











当一次简单的模块更新让 47 个团队陷入停滞...
星期一上午 10:30。一家大型托管云服务提供商的 Platform-Engineering 团队刚刚将用于 VM 实例的基础模块从 v1.3.2 更新到 v1.4.0,看似“无害”。变更是什么?一个新的、但强制性的 Freeform-Tag,用于资源的成本中心归属。
而没人注意到的一点是:那位曾经强烈坚持所有 Terraform 模块必须存放在一个单一 Git 仓库中的 Senior Engineer。他当时的理由是:“版本管理就是过度的 Micromanagement。这样放在一起更整洁,也更省事。”
同一天,下午 15:00:来自不同客户的 47 个团队陆续反馈,他们的 CI/CD-Pipelines 失败了。原因是什么?他们的 Root-Module 引用了提供商更新后的模块,但没有人在自己的 Root-Modulen 中实现新的参数。提供商的合规性检查机制正在运行,并且因为缺少必填的 Tags 而拒绝了 Terraform-Runs。本来计划中的改进,最终演变为一次组织范围内的停摆,并对托管客户产生了巨大的外部影响。
欢迎来到 Terraform @ Scale 模块依赖的世界。
嵌套模块的隐藏复杂性
Terraform-Module 是任何可扩展 Infrastructure-as-Code 实施的支柱。它们促进了可重用性,封装了 Best Practices,并减少了重复。然而,随着模块层级的加深,会产生一种隐藏的复杂性,即便是经验丰富的团队也可能被其困扰。
Ripple-Effect:为什么模块深度会成为陷阱
这个问题可以通过一个简单的例子来说明:假设我们有一个四层的模块层级结构,这在大型组织中非常常见。最上层开始,是一个单一的 Root-Modul:
![]()
这个模块调用了其他模块:
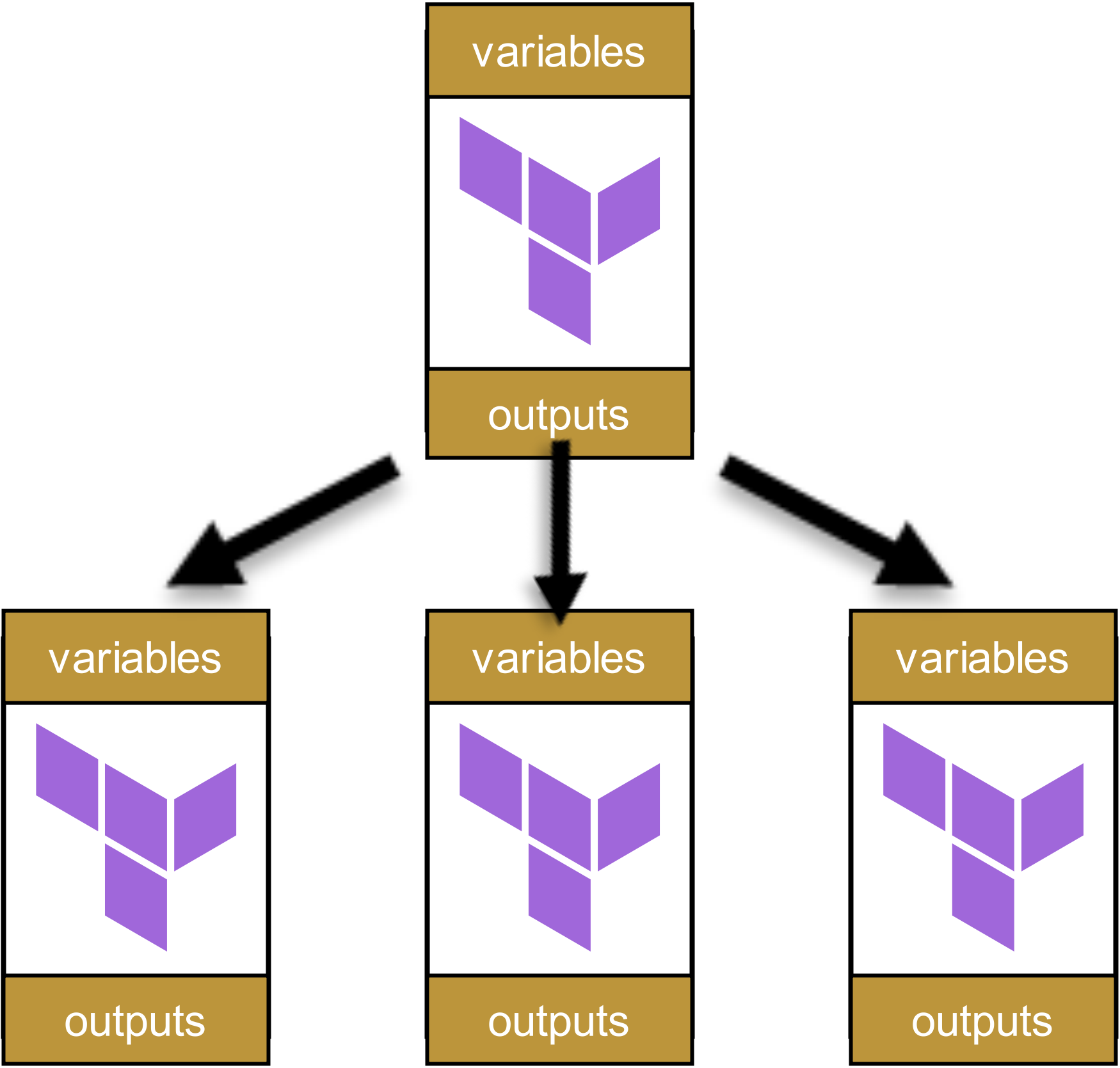
而这些模块又会调用其他模块,依次类推,形成一个 Dependency Tree,大致如下:
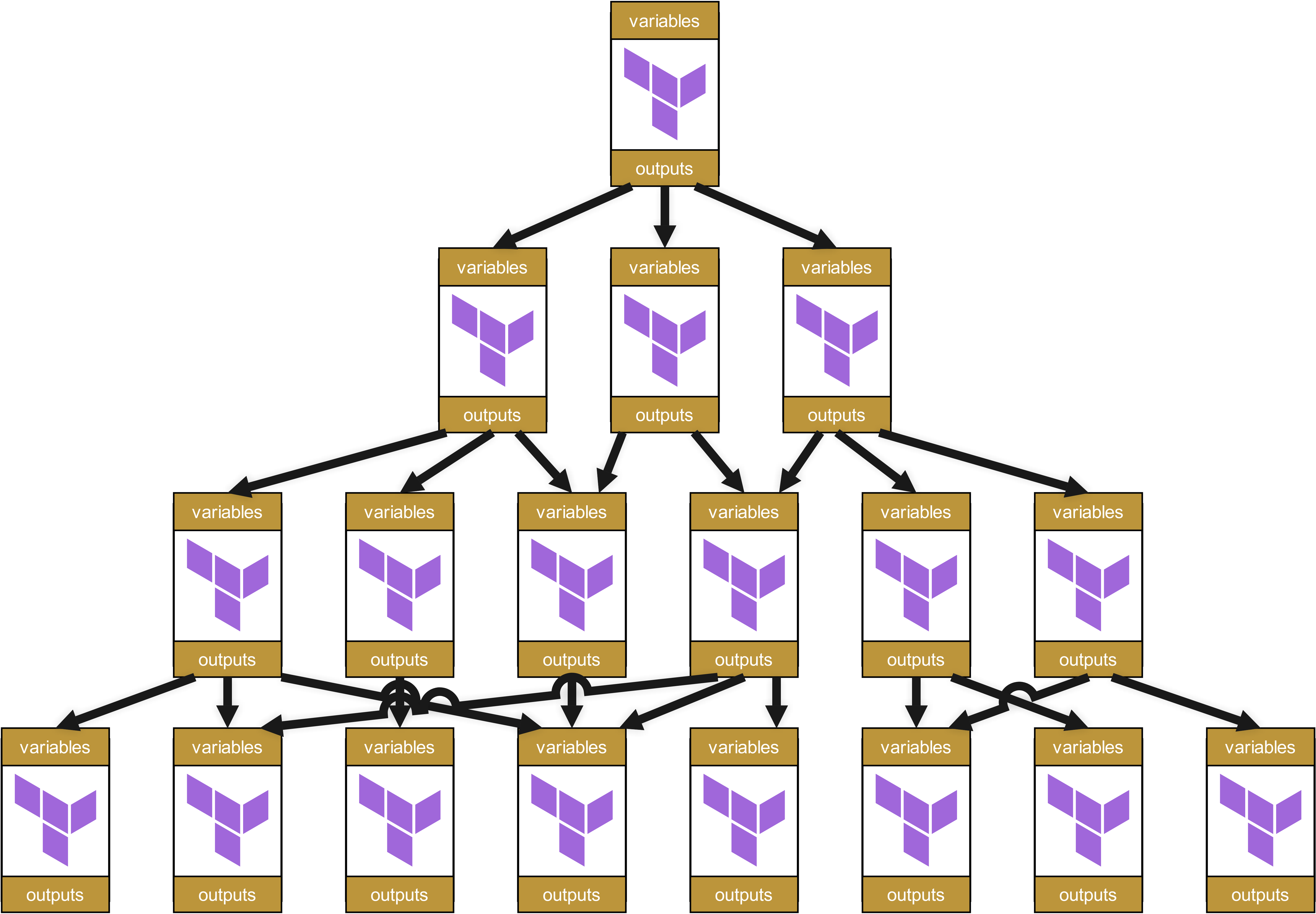
乍一看,这种结构似乎井然有序且组织良好。每个模块都有明确定义的变量和 Outputs,在不同层级间被干净地传递。
看起来挺不错的,对吗?嗯……
一旦某处出现问题,调试和修复的乐趣就开始了。
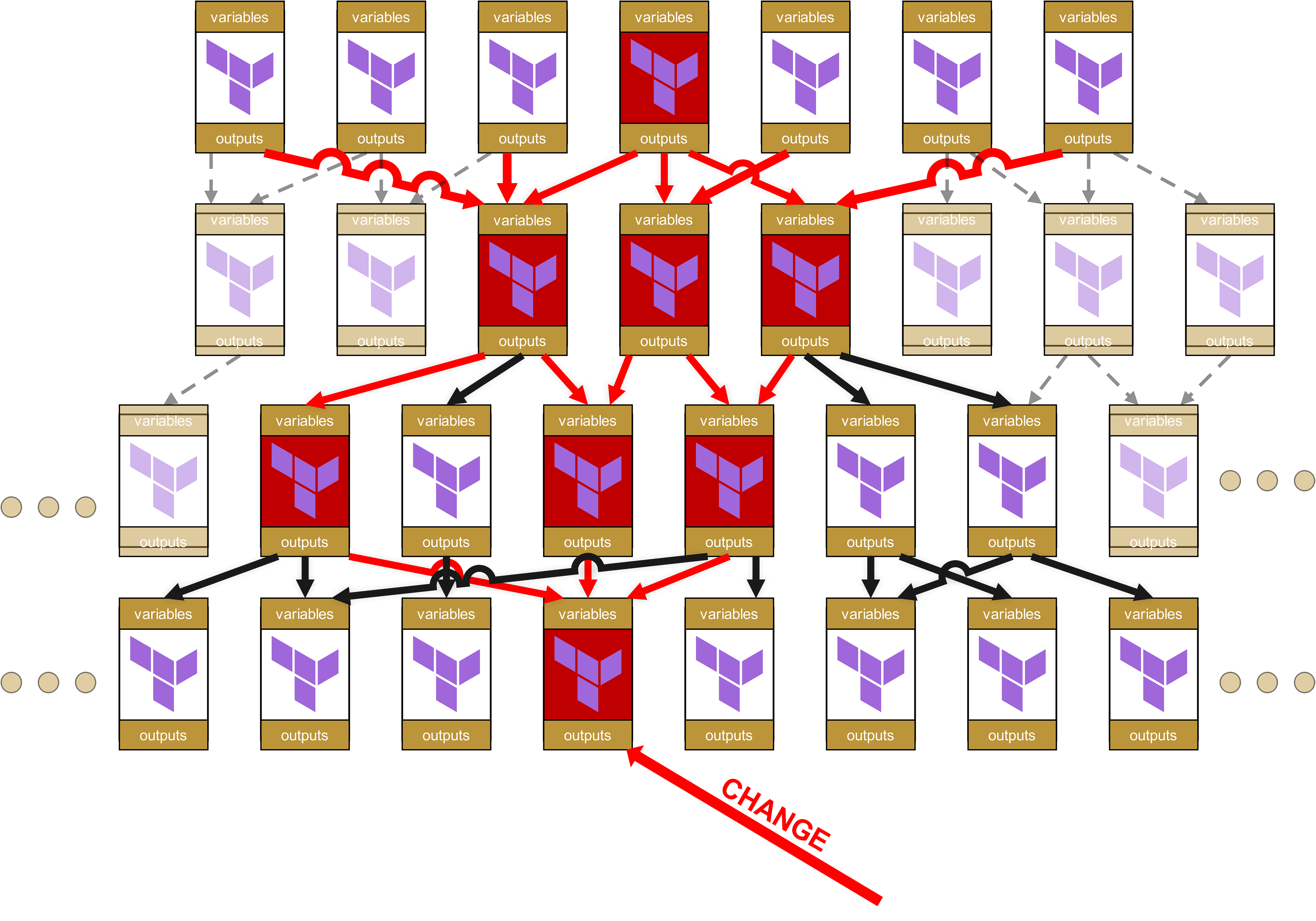
因为越往下的层级发生变化,往上层传递的所谓 "Ripple Effect" 就越大。请您设想一下:如果某个最底层的基础模块发生了代码变更,比如新增了一个强制参数、更改了某个 Output 名称,或者修改了某个验证规则,会发生什么呢?
假设现在在最底层的某个模块中出现了变更。
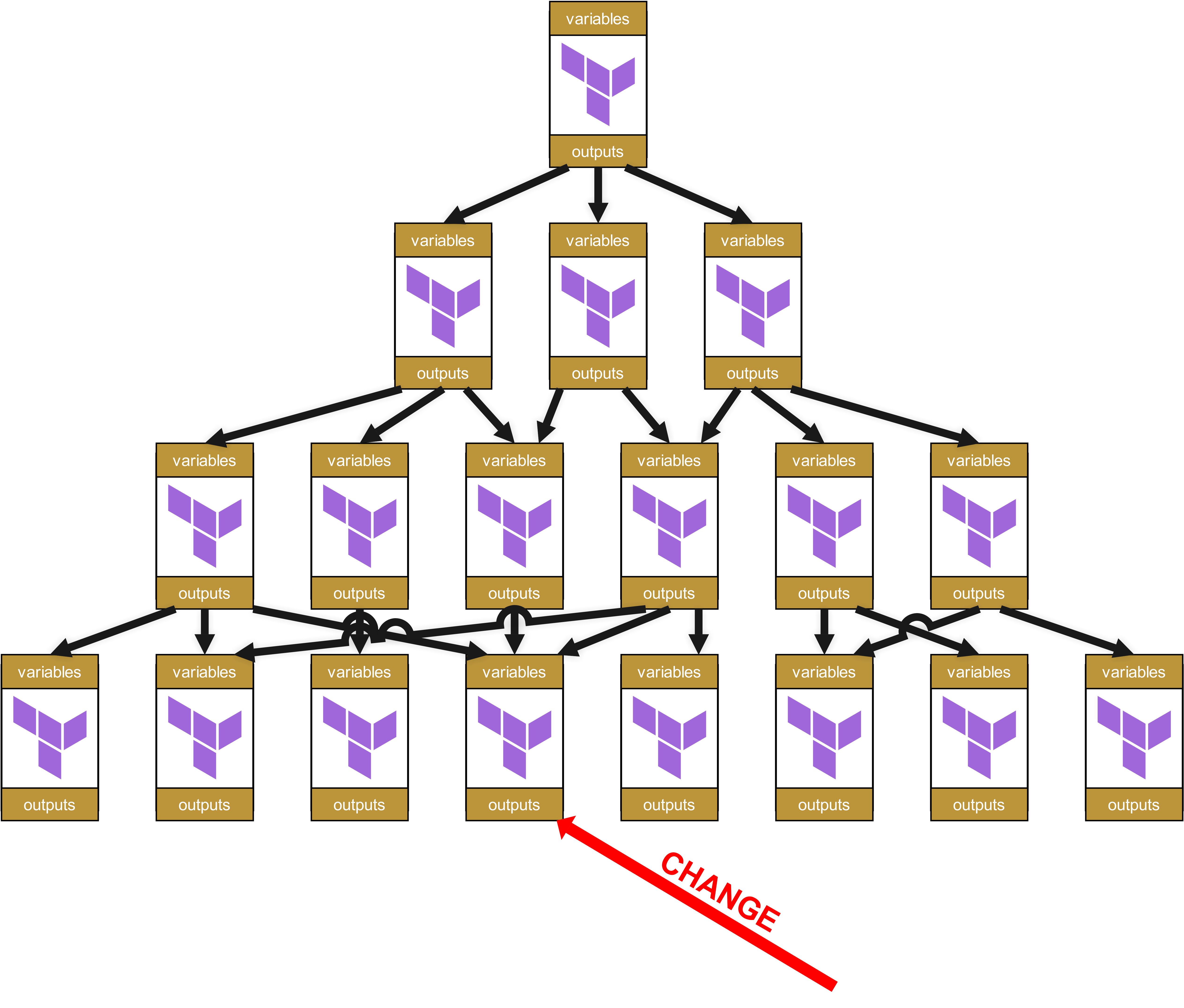
在组织层面上,这意味着从底层到最顶层的每一个依赖模块,以及这些模块所在的基础设施,都需要提交 Change Requests。
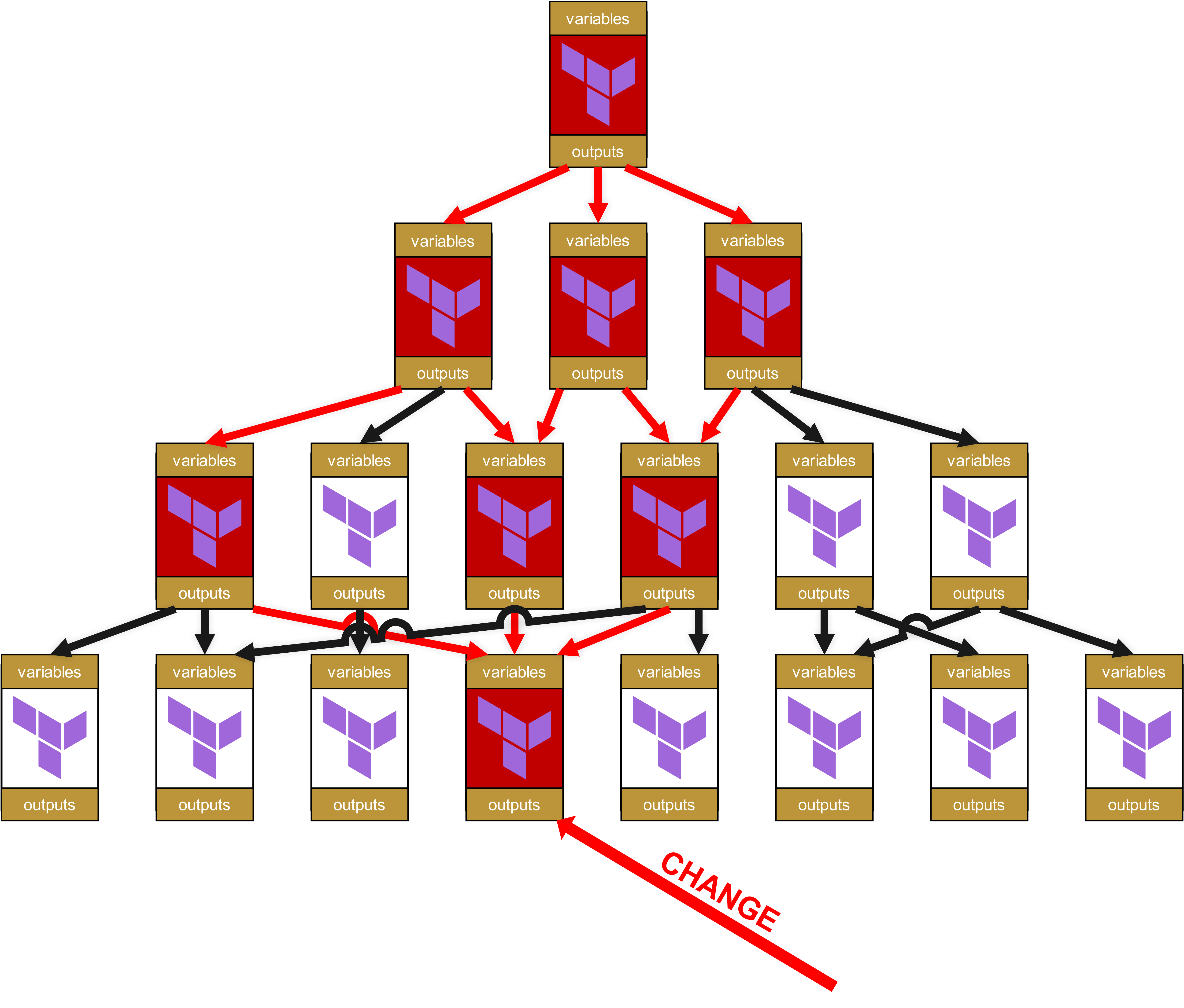
哦,这里已经埋下了巨大的“乐趣”潜力。因为您没看错:影响不仅一路传递到最顶层,而且底层模块的一点小改动,会导致所有被标红的模块都必须重新通过测试流水线。而且更“精彩”的是,我已经说过“Change Request”:对于每一个在基础设施中直接或间接(通过 Dependencies,红色箭头)使用了标红模块的场景,都需要一个全面的 Change Request。这也意味着必须通知其他团队,甚至客户,让他们去全面测试各自的基础设施。
从技术层面看,这还会迅速积累出荒谬的 Overhead。因为每个模块都有自己的变量和 Outputs,这些需要在上下层级不断传递。State-File 的结构会变得越来越臃肿和不友好,路径会变成类似 module.<resource>.module.<resource>.module.<resource>... 的形式。这不仅在视觉上很糟糕,而且在运维上也很关键,因为这种过长的路径会让手动 State-Troubleshooting 变得更加困难。
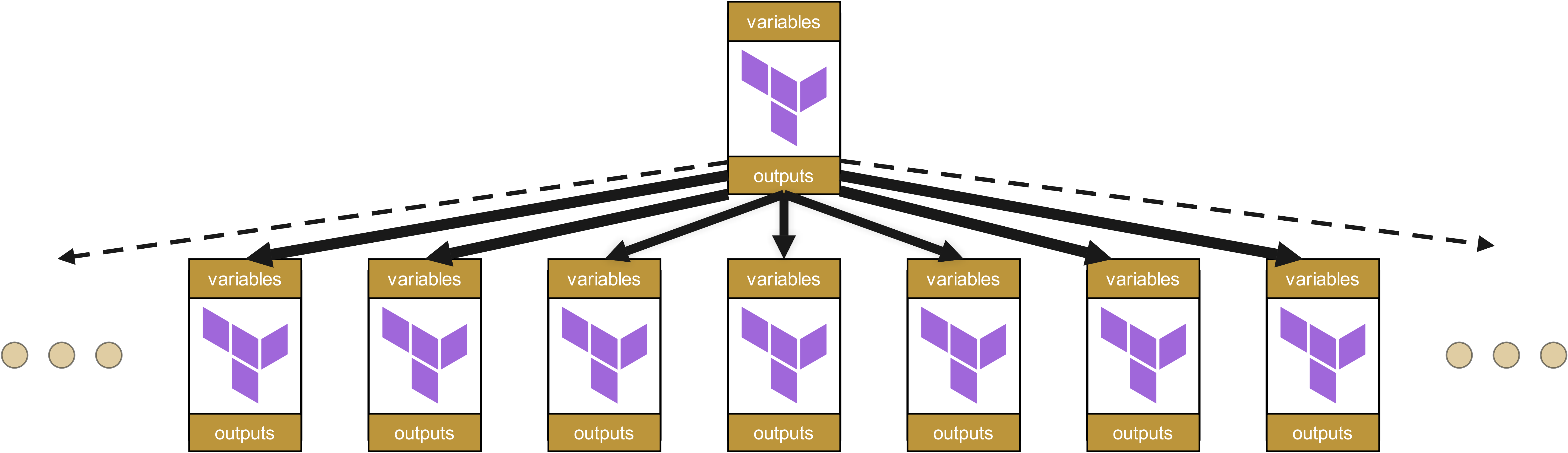
而且我们之前还简化了,只谈到了一个 Root-Modul。在实际场景中,每个团队、每个客户至少会有一个,通常甚至会有相当多个:
最终,客户会发现,使用和维护模块的代码开销比直接管理资源本身还要大。
接下来会发生什么,就很清楚了:
-
首先是重复造轮子,
-
然后出现 Shadow-IT,
-
接着是运维混乱。而这最终会演变为
-
一个对业务至关重要的问题。
替代方案:扁平化的模块组织
因此,模块层级应尽可能保持扁平化。一种类似 Value Streams 的模块组织方式因此非常合理——在大多数情况下,不建议采用层级化的基础设施组织。
在扁平化结构中,变更只会影响直接依赖的模块,而不会波及整个依赖级联。这大大减少了维护工作量,也显著降低了意外副作用的风险。
但这种看似美好的设计,也只是第一眼的错觉。
钟摆过度:为什么完全扁平的结构会失败
在您打算把所有模块都拉到同一层之前,应该先停下来思考。因为完全扁平的模块组织同样会带来不容小觑的问题。
缺少一定的层级结构后,很快就会出现我们所谓的 "Infrastructure-as-Copy&Paste"。团队开始为了些微的差异开发几乎相同的模块,而不是复用现有的抽象。曾经可复用的 oci-compute-module,会被分裂成 oci-compute-web、oci-compute-api、oci-compute-batch 以及几十个其他变体。具体多少个?除非您去问客户,否则永远不会知道。而这些数量不明的模块变种,代码中有超过 80% 是相同的,但依然存在细微的差异,这使得后续的整合极为困难。
结果是什么?一场维护噩梦。
一个安全更新现在必须分别应用到几十个不同的 "Compute-Module" 中,而不是在一个中央基础模块中完成。因此,修复通常会被不一致地实现。标准逐渐分裂。DRY 原则 (Don't Repeat Yourself) 彻底沦为笑谈,开发人员则在无休止地以各种变体重复造轮子。合规性形同虚设,而安全认证也会在滞后后被企业拖累。
尤其阴险的是:这些不兼容性往往在几个月甚至几年里都不被发现,直到突然需要一次全公司的合规更新,或者某个客户需要从一个 Cloud-Provider 迁移到另一个时。届时才会发现,那些看似“相同”的模块在关键细节上存在差异。即便是一个看似简单的 Blue/Green-Deployment,也会变成庞大的项目。
三层模型:福祸相依
在之前的文章中,我们已经介绍过经过验证的三层模型。让我们在此再简要回顾一下:
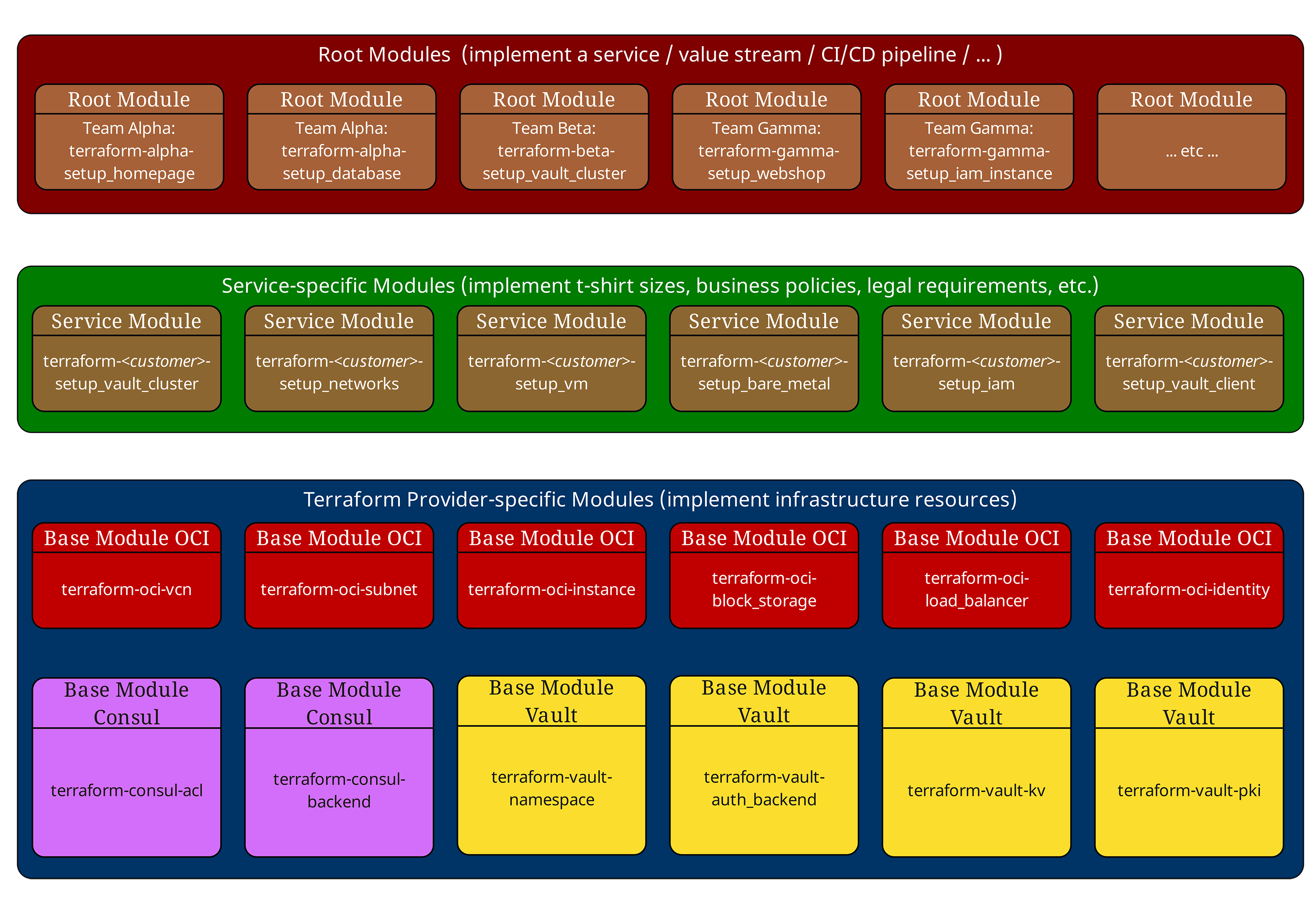
Root-Module(顶层,红色) 编排一个环境的整个基础设施。它们定义 Provider 配置、Backend 设置,并调用 Service-Module。
Service-Module(中层,绿色) 实现企业标准和 “T-Shirt 尺寸”。它们不包含任何直接的资源声明,而是仅组合和配置基础模块。Service-Module 同时刻意不包含 Provider 或 Backend 配置,并且不应产生 Provider 相关的副作用。因此,它们可以在不同的 Root-上下文中复用。
Basis-Module(底层,蓝色) 直接与 Cloud-Providern 交互,实施原子化的基础设施组件,如 VM、网络或数据库。
这种结构在大多数情况下运作良好——直到依赖关系变得真正复杂时。到那时,福音就很容易变成了诅咒。
典型模块层级示例
我们来看一个真实客户项目中的模块结构:
# Root Module - Production Environment
module "web_application" {
source = "git::https://gitlab.ict.technology/modules//services/web-application?ref=v2.1.0"
environment = "production"
instance_size = "large"
high_availability = true
region = "eu-frankfurt-1"
}
module "database_cluster" {
source = "git::https://gitlab.ict.technology/modules//services/mysql-cluster?ref=v1.8.3"
environment = "production"
storage_tier = "premium"
backup_enabled = true
}
Service-Module web-application 内部结构如下:
# Service Module - services/web-application/main.tf
locals {
instance_configs = {
small = { ocpus = 2, memory_gb = 8, storage_gb = 50 }
medium = { ocpus = 4, memory_gb = 16, storage_gb = 100 }
large = { ocpus = 8, memory_gb = 32, storage_gb = 200 }
}
config = local.instance_configs[var.instance_size]
}
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.3.2"
instance_count = var.high_availability ? 3 : 1
shape_config = {
ocpus = local.config.ocpus
memory_in_gbs = local.config.memory_gb
}
compartment_id = var.compartment_id
}
module "load_balancer" {
source = "git::https://gitlab.ict.technology/modules//base/oci-loadbalancer?ref=v2.0.1"
backend_instances = module.compute_instances.instance_ids
compartment_id = var.compartment_id
}
module "networking" {
source = "git::https://gitlab.ict.technology/modules//base/oci-networking?ref=v1.5.7"
vcn_cidr = var.environment == "production" ? "10.0.0.0/16" : "10.1.0.0/16"
availability_domains = var.high_availability ? 3 : 1
compartment_id = var.compartment_id
}
在此我们已经看到了第一个问题:传递性依赖。Root-Module 只看得到被引入的 Service-Module。它并“不知道”实际使用了哪些 Basis-Module,或它们的具体版本。
再猜猜看,Terraform 对什么没有原生支持:此类传递性依赖的管理。在我们上文的Dependency Tree 中,您无法仅凭 Terraform 自带工具查出哪些依赖会被标红、以及需要在哪些地方提交 Change Requests。
Terraform 在这里能提供的一切,只是一个从上到下输出依赖图、而不是自下而上的拙劣实现 - terraform graph。一旦出现 Remote States,连这个也用不上,因为 terraform graph 只能处理单一的 Statefile。
可以通过外部工具实现变通与可用方案,但它们同样很难直接把问题解决到位 - 更具讽刺意味的是,在使用 Terraform Enterprise 时,往往还不容易集成:
-
在 CI 中使用 terraform-config-inspect 的静态扫描或简单的 HCL 分析,提取模块 source URL 中所有 Refs 及其版本的清单。该清单可按每次提交作为制品发布。
-
在 Sentinel/Conftest/OPA 或 Checkov/TFLint 中编写 Policies,禁止引用没有固定 Ref 的模块,检测每个环境中的混合版本,并例如仅在维护窗口允许“仅 Patch 升级”。
-
为每次 Root-Run 生成并版本化一个小型内部“Module SBOM”。这又要求每个 Service- 和 Basis-Module 具备自己的 SBOM,但借此您能在运营上回答最关键的问题:
-
某个模块实际使用的是哪个版本?
-
为什么某模块会使用另一个模块的旧版本?
-
更新某模块会对所有依赖模块产生怎样的影响?
-
是否存在某些模块缺失的安全更新?
-
但 Terraform 缺少依赖管理并非最大的问题。更糟糕的还在后面。
版本追踪问题:Terraform 最大的弱点
Terraform 最令人沮丧的方面之一是完全缺乏原生的模块版本追踪。虽然 terraform version 会显示 Terraform 二进制的版本,但没有任何内置功能能做到类似下面这样的事:
# Those commands do NOT exist in Terraform terraform modules list terraform modules version terraform dependencies show
截至本文撰写时,Terraform Enterprise 在这里也没有能配得上“Enterprise”称号的解决方案——对于一款名字里带着 “Enterprise”、年度订阅费用动辄数十万美元的软件而言,这是难以接受的。
为什么这是个问题?
设想您在生产环境中有如下模块结构:
Production Infrastructure (deployed: 2024-09-01) ├── Root Module: production-env (v1.0.0) │ ├── Service Module: web-application (v2.1.0) │ │ ├── Base Module: oci-compute (v1.3.2) │ │ ├── Base Module: oci-loadbalancer (v2.0.1) │ │ └── Base Module: oci-networking (v1.5.7) │ └── Service Module: mysql-cluster (v1.8.3) │ ├── Base Module: oci-compute (v1.2.8) ← Different version! │ └── Base Module: oci-storage (v3.1.0)
一些没有简单答案的关键问题,我们已在上文模块 SBOM 语境中提出:
-
实际使用的 oci-compute 是哪个版本?
-
为什么 mysql-cluster 使用了较旧版本的 oci-compute?
-
更新 oci-compute 会对所有依赖模块产生何种影响?
-
是否有某些模块缺失的安全更新?
现实影响:MySQL-Cluster 事件
一个来自实际的例子:某客户为 oci-compute Basis-Module 实施了一个关键安全补丁,用于修复 Metadata-Service 配置中的漏洞。该更新仅应用在 web-application Service-Module,而 mysql-cluster Service-Module 仍然引用旧的、存在漏洞的版本。
结果如何?三个月后的渗透测试在数据库服务器上发现了这处安全缺陷——而团队此前以为这已经“打过补丁”。
因此,在下一章节中,我们将探讨用于 Terraform 模块版本追踪的合适解决思路。
