











Nell’articolo precedente abbiamo esaminato la complessità nascosta dei moduli annidati e il cosiddetto Ripple-Effect, rendendoci progressivamente conto delle spiacevoli conseguenze che ciò può avere nell’esercizio operativo e nel lifecycle management. A tali problemi si può spalancare la porta commettendo errori da principianti - soprattutto quello di infilare più moduli, o addirittura tutti i moduli Terraform, in un unico repository Git. Con un po’ di seniority e una pianificazione accurata, tuttavia, è possibile minimizzare questi problemi sin dall’inizio.
In questa parte vedremo in pratica come affrontare tali dipendenze senza che i dolori prendano il sopravvento.
Approcci pratici per il tracciamento delle versioni dei moduli
La condizione fondamentale è questa regola d’oro:
- Con la versione libera e gratuita di Terraform, ogni modulo Terraform ha SEMPRE il proprio repository Git ed è SEMPRE versionato individualmente tramite tag.
- Con Terraform Enterprise si utilizza la registry interna dei moduli. Questo consente di usare Version Constraints come li conosciamo già dai blocchi dei provider, cioè vincoli tramite operatori come "=", "<=", ">=", "~>".
Perché lo si vuole fare?
Consideriamo un esempio reale dal mondo OCI. Immaginate un modulo base il cui aggiornamento più recente romperebbe la funzionalità dei moduli dipendenti:
# Base Module: base/oci-compute v1.2.0
variable "freeform_tags" {
type = map(string)
default = {}
description = "Freeform tags for cost allocation"
# NEW in v1.2.0: Mandatory CostCenter Tag
validation {
condition = can(var.freeform_tags["CostCenter"])
error_message = "CostCenter tag is required for all compute instances."
}
}
resource "oci_core_instance" "this" {
for_each = var.instances
display_name = each.value.name
compartment_id = var.compartment_id
freeform_tags = var.freeform_tags
# ... etc.
}
Il modulo di servizio web-application v1.3.4 è stato però sviluppato prima di questo Breaking Change:
# Service Module: services/web-application v1.3.4
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute"
instances = {
web1 = { name = "web-server-1" }
web2 = { name = "web-server-2" }
}
compartment_id = var.compartment_id
# freeform_tags missing - Breaking Change!
}
Se si procede in questo modo, allora scoppia tutto, come descritto nella parte 6a precedente di questa serie di articoli.
Strategia 1 (Terraform): Pinnen esplicito delle versioni dei moduli di servizio e dei moduli base
I moduli base sono i moduli che utilizzano un provider e gestiscono risorse. Hanno sempre un proprio repository individuale e sono sempre versionati.
Lo stesso vale per i moduli di servizio. I moduli di servizio richiamano solo moduli base, non implementano risorse. Quando richiamano i moduli base, i moduli di servizio devono però pinnarne esplicitamente la versione. Solo così gli aggiornamenti transitivi possono avvenire in maniera controllata.
Con i moduli root il comportamento è simile. Essi richiamano i moduli di servizio e ne pinnano esattamente le versioni.
Riprendiamo quindi l’esempio di un modulo di servizio dal paragrafo precedente:
# Service-Module: services/web-application v1.3.5
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
instances = {
web1 = { name = "web-server-1" }
web2 = { name = "web-server-2" }
}
compartment_id = var.compartment_id
# freeform_tags missing - Breaking Change!
}
Vede la differenza? Invece di
source = "git::https://gitlab.ict.technology/modules//base/oci-compute"
ora pinniamo la versione esatta del modulo base:
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
In questo modo la modifica nel modulo base non fa male a nessuno in esercizio.
Ciò che però può ancora creare problemi è il caso in cui, all’interno di un modulo di servizio più ampio o di un modulo root, una chiamata di modulo si presenti più volte e vengano quindi richiamate versioni diverse. Questo non può funzionare. Bisogna decidere quale versione di un modulo si vuole richiamare.
Purtroppo, il pinning duplicato o incoerente all’interno di un modulo root (stessi moduli base in versioni diverse) non viene rilevato automaticamente da Terraform. Terraform valida esclusivamente la risoluzione dei singoli riferimenti source, non la coerenza globale tra più chiamate.
Qui Le metto a disposizione lo script check-module-dependencies.sh, che può usare come ispirazione e nell’ambito non commerciale. A causa della sua lunghezza di quasi 200 righe non lo mostro qui direttamente, ma Le fornisco il link al repository Git: https://github.com/ICT-technology/check-module-dependencies/
Lo script analizza un modulo root o di servizio e controlla i numeri di versione dei moduli richiamati. Se tutto va bene, produce un output come questo:
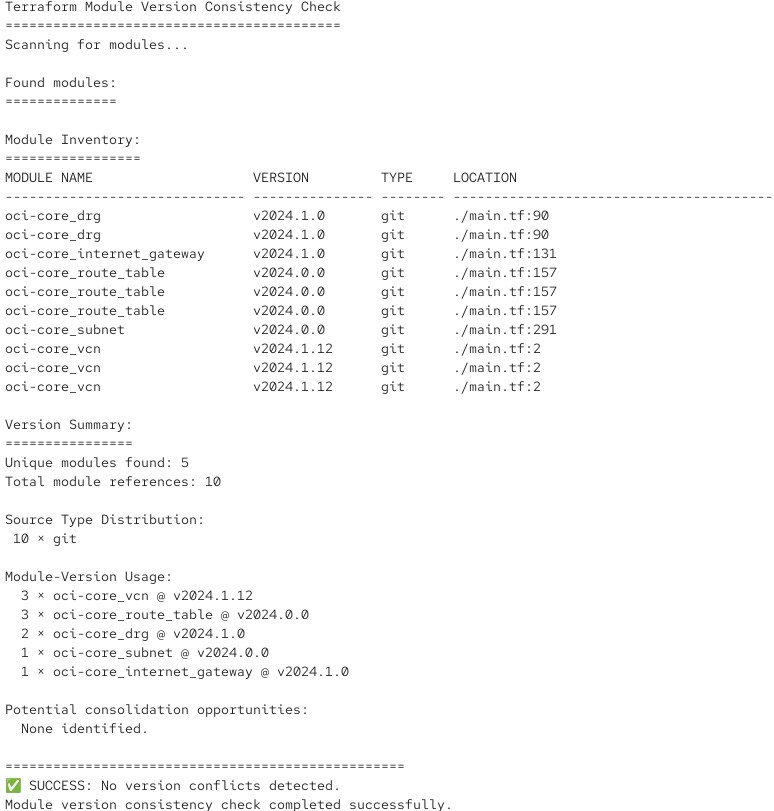
E se rileva che si verificherebbero conflitti di versione, restituisce un corrispondente messaggio di errore con return code:
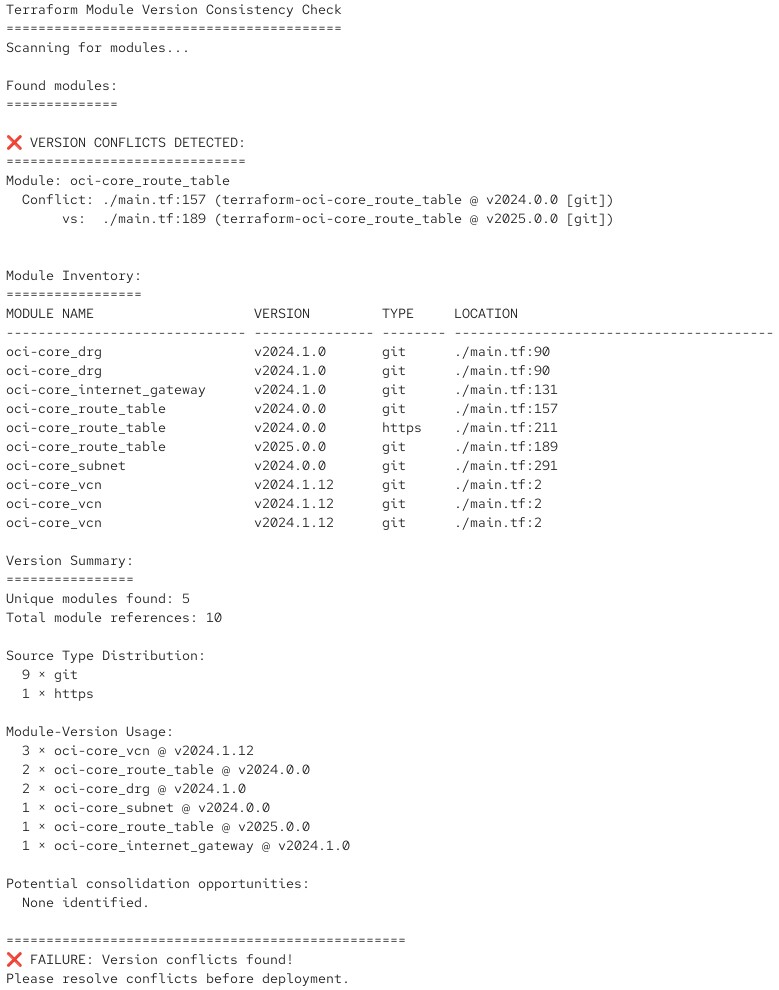
Può integrare uno script simile nella pipeline CI/CD dell’ambiente di test e automatizzare così la verifica.
Con la strategia 2 diventa più semplice.
Strategia 2 (Terraform Enterprise): Semantic Versioning con intervalli
Con Terraform Enterprise diventa semplice (e molto più professionale). Lì dovrebbe utilizzare la Private Module Registry integrata per un vero Semantic Versioning, così come già avviene con la versioning dei provider, ma come parte di una chiamata di modulo:
# Terraform Enterprise on-prem and HCP Terraform only
module "web_service" { source = "registry.ict.technology/ict-technology/web-application/oci" version = "~> 1.1.0" # Permits 1.1.0, 1.1.1, 1.1.2 ... 1.1.x, but NOT 1.0.x or 1.2.x environment = "production" }
Ecco come appare poi nella pratica
Se in questa configurazione un modulo base o un modulo di servizio viene patchato e riceve un nuovo numero di versione, ciò non cambia la funzionalità del Suo modulo root e della pipeline. Riprendiamo ancora una volta questa illustrazione del capitolo precedente:
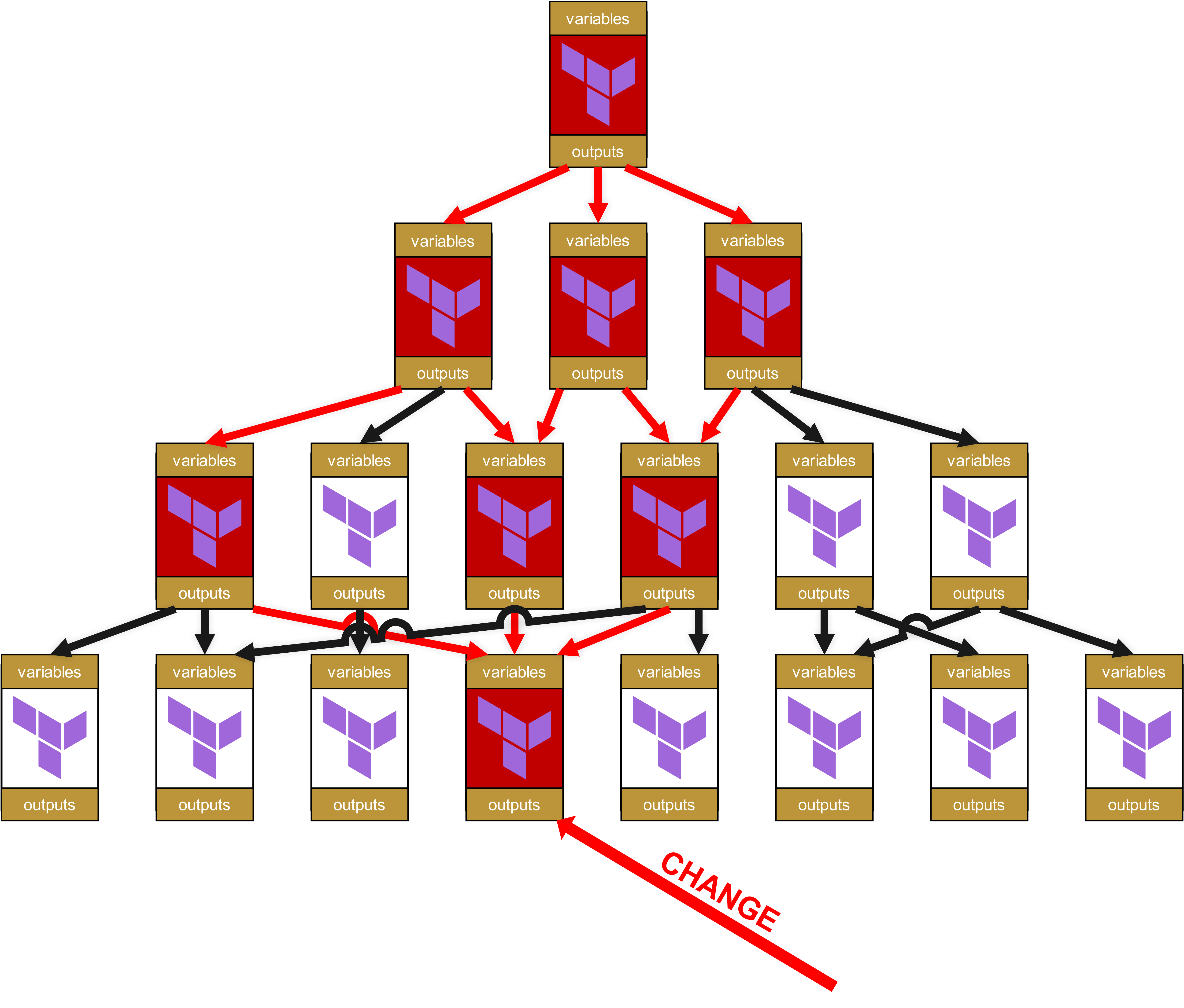
Qui vede i quattro livelli. In alto c’è il livello 1, e in basso, nel livello 4, avviene un cambiamento. Per questo il modulo nel livello 4 riceve un nuovo numero di versione, per esempio un upgrade da v1.1.0 a v1.2.0.
Ma poiché i moduli nel livello 3 hanno ancora pinnato la versione v1.1.0, la nuova v1.2.0 non ha alcun effetto. Prima devono essere testati con successo i moduli del livello 3. Nei test ci sono due possibili scenari:
- I moduli di servizio al livello 3 funzionano ancora perfettamente -> il pinning del modulo base viene alzato da v1.1.0 a v1.2.0 e i moduli di servizio vengono portati a una nuova Minor Release, ad esempio da v1.3.4 a v1.3.5.
- I moduli di servizio al livello 3 non funzionano più perfettamente. Ciò significa che nel modulo base v1.2.0 c’è stato un Breaking Change. Pertanto i moduli di servizio interessati al livello 3 vengono patchati e nuovamente versionati, questa volta però come Major Release, ad esempio da v1.3.4 a v1.4.0. Con questo salto di versione di un Major Release è chiaro anche ai maintainer dei moduli nel livello superiore 2 che si tratta di un aggiornamento funzionale importante e non solo della modifica di una dependency.
Con l’approccio della strategia 2 con Terraform Enterprise la conseguenza sarebbe anche che i Minor Updates, nel caso descritto da v1.3.4 del modulo di servizio a v1.3.5, verrebbero trasmessi in maniera trasparente al livello superiore. Questo comporta ulteriori conseguenze:
- Con Terraform Enterprise e la sua registry privata integrata dei moduli ci si risparmia quindi un inutile lifecycle management nei moduli dipendenti. Ciò riduce l’impegno del personale e i rischi di errore -> valore aggiunto immediato e ulteriore ed è per questo uno degli Enterprise-Features che HashiCorp o IBM fanno pagare.
- Significa anche che bisogna rispettare regole rigorose nella versioning e prestare attenzione: che cos’è esattamente un Minor Update? In cosa si distingue un Minor Update da un Major Update? Serve quindi un piano, ne deriva una struttura definita e una compliance interna nella versioning, non si può più agire come un cowboy allo sbaraglio sparando in aria numeri di versione che sembrano belli. Vedremo come farlo correttamente più avanti nella parte 7 di questa serie di articoli.
La trappola della Rate-of-Change nelle dipendenze dei moduli
Un problema spesso trascurato con i moduli annidati è il rischio cumulativo di cambiamento. Più profonda è la gerarchia dei moduli, più alta è la probabilità di modifiche inattese. Al più tardi con l’entrata in vigore di NIS2 la gestione del rischio diventa obbligatoria, quindi diamo un’occhiata a questo contesto. Usiamo un modello semplificato con calcoli percentuali, non un calcolo del rischio realmente professionale e matematicamente fondato, perché Lei deve capire rapidamente dove vogliamo arrivare con questo tema.
Con una gerarchia piatta è banale definire una frequenza di cambiamento nell’ambito delle policy operative.
Esempio classico: "Abbiamo ogni martedì pomeriggio dalle 15 alle 18 una finestra di manutenzione".
Nella pratica ciò significa che ci potrebbe essere un problema operativo solo ogni martedì pomeriggio (e magari anche il mercoledì). Una volta alla settimana, quindi al massimo 52 volte l’anno (tralasciamo ora fattori come l’impatto e la durata di un’interruzione, il calcolo semplificato è sufficiente).
Sottraendo ora le ferie e le Frozen Zones a Natale e a Pasqua, arriviamo a circa 34 potenziali interruzioni operative. 1 / 34 = 0.0294, cioè abbiamo a che fare con un rischio di circa il 3%.
Con Infrastructure-as-Code e le dipendenze tra moduli la cosa si complica, soprattutto in ambienti caotici alla moda sotto la copertura di una presunta agilità e del Continuous Deployment. Perché lì non basta più il rischio del 3% nella realtà.
Per esempio:
Root Module
├── Probabilità di cambiamento: 10% (rare modifiche all'ambiente)
└── Service Module
├── Probabilità di cambiamento: 30% (Business-Logic-Updates)
└── Base Module
└── Probabilità di cambiamento: 50% (Provider-Updates, Bugfixes)
Probabilità cumulativa di cambiamento = 1 - (0.9 × 0.7 × 0.5) = 68.5%
Con questa gerarchia a tre livelli esiste quindi una probabilità del 68,5% che almeno un componente venga modificato in un determinato periodo.
Ora dovrebbe essere del tutto chiaro che non ci si può più comportare come un tempo James Dean - di fronte a tali cifre deve davvero sapere cosa sta facendo.
Conclusione
Con un po’ di lungimiranza e disciplina si possono quindi evitare anche dal punto di vista operativo potenziali incidenti gravi con i moduli annidati. Come ha visto, si tratta però comunque di un rischio che deve assolutamente essere preso in considerazione nella Sua gestione del rischio.
Nella prossima parte 6c concluderemo questo sotto-tema esaminando ancora alcune pratiche avanzate e raccomandazioni come Policy-as-Code. Grazie per avermi seguito fin qui.
