











Im letzten Artikel haben wir die versteckte Komplexität verschachtelter Module und den Ripple-Effect betrachtet, und dabei ist uns zunehmend bewusst geworden, welche unangenehmen Konsequenzen sich daraus im operativen Betrieb und Lifecycle-Management ergeben können. Man kann solchen Problemen das Einfallstor sperrangelweit öffnen, indem man Anfängerfehler begeht – vor allem den Fehler, mehrere oder gar alle Terraform-Module in ein gemeinsames Git-Repository zu stopfen. Ebenso kann man mit ein wenig Seniorität und sauberer Planung derartige Probleme aber von vornherein minimieren.
Lassen Sie uns in diesem Teil einen Blick darauf werfen, wie man in der Praxis mit solchen Abhängigkeiten umgehen kann, ohne dass die Schmerzen überhandnehmen.
Praktische Lösungsansätze für Modulversionsverfolgung
Grundvoraussetzung ist hier diese goldene Regel:
- Bei Verwendung der freien, kostenlosen Version von Terraform bekommt jedes Terraform-Modul IMMER sein eigenes Git-Repository und wird IMMER individuell über Tags versioniert.
- Bei Terraform Enterprise wird die interne Modul-Registry benutzt. Dies erlaubt Version Constraints wie wir sie von den Provider-Blöcken her kennen, also Einschränkungen mittels Operatoren wie "=", "<=", ">=", "~>".
Warum will man das?
Betrachten wir ein reales Beispiel aus der OCI-Welt. Stellen Sie sich ein Basis-Modul vor, dessen neuestes Update die Funktionalität der abhängigen Module brechen würde:
# Base Module: base/oci-compute v1.2.0
variable "freeform_tags" {
type = map(string)
default = {}
description = "Freeform tags for cost allocation"
# NEW in v1.2.0: Mandatory CostCenter Tag
validation {
condition = can(var.freeform_tags["CostCenter"])
error_message = "CostCenter tag is required for all compute instances."
}
}
resource "oci_core_instance" "this" {
for_each = var.instances
display_name = each.value.name
compartment_id = var.compartment_id
freeform_tags = var.freeform_tags
# ... etc.
}
Das Service-Modul web-application v1.3.4 wurde jedoch vor diesem Breaking Change entwickelt:
# Service Module: services/web-application v1.3.4
module "compute_instances" { source = "git::https://gitlab.ict.technology/modules//base/oci-compute" instances = { web1 = { name = "web-server-1" } web2 = { name = "web-server-2" } } compartment_id = var.compartment_id # freeform_tags missing - Breaking Change! }
Wenn man das so macht, dann knallt’s, wie im vorherigen Teil 6a dieser Artikelserie beschrieben.
Strategie 1 (Terraform): Explizites Pinnen der Versionen von Service- und Basismodulen
Basis-Module sind die Module, welche einen Provider benutzen und Ressourcen verwalten. Sie haben stets ihr eigenes individuelles Repository und sind immer versioniert.
Auf Service-Module trifft das auch zu. Service-Module ziehen nur Basis-Module an, sie implementieren keine Ressourcen. Beim Anziehen der Basis-Module sollen die Service-Module deren Version aber explizit pinnen. Erst dann können transitive Upgrades kontrolliert stattfinden.
Mit Root-Modulen verhält es sich ähnlich. Diese ziehen Service-Module an und pinnen deren Versionen exakt.
Ziehen wir daher noch einmal unser Beispiel eines Service-Moduls aus dem letzten Absatz heran:
# Service-Module: services/web-application v1.3.5
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
instances = {
web1 = { name = "web-server-1" }
web2 = { name = "web-server-2" }
}
compartment_id = var.compartment_id
# freeform_tags missing - Breaking Change!
}
Sehen Sie den Unterschied? Anstelle von
source = "git::https://gitlab.ict.technology/modules//base/oci-compute"
pinnen wir jetzt die exakte Version des Basismoduls:
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
Und hierdurch tut der Change im Basis-Modul niemand im laufenden Betrieb weh.
Was aber immer noch Schmerzen verursachen kann, ist wenn in einem größeren Service-Modul oder einem Root-Modul ein Modulaufruf mehrfach vorkommt und dann verschiedene Versionen angezogen werden. Das wird nicht gut gehen. Man kommt nicht um die Entscheidung herum, welche Version eines Moduls man anziehen möchte.
Denn es ist leider so, dass doppeltes oder inkonsistentes Pinnen innerhalb eines Root-Moduls (gleiche Basismodule in unterschiedlichen Versionen) nicht automatisch von Terraform erkannt wird. Terraform validiert ausschließlich die Auflösung einzelner source-Angaben, nicht die globale Konsistenz über mehrere Aufrufe hinweg.
Hier stelle ich Ihnen mit check-module-dependencies.sh ein Skript zur Verfügung, welches Sie gerne als Inspiration und im nichtkommerziellen Rahmen einsetzen dürfen. Aufgrund seiner Länge von fast 200 Zeilen zeige ich hier nicht das Skript selbst, sondern gebe Ihnen einen Link zum Git-Repository: https://github.com/ICT-technology/check-module-dependencies/
Das Skript analysiert ein Root- oder Service-Modul und prüft die Versionsnummern der darin angezogenen Module. Wenn alles gut läuft, produziert es eine Ausgabe wie diese:
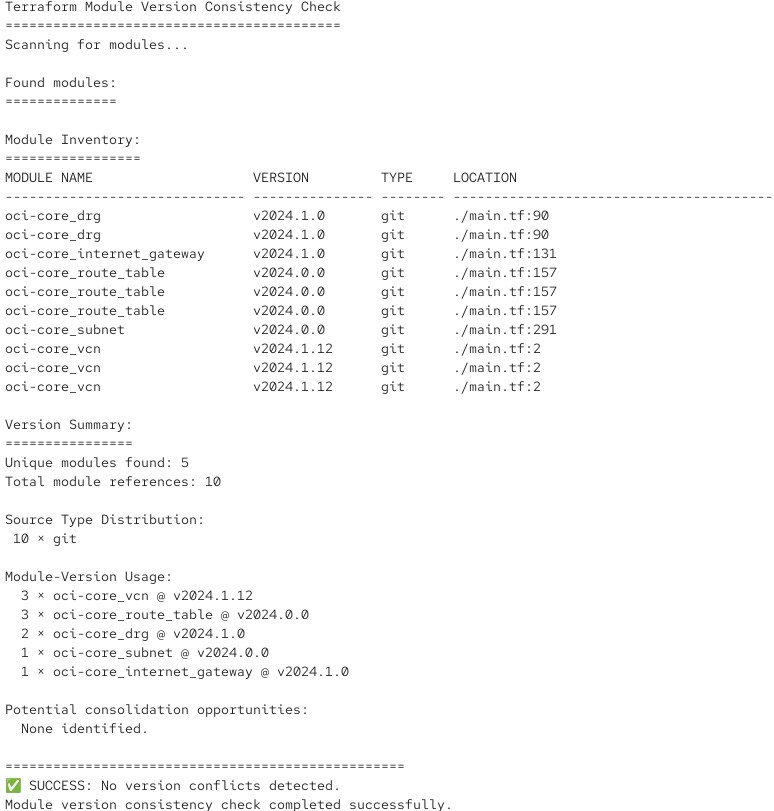
Und falls es feststellt, dass Versionskonflikte auftreten würden, gibt es eine entsprechende Fehlermeldung mit return code:
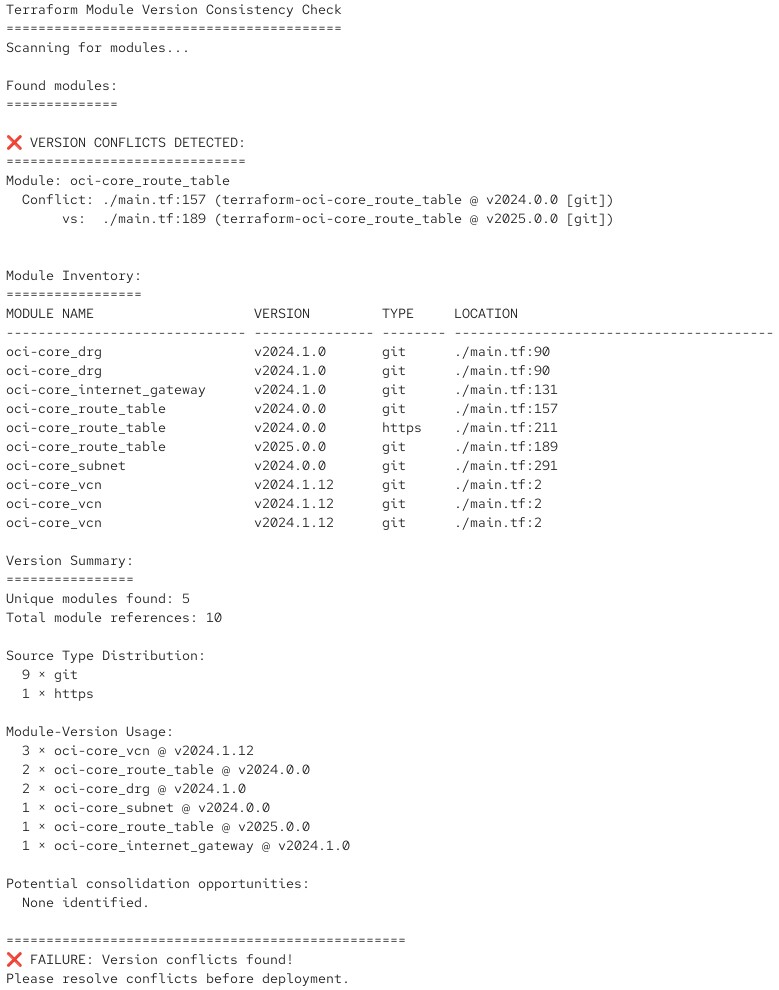
Sie können ein solches Skript in Ihre CI/CD-Pipeline der Testumgebung einbauen und die Prüfung somit automatisieren.
Einfacher wird es mit Strategie 2.
Strategie 2 (Terraform Enterprise): Semantic Versioning mit Ranges
Bei Terraform Enterprise wird es einfach (und wesentlich professioneller). Dort sollten Sie die integrierte Private Module Registry für echtes Semantic Versioning benutzen, so wie Sie es bereits mit der Versionierung von Providern tun, nur eben als Teil eines Modulaufrufs:
# Terraform Enterprise on-prem and HCP Terraform only
module "web_service" { source = "registry.ict.technology/ict-technology/web-application/oci" version = "~> 1.1.0" # Permits 1.1.0, 1.1.1, 1.1.2 ... 1.1.x, but NOT 1.0.x or 1.2.x environment = "production" }
So sieht es dann in der Praxis aus
Wenn in dieser Konstellation ein Basis-Modul oder ein Service-Modul gepatcht wird und eine neue Versionsnummer erhält, ändert dies dann nicht an der Funktionsfähigkeit ihres Root-Moduls und der Pipeline. Holen wir noch einmal diese Illustration des vorherigen Kapitels hervor:
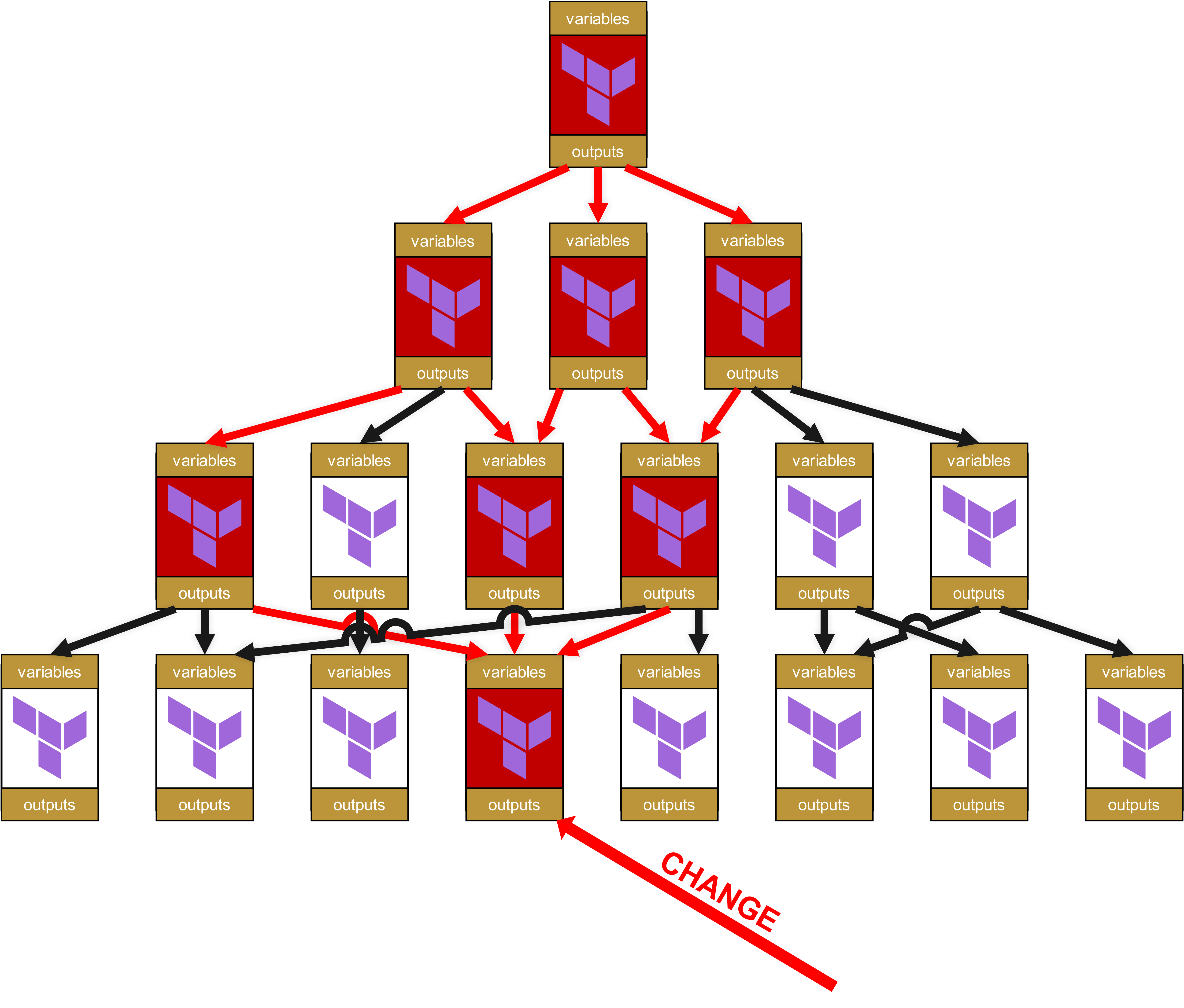
Sie sehen hier die vier Schichten. Oben ist Schicht 1, und unten in Schicht 4 gibt es einen Change. Deshalb erhält das Modul in Schicht 4 eine neue Versionsnummer, zum Beispiel ein Upgrade von v1.1.0 auf v1.2.0.
Aber weil die Module in Schicht 3 die Version v1.1.0 noch gepinnt haben, hat die neue v1.2.0 keine Auswirkung. Erst müssen die Module in Schicht 3 erfolgreich getestet werden. Nun gibt es bei den Tests zwei mögliche Szenarien:
- Die Service-Module auf Schicht 3 funktionieren nach wie vor tadellos -> das Pinning des Basismoduls wird von v1.1.0 auf v1.2.0 angehoben und die Service-Module auf ein neues Minor Release angehoben, z.B. von v1.3.4 auf v1.3.5.
- Die Service-Module auf Schicht 3 funktionieren nicht mehr tadellos. Das heißt, im Basis-Modul v1.2.0 gab es einen Breaking Change. Deshalb werden die betroffenen Service-Module auf Schicht 3 entsprechend gepatcht und neu versioniert, dieses Mal aber als Major Release, zum Beispiel von v1.3.4 auf v1.4.0. Durch diesen Versionssprung eines Major Releases ist den Maintainern der Module auf der darüber liegenden Schicht 2 dann auch klar, dass es ein wichtiges funktionales Update ist und nicht nur die Änderung einer Dependency.
Beim Strategieansatz 2 mit Terraform Enterprise wäre die Folge dann auch, dass Minor Updates, im beschriebenen Fall von v1.3.4 des Service-Moduls auf v1.3.5, dann transparent zur darüber liegenden Schicht durchgereicht werden. Das hat dann auch wieder Konsequenzen:
- Bei Terraform Enterprise mit seiner integrierten privaten Module Registry erspart man sich also unnötiges Lifecycle-Management in abhängigen Modulen. Das reduziert personellen Aufwand und Fehlerrisiken -> unmittelbarer, zusätzlicher Mehrwert und deshalb eines der Enterprise-Features, welches sich HashiCorp bzw. IBM bezahlen lässt.
- Das bedeutet ebenso, dass man bei der Versionierung strikte Regeln einhalten und aufpassen muss: Was genau ist ein Minor Update? Wie unterscheidet sich ein Minor Update von einem Major Update? Man braucht also einen Plan, daraus folgend eine definierte Struktur und interne Compliance bei der Versionierung, man kann nicht mehr wie ein Cowboy auf der grünen Wiese herumreiten und cool aussehende Versionsnummern in die Luft ballern. Wie man das richtig macht, schauen wir uns später in Teil 7 dieser Artikelserie an.
Die Rate-of-Change-Falle bei Modulabhängigkeiten
Ein oft übersehenes Problem bei verschachtelten Modulen ist das kumulative Änderungsrisiko. Je tiefer die Modulhierarchie, desto höher die Wahrscheinlichkeit unerwarteter Änderungen. Spätestens mit dem Eintreten von NIS2 wird ein Risikomanagement obligatorisch, also schauen wir uns das in diesem Kontext kurz an. Wir benutzen ein vereinfachtes Modell mit Prozentrechnung, keine wirklich professionelle und mathematisch belastbare Risikoberechnung, denn Sie sollen ja schnell verstehen, worauf es bei diesem Thema hinausläuft.
Bei einer flachen Hierarchie ist es trivial, eine Änderungshäufigkeit im Rahmen der operativen Richtlinien vorzugeben.
Klassisches Beispiel: "Wir haben jeden Dienstagnachmittag von 15 Uhr bis 18 Uhr ein Wartungsfenster".
In der Praxis bedeutet das dann, dass es nur jeden Dienstagnachmittag (und vielleicht noch Mittwochs) ein Problem im Betrieb geben könnte. Einmal pro Woche, also maximal 52-mal im Jahr (Faktoren wie die Auswirkungen und Länge eines Ausfalls lassen wir jetzt außen vor, die Milchmädchenrechnung reicht).
Ziehen wir jetzt noch Ferien und Frozen Zones an Weihnachten und Ostern ab, kommen wir bei etwa 34 potenziellen Betriebsstörungen heraus. 1 / 34 = 0.0294, d.h. wir haben es mit einem Risiko von etwa 3% zu tun.
Bei Infrastructure-as-Code mit Modulabhängigkeiten wird das aber etwas komplizierter, vorwiegend in hippen Chaos-Umgebungen unter dem Deckmäntelchen von angeblicher Agilität und Continuous Deployment. Denn da ist es mit 3% Risiko dann in der Realität nicht mehr getan.
Zum Beispiel:
Root Module
├── Änderungswahrscheinlichkeit: 10% (seltene Environment-Änderungen)
└── Service Module
├── Änderungswahrscheinlichkeit: 30% (Business-Logic-Updates)
└── Base Module
└── Änderungswahrscheinlichkeit: 50% (Provider-Updates, Bugfixes)
Kumulative Änderungswahrscheinlichkeit = 1 - (0.9 × 0.7 × 0.5) = 68.5%
Bei dieser dreistufigen Hierarchie besteht also eine 68,5%ige Chance, dass mindestens eine Komponente in einem gegebenen Zeitraum geändert wird.
Jetzt sollte wirklich gänzlich klar sein, dass man nicht mehr wie einst James Dean vorgehen darf – angesichts solcher Zahlen müssen Sie wirklich wissen, was Sie tun.
Fazit
Mit etwas Weitsicht und Disziplin lassen sich potenziell brutale Incidents mit verschachtelten Modulen also auch aus operativer Sicht vermeiden. Wie Sie gesehen haben, ist dies aber dennoch ein Risiko, welches Sie unbedingt in Ihrem Risikomanagement berücksichtigen müssen.
Im nächsten Teil 6c schließen wir dieses Unterthema dann ab, indem wir noch ein paar fortgeschrittene Praktiken und empfohlene Vorgehensweisen wie Policy-as-Code anschauen. Danke, dass Sie mich bis hierher begleitet haben.
