, invece di utilizzare astrazioni esistenti. Ciò che era nato come un riutilizzabile oci-compute-module si frammenta in oci-compute-web, oci-compute-api, oci-compute-batch e dozzine di altre varianti. Quante esattamente? Non lo saprete mai, se non chiedendo ai vostri clienti. E tutte queste innumerevoli mutazioni di moduli condividono per oltre l’80% lo stesso codice, ma hanno comunque tutte differenze sottili che rendono una futura consolidazione estremamente difficile.
Il risultato? Incubi di manutenzione par excellence.
Un aggiornamento di sicurezza deve ora essere applicato a decine di diversi "Compute-Module", invece che in un unico modulo di base centrale. Le correzioni vengono quindi implementate in modo generalmente incoerente. Gli standard divergono. Il principio DRY (Don't Repeat Yourself) diventa una barzelletta, mentre gli sviluppatori reinventano la ruota in infinite varianti. La compliance viene compromessa e, con un certo ritardo, anche la certificazione di sicurezza della vostra azienda.
Particolarmente insidioso: le incompatibilità spesso rimangono inosservate per mesi, a volte persino anni, finché improvvisamente non si presenta un aggiornamento di compliance a livello aziendale. Oppure la migrazione di un cliente da un Cloud Provider a un altro. Allora si scopre che i moduli apparentemente "identici" differiscono in dettagli critici. E anche un Blue/Green-Deployment che sembrava semplice si trasforma in un progetto mastodontico.
Il modello a tre livelli: maledizione e benedizione insieme
Nei nostri articoli precedenti abbiamo già presentato il collaudato modello a tre livelli. Ricapitoliamolo brevemente:
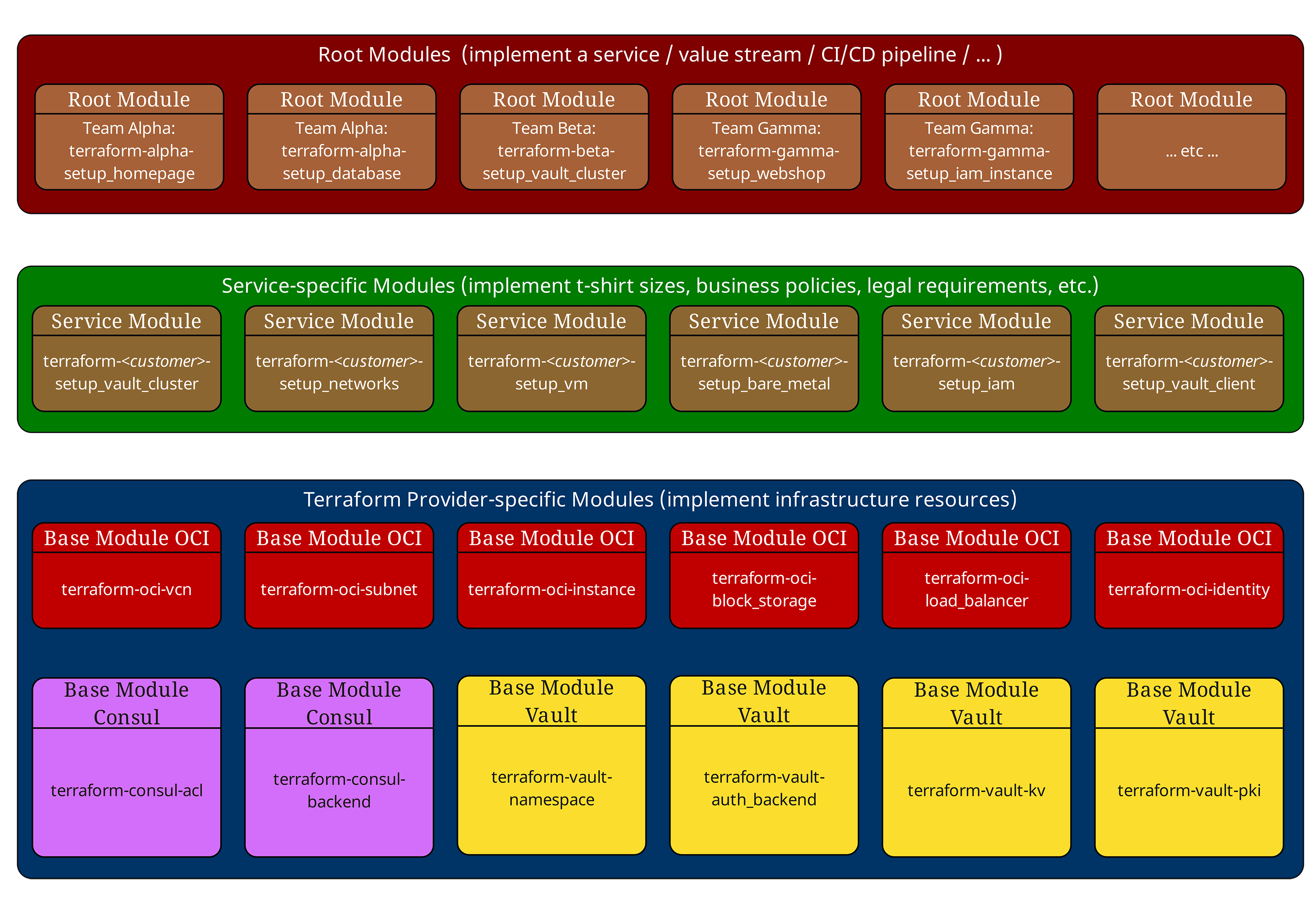
Root-Module (In alto, rosso) orchestrano l’intera infrastruttura di un ambiente. Definiscono le configurazioni del Provider, le impostazioni del Backend e richiamano i Service-Module.
Service-Module (Al centro, verde) implementano gli standard aziendali e le "taglie T-Shirt". Non contengono dichiarazioni di risorse dirette, ma combinano e configurano esclusivamente i moduli di base. I Service-Module non includono volutamente configurazioni di Provider o Backend e non dovrebbero avere effetti collaterali dipendenti dal Provider. In questo modo rimangono riutilizzabili in diversi contesti Root.
Moduli di base (In basso, blu) comunicano direttamente con i Cloud Provider e implementano componenti infrastrutturali atomici come VM, reti o database.
Questa struttura funziona in modo eccellente - finché le dipendenze non diventano davvero complesse. Ed è allora che la benedizione si trasforma facilmente in maledizione.
Esempio di una tipica gerarchia di moduli
Consideriamo una struttura di moduli reale tratta da un progetto cliente:
# Root Module - Production Environment
module "web_application" {
source = "git::https://gitlab.ict.technology/modules//services/web-application?ref=v2.1.0"
environment = "production"
instance_size = "large"
high_availability = true
region = "eu-frankfurt-1"
}
module "database_cluster" {
source = "git::https://gitlab.ict.technology/modules//services/mysql-cluster?ref=v1.8.3"
environment = "production"
storage_tier = "premium"
backup_enabled = true
}
Il Service-Module web-application appare internamente così:
# Service Module - services/web-application/main.tf
locals {
instance_configs = {
small = { ocpus = 2, memory_gb = 8, storage_gb = 50 }
medium = { ocpus = 4, memory_gb = 16, storage_gb = 100 }
large = { ocpus = 8, memory_gb = 32, storage_gb = 200 }
}
config = local.instance_configs[var.instance_size]
}
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.3.2"
instance_count = var.high_availability ? 3 : 1
shape_config = {
ocpus = local.config.ocpus
memory_in_gbs = local.config.memory_gb
}
compartment_id = var.compartment_id
}
module "load_balancer" {
source = "git::https://gitlab.ict.technology/modules//base/oci-loadbalancer?ref=v2.0.1"
backend_instances = module.compute_instances.instance_ids
compartment_id = var.compartment_id
}
module "networking" {
source = "git::https://gitlab.ict.technology/modules//base/oci-networking?ref=v1.5.7"
vcn_cidr = var.environment == "production" ? "10.0.0.0/16" : "10.1.0.0/16"
availability_domains = var.high_availability ? 3 : 1
compartment_id = var.compartment_id
}
Già qui vediamo il primo problema: dipendenze transitive. Il Root-Module vede solo i Service-Module inclusi. Non “sa” quali Base-Module vengano effettivamente utilizzati o in quali versioni.
E indovinate un po’ cosa Terraform non supporta nativamente: la gestione di tali dipendenze transitive. Nel nostro Dependency Tree visto in precedenza non avete alcuna possibilità, con gli strumenti standard di Terraform, di capire quali dipendenze si colorano di rosso e per quali dovete inoltrare Change Request.
Tutto ciò che Terraform vi offre in questo contesto è un’implementazione insufficiente della rappresentazione di un grafo delle dipendenze dall’alto verso il basso, ma non dal basso verso l’alto - terraform graph. E non appena entrano in gioco i Remote State, anche questo è finito, perché terraform graph può gestire solo un singolo Statefile.
Workaround e approcci utilizzabili con strumenti esterni sono possibili, ma tutt’altro che immediati da applicare - e ironia della sorte, proprio con l’uso di Terraform Enterprise spesso non facilmente integrabili:
-
Scansione statica dei moduli con terraform-config-inspect o una semplice analisi HCL in CI per estrarre una lista di tutti i ref nelle URL delle sorgenti dei moduli insieme alle versioni. Questo può essere pubblicato come artefatto per ogni commit.
-
Policy in Sentinel/Conftest/OPA o Checkov/TFLint, che vietano di referenziare moduli senza ref fissa, rilevano versioni miste per ambiente e consentono ad esempio “solo Patch-Upgrade” nelle finestre di manutenzione.
-
Generare e versionare un piccolo “Module SBOM” interno per ogni Root-Run. Ciò presuppone a sua volta che ogni Service- e Base-Module disponga di un proprio SBOM, ma in questo modo si rispondono poi le domande operative più critiche:
-
Quale versione di un modulo viene effettivamente utilizzata?
-
Perché un modulo utilizza una versione più vecchia di un altro modulo?
-
Che effetto ha l’aggiornamento di un modulo su tutti i moduli dipendenti?
-
Ci sono aggiornamenti di sicurezza mancanti in uno dei moduli?
-
Ma la mancanza di una gestione delle dipendenze in Terraform non è il problema più grande. Ce n’è uno ancora peggiore.
Il problema del tracciamento delle versioni: la più grande debolezza di Terraform
Uno degli aspetti più frustranti di Terraform è la totale assenza di un tracciamento nativo delle versioni dei moduli. Mentre terraform version mostra la versione del binary di Terraform, non esiste alcuna funzionalità integrata per qualcosa di simile:
# Those commands do NOT exist in Terraform terraform modules list terraform modules version terraform dependencies show
Anche Terraform Enterprise, al momento della stesura di questo articolo, non offre una soluzione che meriti il nome “Enterprise” - un vero e proprio fallimento per un software che porta “Enterprise” nel nome e che costa rapidamente centinaia di migliaia di dollari l’anno in subscription fee.
Perché è un problema?
Immaginate di avere questa struttura di moduli in produzione:
Production Infrastructure (deployed: 2024-09-01) ├── Root Module: production-env (v1.0.0) │ ├── Service Module: web-application (v2.1.0) │ │ ├── Base Module: oci-compute (v1.3.2) │ │ ├── Base Module: oci-loadbalancer (v2.0.1) │ │ └── Base Module: oci-networking (v1.5.7) │ └── Service Module: mysql-cluster (v1.8.3) │ ├── Base Module: oci-compute (v1.2.8) ← Different version! │ └── Base Module: oci-storage (v3.1.0)
Domande critiche senza risposte semplici, che abbiamo già posto più sopra nel testo in relazione ai Module-SBOM:
-
Quale versione di oci-compute viene effettivamente utilizzata?
-
Perché mysql-cluster utilizza una versione più vecchia di oci-compute?
-
Che effetto ha l’aggiornamento di oci-compute su tutti i moduli dipendenti?
-
Ci sono aggiornamenti di sicurezza mancanti in uno dei moduli?
Impatto reale: l’incidente del cluster MySQL
Un esempio concreto dalla pratica: un cliente aveva implementato una patch di sicurezza critica per il Base-Module oci-compute, che correggeva una vulnerabilità nella configurazione del Metadata-Service. L’aggiornamento era stato applicato solo nel Service-Module web-application, mentre il Service-Module mysql-cluster continuava a referenziare la vecchia versione vulnerabile.
Il risultato? Un penetration test tre mesi dopo ha rilevato la falla di sicurezza nei server database - una falla che il team credeva già “corretta”.
Nel prossimo capitolo analizzeremo quindi approcci adeguati al tracciamento delle versioni dei moduli Terraform.
