











In Teil 1 unserer Serie haben wir die grundlegenden Konzepte von Retrieval-Augmented Generation (RAG) kennengelernt und gesehen, wie dieses Framework ähnlich einer digitalen Bibliothek funktioniert. Wir haben die drei Hauptkomponenten - Retriever, Ranker und Generator - im Detail betrachtet und verstanden, wie sie zusammenarbeiten, um präzise und kontextrelevante Antworten zu generieren.
In diesem zweiten Teil tauchen wir tiefer in die technischen Aspekte von RAG ein. Wir werden uns ansehen, wie RAG in der Praxis implementiert wird, welche verschiedenen Modelltypen es gibt und wie sich RAG-erweiterte Systeme von traditionellen Large Language Models (LLMs) unterscheiden.
Die zwei RAG-Modelltypen: Sequence und Token
Bei der Implementierung von RAG gibt es zwei grundlegende Ansätze: RAG-Sequence und RAG-Token. Jeder dieser Ansätze hat seine spezifischen Stärken und eignet sich für unterschiedliche Anwendungsfälle.
RAG-Sequence: Der ganzheitliche Ansatz
RAG-Sequence arbeitet wie ein sorgfältiger Autor, der erst alle relevanten Quellen studiert und dann einen zusammenhängenden Text verfasst. Die mathematische Eleganz dieses Ansatzes liegt in seiner ganzheitlichen Betrachtungsweise:
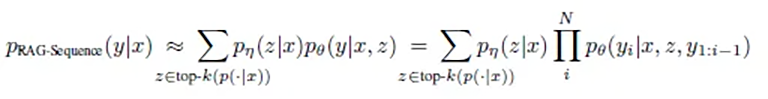
Oder vereinfacht und auf deutsch übersetzt: p(Antwort | Frage) = Summe über alle Dokumente( p(Dokument | Frage) × p(Antwort | Frage, Dokument) )
In einfachen Worten bedeutet dies:
- Das System berechnet für jedes potenziell relevante Dokument zwei Werte:
- Wie wahrscheinlich ist es, dass dieses Dokument für die Frage relevant ist?
- Wie wahrscheinlich ist es, dass dieses Dokument zur korrekten Antwort führt?
- Diese Wahrscheinlichkeiten werden miteinander multipliziert und für alle Dokumente summiert, um die beste Antwort zu finden.
Der technische Prozess läuft dabei wie folgt ab:
- Das System wählt aus einem Index von Millionen Dokumenten die Top-K relevantesten für die Anfrage aus
- Der Generator erstellt für jedes dieser Dokumente eine vollständige potenzielle Antwort
- Diese Antworten werden basierend auf ihrer berechneten Wahrscheinlichkeit zusammengeführt
Die Forschung zeigt, dass dieser Ansatz besonders effektiv ist, wenn es um die Erstellung kohärenter, gut strukturierter Antworten geht. Ein interessantes Detail aus den Studien: Die Qualität der Antworten verbessert sich kontinuierlich, je mehr relevante Dokumente einbezogen werden.
Forschungsergebnisse zeigen, dass RAG-Sequence besonders gut bei Aufgaben abschneidet, die eine konsistente und zusammenhängende Ausgabe erfordern. Die Antworten sind typischerweise vielfältiger und nuancierter als bei anderen Ansätzen.
Dieser Ansatz eignet sich besonders für:
- Zusammenfassungen längerer Texte
- Erstellung von Berichten
- Beantwortung komplexer Fragen, die ein umfassendes Verständnis erfordern
- Aufgaben, die thematische Konsistenz über den gesamten Text hinweg erfordern
RAG-Token: Der granulare Ansatz
RAG-Token arbeitet wie ein gewissenhafter Journalist, der für jeden einzelnen Satz und jedes Wort seiner Story die bestmögliche Quelle konsultiert. Die mathematische Formulierung dieses Ansatzes spiegelt diese Sorgfalt wider:
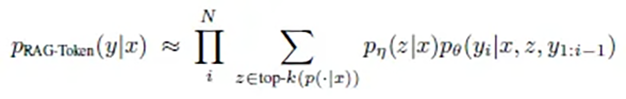
p(Antwort | Frage) = Produkt für jedes Wort( Summe über alle Dokumente( p(Dokument | Frage) × p(Wort | Frage, Dokument, bisherige Wörter) ) )
In der Praxis bedeutet dies:
- Für jedes einzelne Wort der Antwort:
- Werden die relevantesten Dokumente neu evaluiert
- Wird die Wahrscheinlichkeit für jedes mögliche nächste Wort berechnet
- Wird das wahrscheinlichste Wort basierend auf allen verfügbaren Informationen gewählt
- Dieser Prozess wiederholt sich Wort für Wort, wobei jedes neue Wort von:
- Den bisher geschriebenen Wörtern
- Der ursprünglichen Frage
- Den aktuell relevantesten Dokumenten beeinflusst wird
Die Forschung hat gezeigt, dass dieser Ansatz besonders präzise Ergebnisse liefert, wenn es um faktische Genauigkeit geht. Interessanterweise gibt es einen optimalen "Sweetspot" bei der Anzahl der betrachteten Dokumente: Etwa 10 Dokumente pro Token liefern die besten Ergebnisse. Mehr Dokumente führen nicht unbedingt zu besseren Antworten, können aber die Verarbeitungszeit deutlich erhöhen.
Studien haben gezeigt, dass RAG-Token besonders effektiv bei Aufgaben ist, die detaillierte, faktenbasierte Antworten erfordern. Die optimale Anzahl der abgerufenen Dokumente liegt dabei, entsprechend des Sweetspots, typischerweise bei etwa 10 Dokumenten - denn mehr Dokumente verbessern die Ergebnisse nicht zwangsläufig, aber intensivieren die Kosten.
Dieser Ansatz ist optimal für:
- Detaillierte technische Erklärungen
- Faktenbasierte Antworten
- Situationen, die hochspezifische Informationen erfordern
- Fälle, in denen verschiedene Teile der Antwort unterschiedliche Quellen benötigen
Die technische Implementation: Die RAG-Pipeline
Die praktische Umsetzung eines RAG-Systems erfolgt in drei Hauptphasen: Ingestion, Retrieval und Generation. Jede dieser Phasen spielt eine entscheidende Rolle für die Qualität der Endergebnisse.
1. Die Ingestion-Phase
In dieser ersten Phase werden Dokumente in das System eingespeist und für die spätere Verwendung aufbereitet. Die ursprüngliche RAG-Implementierung verwendete etwa einen Wikipedia-Dump mit 21 Millionen Dokumenten, die jeweils in 100-Wort-Chunks aufgeteilt wurden. Der Prozess läuft folgendermaßen ab:
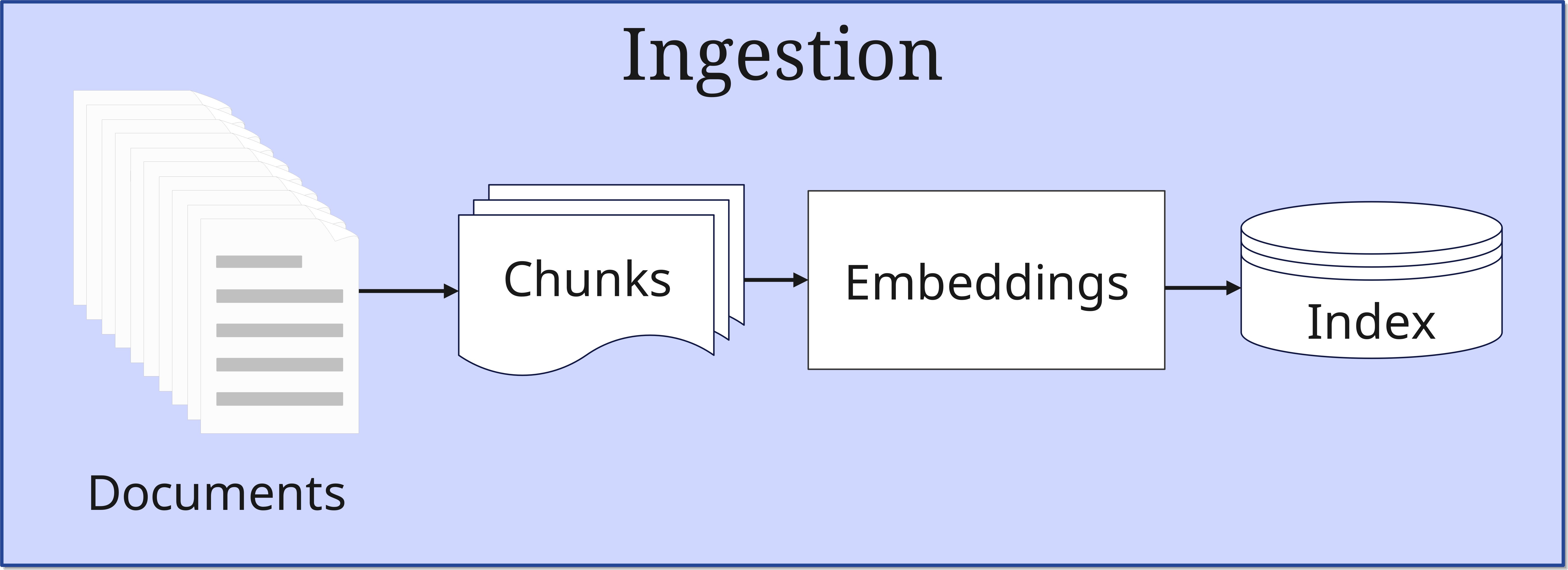
- Dokumentenaufbereitung:
- Dokumente (Documents) werden in kleinere, handhabbare Stücke (Chunks) zerlegt
- Die Chunk-Größe wird basierend auf dem Anwendungsfall optimiert
- Embedding-Generierung:
- Jeder Chunk wird durch einen BERT-basierten Dokumenten-Encoder in einen mathematischen, multidimensionalen Vektor umgewandelt (normalerweise bis zu 1024-dimensional)
- Diese Vektoren erfassen die Semantik des Textes, also nicht den Wortlaut, sondern die Bedeutung (mehr zu Vektoren erfahren wir in einem zukünftigen Artikel über Vektor-Datenbanken)
- Indexierung:
- Die Embeddings werden in einer Vektor-Datenbank gespeichert
- Für die effiziente Suche wird ein MIPS-Index (Maximum Inner Product Search) erstellt
- Technologien wie FAISS ermöglichen dabei eine schnelle, approximative Suche in sublinearer Zeit
Dieser Prozess ist entscheidend für die spätere Effizienz des Systems. Die Kunst liegt darin, die Dokumente so zu zerlegen, dass zusammenhängende Informationen nicht auseinandergerissen werden, aber die Chunks klein genug bleiben, um präzise Ergebnisse zu liefern.
2. Die Retrieval-Phase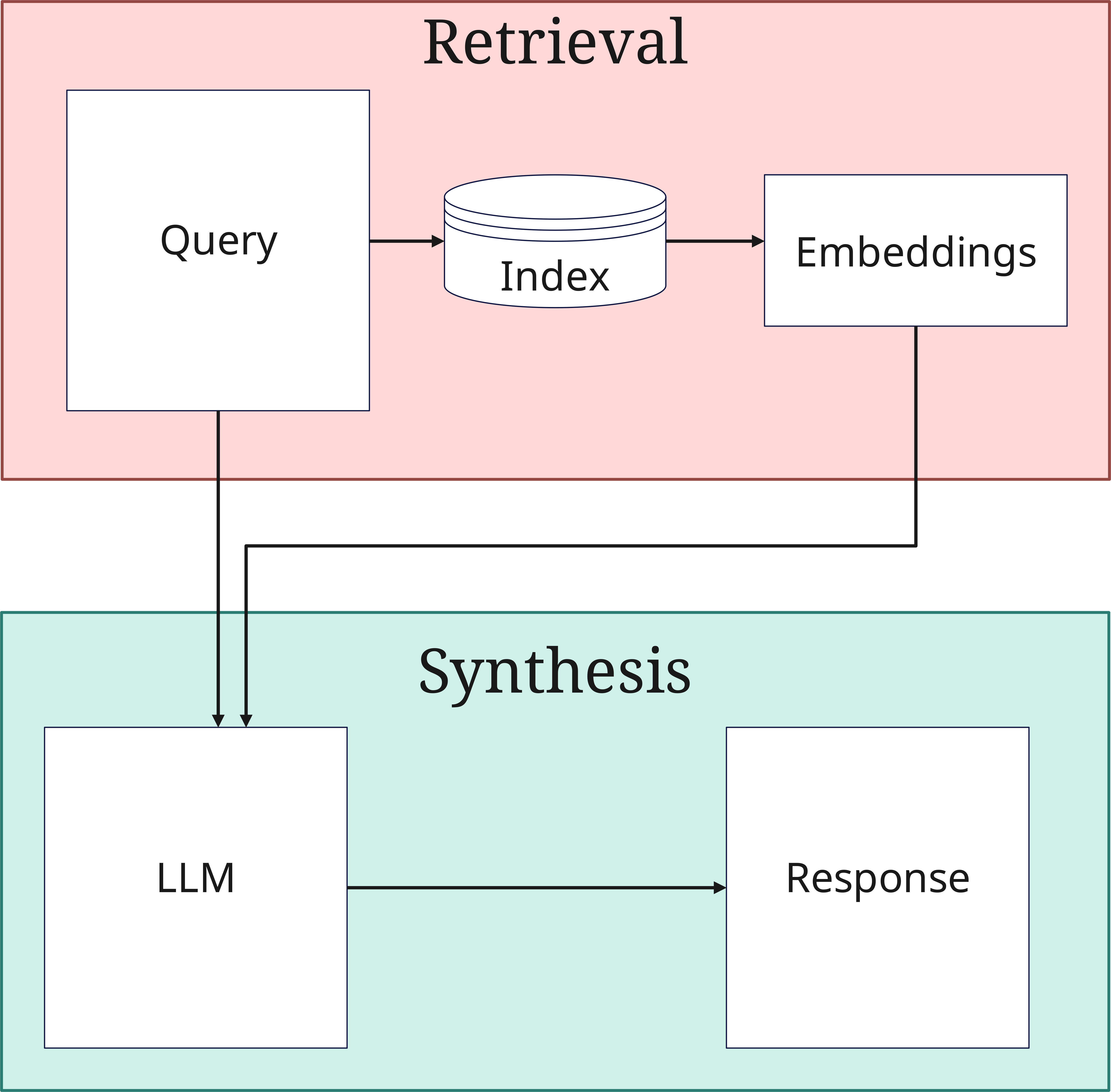
Wenn eine Anfrage eingeht, beginnt die Retrieval-Phase:
- Query-Verarbeitung: Die Anfrage wird ebenfalls in einen Vektor umgewandelt. Diese Anfrage wird vom Retriever sowohl in der Vektor-Datenbank gespeichert als auch im Original direkt weiter zur Synthese der Antwort im Generator geschickt
- Ähnlichkeitssuche: Das System sucht in der Vektor-Datenbank (Index) nach Dokumenten, welche den an die Datenbank übermittelten ähneln. Hier werden die Vektoren der Anfrage mit jenen der indizierten Dokumente verglichen
- Top-K Auswahl: Die relevantesten Dokumente werden ausgewählt
Die Anzahl der ausgewählten Dokumente (Top-K) ist ein wichtiger Parameter, der die Balance zwischen Vollständigkeit und Verarbeitungseffizienz beeinflusst.
3. Die Generation-Phase
In der finalen Phase werden die gefundenen Informationen zu einer Antwort verarbeitet:
- Kontextintegration: Die ausgewählten Top-K-Dokumente werden mit der ursprünglichen Anfrage kombiniert
- Antwortgenerierung: Das LLM erstellt eine kohärente Antwort
- Qualitätssicherung: Die Antwort wird auf Konsistenz und Relevanz geprüft und anschließend ausgegeben
Ein verständliches Beispiel
Schritt 1: Erstellung eines Prompts (Query)
Stellen Sie sich einen Mitarbeiter vor, der an Ihrem Schreibtisch herantritt und Ihnen eine Frage stellt:
"Wir hatten eine Projektidee. Wir wollen xyz machen. Wie sehen hierzu die gesetzlichen Richtlinien aus?"
Diese Anfrage ist ein Prompt.
Begeben Sie sich nun in die Situation der künstlichen Intelligenz. Die Frage ist klar und direkt gestellt. Um sie aber beantworten zu können, benötigen Sie noch mehr Kontext. Also durchsuchen Sie ihre ganze Erinnerung an vorherige Gespräche mit diesem Mitarbeiter und stellen so einen besseren Bezug zum Thema her, was zu einem besseren und umfassenderen Verständnis der Frage führen wird.
All die gefundenen Informationen sind der Kontext. Der Prompt wird jetzt um den Kontext erweitert - die historischen Informationen also sozusagen an die eigentliche Frage des Mitarbeiters angeheftet. Der Prompt wird jetzt hierdurch zu einem sogenannten Enhanced Prompt.
Außerdem stellen Sie sich als Vorgesetzter auch noch die Frage, wie genau die Projektidee ihrem Unternehmen nützt. Sie denken also selbst noch etwas darüber nach, fragen vielleicht noch einmal zurück, und ergänzen den Enhanced Prompt mit den gefundenen Erkenntnissen noch weiter. Allmählich wird die Query damit dann vervollständigt.
Schritt 2: Embedding
Im nächsten Schritt füttern Sie ihre Query in ein Embedding Model, welches es in einen 1024-dimensionalen Vektor umwandelt. Also nicht nur dreidimensional, sondern ein für normale Menschen richtig unvorstellbarer Wert. Durch diese 1024 Dimensionen ist es dann möglich, die Bedeutung der Query einigermaßen genau zu erfassen. Also nicht die einzelnen Worte, sondern den Sinn. Diesen Vektor speichert das Embedding Model jetzt in der Vektor-Datenbank.
Jetzt führt die Vektor-Datenbank eine Ähnlichkeitssuche zu dem Vektor der Query durch. Gefundene Ähnlichkeit eines Dokuments bedeutet, dass dieses vorgemerkt ist. Am Ende der Suche werden dann die besten Ergebnisse ausgewählt und die dazugehörigen Dokumente, Datenbankeinträge, usw. referenziert.
Diese gefundenen Dokumente und anderweitigen Informationen werden jetzt an die Query angehängt. Stellen Sie es sich vor, als ob Sie an eine fertig formulierte E-Mail noch Dokumente anhängen. Aus dem Enhanced Prompt wird damit ein Augmented Prompt.
Schritt 3: Erzeugung einer Antwort
Dieser Augmented Prompt geht jetzt zusammen mit der originalen Query an den Generator, genauer gesagt das involvierte LLM. Das LLM synthetisiert jetzt aus der originalen Anfrage und den ganzen gefundenen Zusatzinformationen eine Antwort. Diese Response geht dann an den Mitarbeiter zurück und dieser ist hoffentlich mit dem Inhalt zufrieden.
Die RAG Triad: Evaluierung der Qualität
Auch wenn ein LLM durch RAG einen Zugang zu den aktuellsten Informationen im Informations-Pool hat und sehr akkurate Antworten geben kann, eliminiert dies nicht das Risiko von Halluzinationen. Dafür gibt es mehrere Gründe:
- Der Retriever sammelt ganz einfach nicht genug Kontext (quantitativ), oder er sammelt falsche Informationen (qualitativ).
- Vielleicht wir die Antwort nicht vollständig vom gesammelten Kontext unterstützt, sondern wurde zu sehr vom LLM und den Trainingsdaten beeinflusst.
- Eine RAG sammelt vielleicht die relevanten Informationen ein und baut darauf eine fundamental richtige Antwort zusammen, aber dann passt die Antwort vielleicht nicht zur eigentlichen Frage.
Um dies zu vermeiden, wurde die RAG Triad entwickelt.
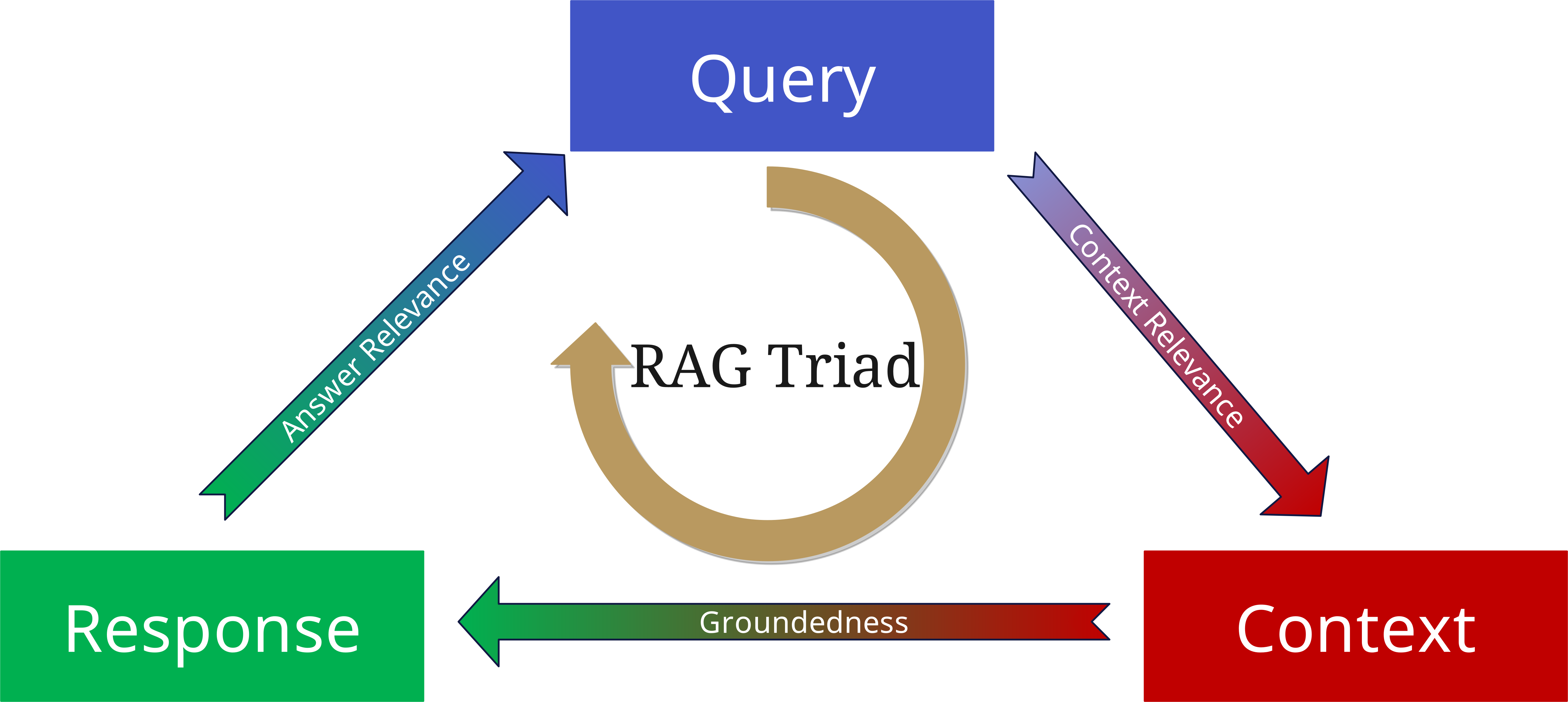
Um die Qualität eines RAG-Systems zu bewerten, betrachten wir drei zentrale Aspekte:
1. Context Relevance (Kontextrelevanz)
- Wie gut passen die abgerufenen Dokumente zur Anfrage?
- Wurde der richtige Kontext gefunden?
- Sind die Informationen aktuell und angemessen?
2. Groundedness (Fundierung)
- Basiert die Antwort tatsächlich auf den abgerufenen Dokumenten?
- Werden Aussagen durch die Quellen gestützt?
- Gibt es Halluzinationen oder unbegründete Schlussfolgerungen?
3. Answer Relevance (Antwortrelevanz)
- Beantwortet die generierte Antwort die ursprüngliche Frage?
- Ist die Antwort vollständig und präzise?
- Ist die Informationstiefe angemessen?
Wenn man diese drei Aspekte noch einmal als Parameter an die Query, den Kontext und die erzeugte Antwort anlegt, kann man Halluzinationen minimieren und RAG-basierte Anwendungen zuverlässiger und belastbarer aufbauen.
LLMs mit und ohne RAG: Ein Vergleich
Traditionelle LLMs und RAG-erweiterte Systeme unterscheiden sich fundamental in ihrer Arbeitsweise:
Traditionelle LLMs
- Basieren ausschließlich auf vortrainiertem Wissen
- Können nicht auf neue oder spezifische Informationen zugreifen
- Sind anfälliger für Halluzinationen
- Haben einen "eingefrorenen" Wissensstand
RAG-erweiterte Systeme
- Kombinieren vortrainiertes Wissen mit externen Quellen
- Können auf aktuelle und spezifische Informationen zugreifen
- Liefern nachvollziehbare, quellenbasierte Antworten
- Sind flexibel erweiterbar
Diese Unterschiede machen RAG zu einer idealen Lösung für Unternehmensanwendungen, wo Präzision, Aktualität und Nachvollziehbarkeit entscheidend sind.
Ausblick auf Teil 3: Die Rolle der Vektordatenbanken
Eine zentrale Komponente, die RAG erst ermöglicht, ist die Vektor-Datenbank. Diese spezialisierten Datenbanken sind optimiert für die Speicherung und Abfrage von Vektoren - den mathematischen Repräsentationen von Text, die das Fundament von RAG bilden.
In Teil 3 unserer Serie werden wir uns intensiv mit Vektordatenbanken beschäftigen:
- Wie funktionieren sie im Detail?
- Welche Arten von Vektor-Datenbanken gibt es?
- Wie wählt man die richtige Vektor-Datenbank für sein Projekt?
- Welche Best Practices gibt es für die Implementation?
Die Vektor-Datenbank ist das Herzstück eines RAG-Systems und verdient daher besondere Aufmerksamkeit. Sie ist der Schlüssel zu effizienter Informationssuche und -verarbeitung und damit entscheidend für die Leistungsfähigkeit des gesamten Systems.
