











Nella Parte 1 della nostra serie abbiamo conosciuto i concetti fondamentali di Retrieval-Augmented Generation (RAG) e abbiamo visto come questo framework funziona in modo simile a una biblioteca digitale. Abbiamo esaminato in dettaglio i tre componenti principali - Retriever, Ranker e Generator - e abbiamo compreso come collaborano per generare risposte precise e contestualmente rilevanti.
In questa seconda parte, approfondiamo gli aspetti tecnici del RAG. Esamineremo come il RAG viene implementato nella pratica, quali diversi tipi di modelli esistono e come i sistemi potenziati con RAG si differenziano dai tradizionali Large Language Models (LLMs).
I due tipi di modelli RAG: Sequence e Token
Nell'implementazione del RAG esistono due approcci fondamentali: RAG-Sequence e RAG-Token. Ciascuno di questi approcci ha i suoi punti di forza specifici ed è adatto per diversi casi d'uso.
RAG-Sequence: L'approccio olistico
RAG-Sequence opera come un autore meticoloso che prima studia tutte le fonti rilevanti e poi compone un testo coerente. L'eleganza matematica di questo approccio risiede nella sua visione olistica:
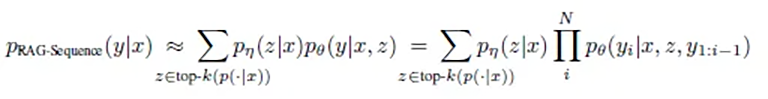
O semplificato e tradotto in italiano: p(risposta | domanda) = somma su tutti i documenti( p(documento | domanda) × p(risposta | domanda, documento) )
In parole semplici, questo significa:
- Il sistema calcola due valori per ogni documento potenzialmente rilevante:
- Qual è la probabilità che questo documento sia rilevante per la domanda?
- Qual è la probabilità che questo documento porti alla risposta corretta?
- Queste probabilità vengono moltiplicate tra loro e sommate per tutti i documenti per trovare la migliore risposta.
Il processo tecnico si svolge come segue:
- Il sistema seleziona i Top-K documenti più rilevanti per la query da un indice di milioni di documenti
- Il Generator crea una potenziale risposta completa per ciascuno di questi documenti
- Queste risposte vengono combinate in base alla loro probabilità calcolata
La ricerca mostra che questo approccio è particolarmente efficace quando si tratta della creazione di risposte coerenti e ben strutturate. Un dettaglio interessante dagli studi: la qualità delle risposte migliora continuamente con l'inclusione di più documenti rilevanti.
I risultati della ricerca mostrano che RAG-Sequence si comporta particolarmente bene in compiti che richiedono un output coerente e connesso. Le risposte sono tipicamente più variegate e sfumate rispetto ad altri approcci.
Questo approccio è particolarmente adatto per:
- Riassunti di testi lunghi
- Creazione di report
- Rispondere a domande complesse che richiedono una comprensione completa
- Compiti che richiedono coerenza tematica attraverso l'intero testo
RAG-Token: L'approccio granulare
RAG-Token opera come un giornalista scrupoloso che consulta la migliore fonte possibile per ogni singola frase e parola della sua storia. La formulazione matematica di questo approccio riflette questa attenzione:
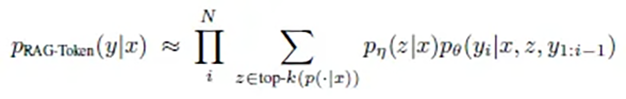
p(risposta | domanda) = prodotto per ogni parola( somma su tutti i documenti( p(documento | domanda) × p(parola | domanda, documento, parole precedenti) ) )
In pratica, questo significa:
- Per ogni singola parola della risposta:
- I documenti più rilevanti vengono rivalutati
- Viene calcolata la probabilità per ogni possibile parola successiva
- Viene scelta la parola più probabile basata su tutte le informazioni disponibili
- Questo processo si ripete parola per parola, dove ogni nuova parola è influenzata da:
- Le parole scritte finora
- La domanda originale
- I documenti attualmente più rilevanti
La ricerca ha dimostrato che questo approccio fornisce risultati particolarmente precisi quando si tratta di accuratezza fattuale. È interessante notare che esiste uno "sweetspot" ottimale nel numero di documenti considerati: circa 10 documenti per token forniscono i migliori risultati. Più documenti non portano necessariamente a risposte migliori, ma possono aumentare significativamente il tempo di elaborazione.
Gli studi hanno dimostrato che RAG-Token è particolarmente efficace in compiti che richiedono risposte dettagliate e basate sui fatti. Il numero ottimale di documenti recuperati, secondo lo sweetspot, è tipicamente di circa 10 documenti - poiché più documenti non migliorano necessariamente i risultati, ma aumentano i costi.
Questo approccio è ottimale per:
- Spiegazioni tecniche dettagliate
- Risposte basate sui fatti
- Situazioni che richiedono informazioni altamente specifiche
- Casi in cui diverse parti della risposta richiedono fonti diverse
L'implementazione tecnica: La Pipeline RAG
L'implementazione pratica di un sistema RAG avviene in tre fasi principali: Ingestion, Retrieval e Generation. Ciascuna di queste fasi svolge un ruolo decisivo per la qualità dei risultati finali.
1. La fase di Ingestion
In questa prima fase, i documenti vengono inseriti nel sistema e preparati per l'uso successivo. L'implementazione originale del RAG utilizzava un dump di Wikipedia con 21 milioni di documenti, ciascuno suddiviso in chunks di 100 parole. Il processo si svolge come segue:
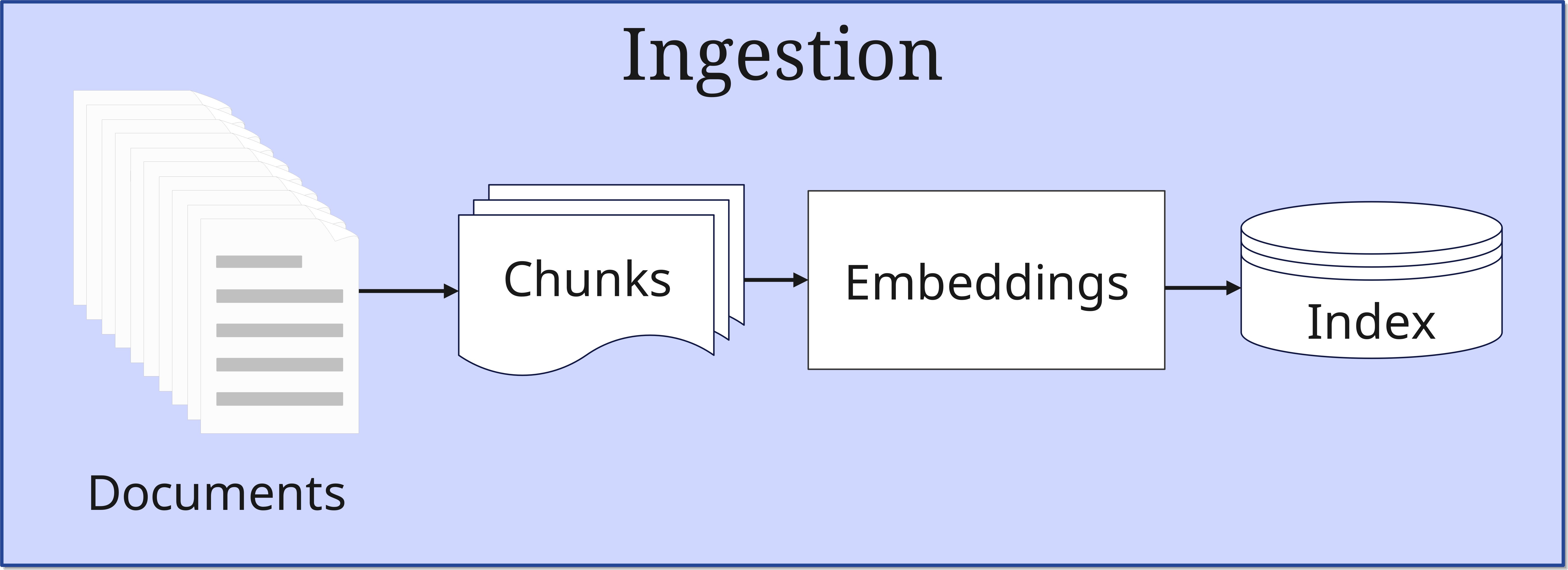
- Preparazione dei documenti:
- I documenti (Documents) vengono suddivisi in pezzi più piccoli e gestibili (Chunks)
- La dimensione dei chunk viene ottimizzata in base al caso d'uso
- Generazione degli Embedding:
- Ogni chunk viene convertito in un vettore matematico multidimensionale (generalmente fino a 1024 dimensioni) attraverso un document encoder basato su BERT
- Questi vettori catturano la semantica del testo, quindi non il testo letterale ma il significato (approfondiremo i vettori in un futuro articolo sulle banche dati vettoriali)
- Indicizzazione:
- Gli embeddings vengono memorizzati in un database vettoriale
- Per la ricerca efficiente viene creato un indice MIPS (Maximum Inner Product Search)
- Tecnologie come FAISS permettono una ricerca rapida e approssimativa in tempo sublineare
Questo processo è cruciale per l'efficienza successiva del sistema. L'arte sta nel suddividere i documenti in modo che le informazioni correlate non vengano separate, ma i chunks rimangano abbastanza piccoli da fornire risultati precisi.
2. La fase di Retrieval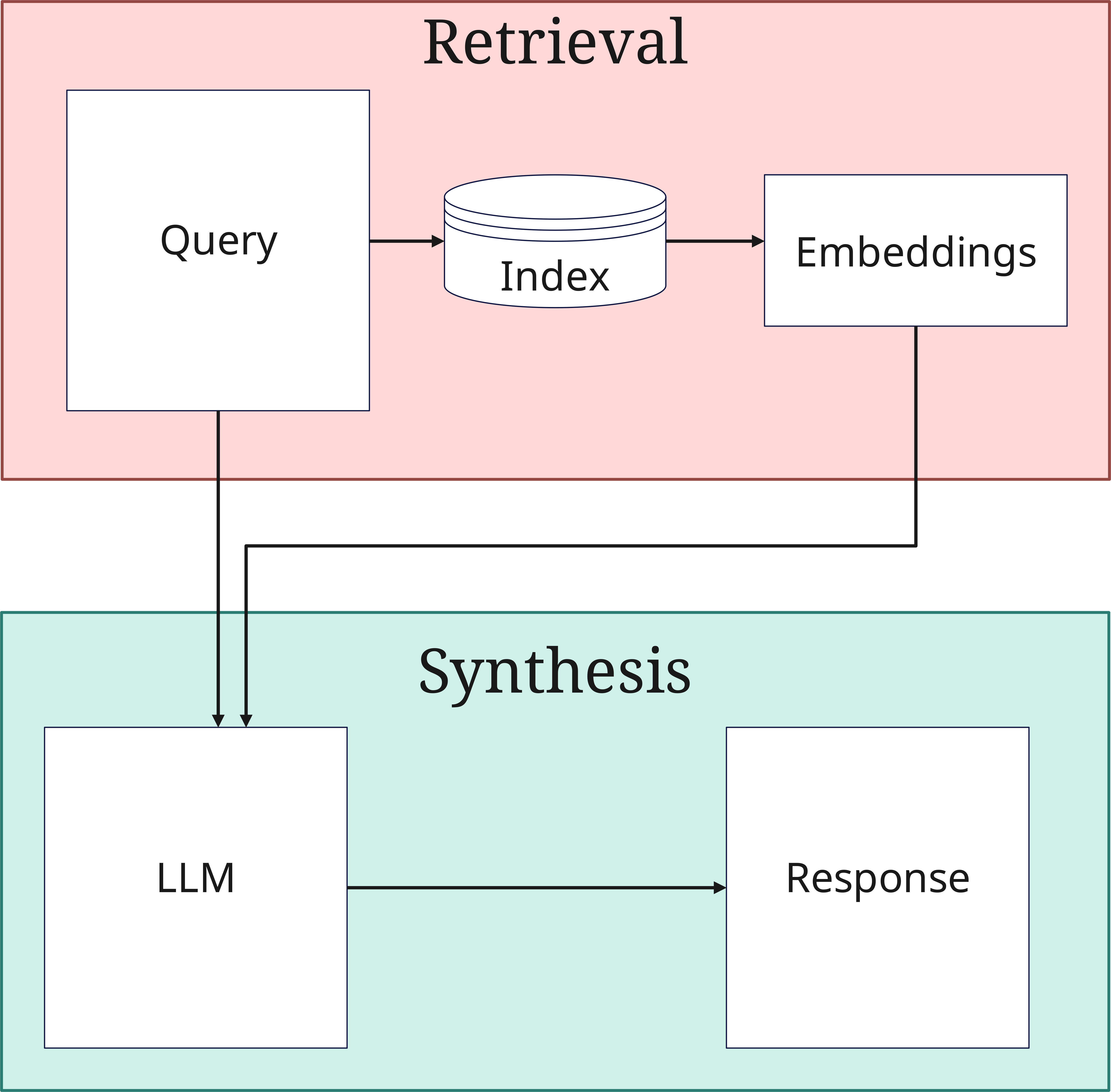
Quando arriva una query, inizia la fase di Retrieval:
- Elaborazione della query: Anche la query viene convertita in un vettore. Questa query viene memorizzata dal Retriever sia nel database vettoriale che inviata direttamente in originale alla sintesi della risposta nel Generator
- Ricerca di similarità: Il sistema cerca nel database vettoriale (Index) i documenti che sono simili a quelli trasmessi al database. Qui i vettori della query vengono confrontati con quelli dei documenti indicizzati
- Selezione Top-K: Vengono selezionati i documenti più rilevanti
Il numero di documenti selezionati (Top-K) è un parametro importante che influenza l'equilibrio tra completezza ed efficienza di elaborazione.
3. La fase di Generation (Synthesis)
Nella fase finale, le informazioni trovate vengono elaborate per creare una risposta:
- Integrazione del contesto: I documenti Top-K selezionati vengono combinati con la query originale
- Generazione della risposta: L'LLM crea una risposta coerente
- Controllo qualità: La risposta viene verificata per consistenza e rilevanza e successivamente emessa
Un esempio comprensibile
Fase 1: Creazione di un prompt (Query)
Immaginate un dipendente che si avvicina alla vostra scrivania e vi pone una domanda:
"Abbiamo un'idea per un progetto. Vogliamo fare xyz. Quali sono le linee guida legali per questo?"
Questa richiesta è un prompt.
Ora mettetevi nella posizione dell'intelligenza artificiale. La domanda è chiara e diretta. Ma per poter rispondere, avete bisogno di più contesto. Quindi cercate in tutta la vostra memoria di conversazioni precedenti con questo dipendente e stabilite così un migliore riferimento all'argomento, che porterà a una comprensione migliore e più completa della domanda.
Tutte le informazioni trovate costituiscono il contesto. Il prompt viene ora ampliato con il contesto - le informazioni storiche vengono quindi allegate alla domanda effettiva del dipendente. Il prompt diventa così quello che viene chiamato Enhanced Prompt.
Inoltre, come supervisore, vi ponete anche la domanda di come esattamente l'idea del progetto benefici la vostra azienda. Quindi ci riflettete un po' voi stessi, magari fate qualche domanda aggiuntiva, e arricchite ulteriormente l'Enhanced Prompt con le intuizioni trovate. Gradualmente, la Query viene così completata.
Fase 2: Embedding
Nel passo successivo, inserite la vostra Query in un Embedding Model, che la converte in un vettore a 1024 dimensioni. Quindi non solo tridimensionale, ma un valore davvero inimmaginabile per le persone normali. Attraverso queste 1024 dimensioni, è poi possibile catturare il significato della Query con una certa precisione. Quindi non le singole parole, ma il senso. L'Embedding Model memorizza ora questo vettore nel database vettoriale.
Ora il database vettoriale esegue una ricerca di similarità rispetto al vettore della Query. La similarità trovata di un documento significa che questo è pre-selezionato. Alla fine della ricerca, vengono poi selezionati i migliori risultati e referenziati i documenti, le voci di database, ecc. corrispondenti.
Questi documenti e altre informazioni trovate vengono ora allegati alla Query. Immaginatelo come allegare documenti a un'email già formulata. L'Enhanced Prompt diventa così un Augmented Prompt.
Fase 3: Generazione di una risposta
Questo Augmented Prompt va ora insieme alla Query originale al Generator, più precisamente all'LLM coinvolto. L'LLM sintetizza ora una risposta dalla richiesta originale e da tutte le informazioni aggiuntive trovate. Questa Response viene poi inviata al dipendente che si spera sia soddisfatto del contenuto.
La RAG Triad: Valutazione della qualità
Anche se un LLM attraverso RAG ha accesso alle informazioni più aggiornate nel pool informativo e può fornire risposte molto accurate, questo non elimina il rischio di allucinazioni. Ci sono diverse ragioni per questo:
- Il Retriever semplicemente non raccoglie abbastanza contesto (quantitativamente), o raccoglie informazioni sbagliate (qualitativamente).
- Forse la risposta non è completamente supportata dal contesto raccolto, ma è stata troppo influenzata dall'LLM e dai dati di training.
- Un RAG potrebbe raccogliere le informazioni rilevanti e costruire su di esse una risposta fondamentalmente corretta, ma poi la risposta potrebbe non corrispondere alla domanda effettiva.
Per evitare questo, è stata sviluppata la RAG Triad.
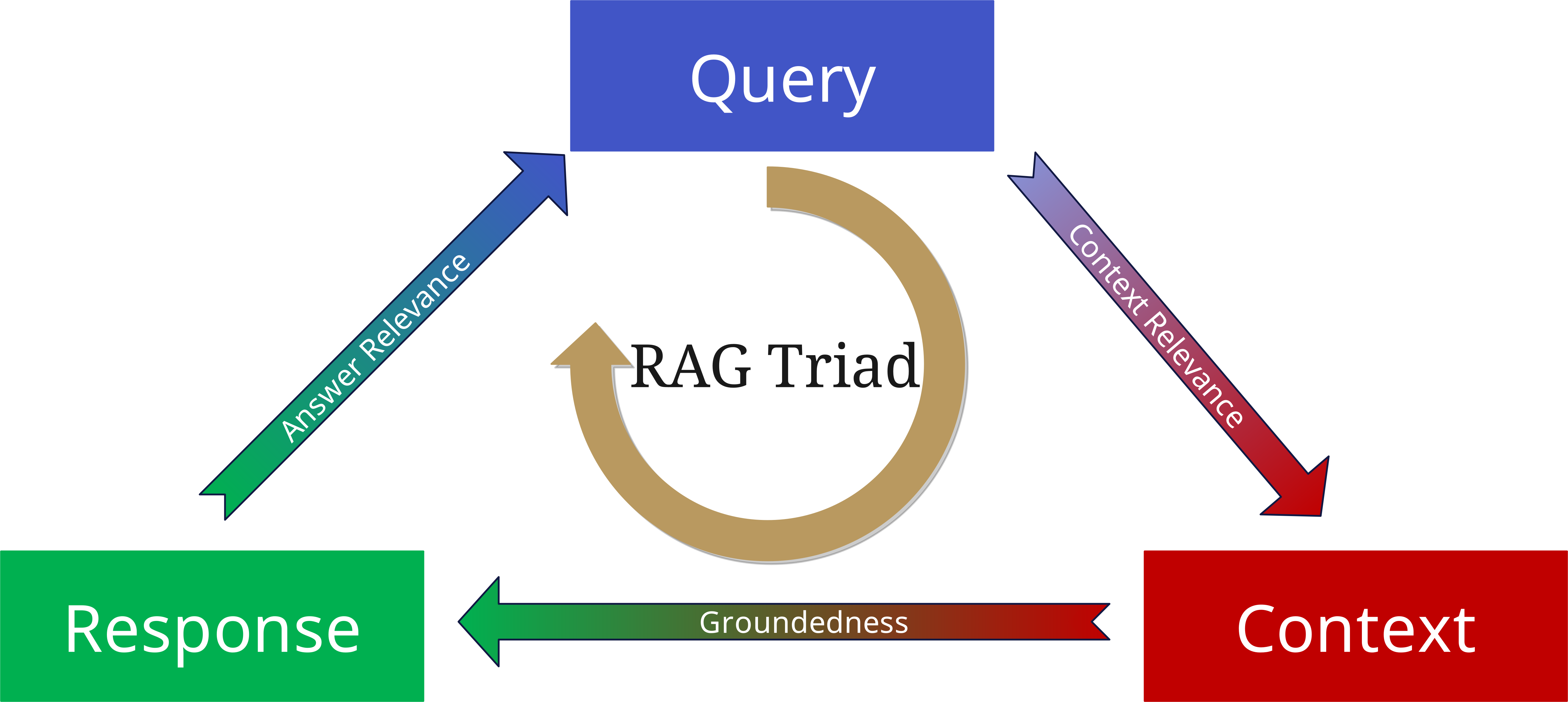
Per valutare la qualità di un sistema RAG, consideriamo tre aspetti centrali:
1. Context Relevance (Rilevanza del contesto)
- Quanto bene i documenti recuperati si adattano alla query?
- È stato trovato il contesto giusto?
- Le informazioni sono attuali e appropriate?
2. Groundedness (Fondatezza)
- La risposta è effettivamente basata sui documenti recuperati?
- Le affermazioni sono supportate dalle fonti?
- Ci sono allucinazioni o conclusioni non fondate?
3. Answer Relevance (Rilevanza della risposta)
- La risposta generata risponde alla domanda originale?
- La risposta è completa e precisa?
- La profondità delle informazioni è appropriata?
Quando si applicano questi tre aspetti come parametri alla query, al contesto e alla risposta generata, si possono minimizzare le allucinazioni e costruire applicazioni basate su RAG più affidabili e robuste.
LLMs con e senza RAG: Un confronto
I LLMs tradizionali e i sistemi potenziati con RAG differiscono fondamentalmente nel loro modo di operare:
LLMs tradizionali
- Si basano esclusivamente su conoscenze pre-addestrate
- Non possono accedere a informazioni nuove o specifiche
- Sono più suscettibili alle allucinazioni
- Hanno uno stato di conoscenza "congelato"
Sistemi potenziati con RAG
- Combinano conoscenze pre-addestrate con fonti esterne
- Possono accedere a informazioni attuali e specifiche
- Forniscono risposte tracciabili basate su fonti
- Sono espandibili in modo flessibile
Queste differenze rendono RAG una soluzione ideale per le applicazioni aziendali, dove precisione, attualità e tracciabilità sono cruciali.
Anticipazione della Parte 3: Il ruolo dei database vettoriali
Un componente centrale che rende possibile RAG è il database vettoriale. Questi database specializzati sono ottimizzati per la memorizzazione e l'interrogazione di vettori - le rappresentazioni matematiche del testo che costituiscono il fondamento di RAG.
Nella Parte 3 della nostra serie, ci occuperemo intensamente dei database vettoriali:
- Come funzionano in dettaglio?
- Quali tipi di database vettoriali esistono?
- Come si sceglie il database vettoriale giusto per il proprio progetto?
- Quali sono le best practice per l'implementazione?
Il database vettoriale è il cuore di un sistema RAG e merita quindi particolare attenzione. È la chiave per una ricerca ed elaborazione efficiente delle informazioni e quindi decisivo per le prestazioni dell'intero sistema.
