











Dans l’article précédent, nous avons examiné la complexité cachée des modules imbriqués et l’effet domino, et nous avons pris conscience des conséquences désagréables que cela peut entraîner dans l’exploitation et le lifecycle-management. On peut ouvrir toute grande la porte à ce type de problèmes en commettant des erreurs de débutant – surtout l’erreur de regrouper plusieurs, voire tous les modules Terraform dans un dépôt Git commun. Avec un peu plus de séniorité et une planification soignée, on peut cependant minimiser ces problèmes dès le départ.
Voyons dans cette partie comment gérer ces dépendances en pratique, sans que la douleur ne devienne insupportable.
Approches pratiques pour le suivi de versions des modules
La condition de base est cette règle d’or :
- Lors de l’utilisation de la version libre et gratuite de Terraform, chaque module Terraform reçoit TOUJOURS son propre dépôt Git et est TOUJOURS versionné individuellement via des tags.
- Avec Terraform Enterprise, on utilise le registre interne de modules. Cela permet d’appliquer des Version Constraints comme nous les connaissons des blocs Provider, c’est-à-dire des restrictions à l’aide d’opérateurs tels que "=", "<=", ">=", "~>".
Pourquoi vouloir cela ?
Considérons un exemple réel issu du monde OCI. Imaginez un module de base dont la dernière mise à jour casserait la fonctionnalité des modules dépendants :
# Base Module: base/oci-compute v1.2.0
variable "freeform_tags" {
type = map(string)
default = {}
description = "Freeform tags for cost allocation"
# NEW in v1.2.0: Mandatory CostCenter Tag
validation {
condition = can(var.freeform_tags["CostCenter"])
error_message = "CostCenter tag is required for all compute instances."
}
}
resource "oci_core_instance" "this" {
for_each = var.instances
display_name = each.value.name
compartment_id = var.compartment_id
freeform_tags = var.freeform_tags
# ... etc.
}
Cependant, le module de service web-application v1.3.4 a été développé avant ce Breaking Change :
# Service Module: services/web-application v1.3.4
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute"
instances = {
web1 = { name = "web-server-1" }
web2 = { name = "web-server-2" }
}
compartment_id = var.compartment_id
# freeform_tags missing - Breaking Change!
}
Si l’on procède ainsi, ça casse, comme décrit dans la partie 6a précédente de cette série d’articles.
Stratégie 1 (Terraform) : Pinning explicite des versions des modules de service et de base
Les modules de base sont ceux qui utilisent un Provider et gèrent des ressources. Ils ont toujours leur propre dépôt individuel et sont toujours versionnés.
Il en va de même pour les modules de service. Les modules de service n’attirent que des modules de base, ils n’implémentent pas de ressources. Lorsqu’ils appellent les modules de base, les modules de service doivent cependant pinner explicitement leur version. Ce n’est qu’à ce moment-là que les mises à jour transitives peuvent être contrôlées.
Il en va de façon similaire pour les modules Root. Ceux-ci appellent les modules de service et pinnent exactement leurs versions.
Reprenons donc notre exemple d’un module de service du paragraphe précédent :
# Service-Module: services/web-application v1.3.5
module "compute_instances" {
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
instances = {
web1 = { name = "web-server-1" }
web2 = { name = "web-server-2" }
}
compartment_id = var.compartment_id
# freeform_tags missing - Breaking Change!
}
Voyez-vous la différence ? Au lieu de
source = "git::https://gitlab.ict.technology/modules//base/oci-compute"
nous pinnons maintenant la version exacte du module de base :
source = "git::https://gitlab.ict.technology/modules//base/oci-compute?ref=v1.1.0"
Et grâce à cela, la modification dans le module de base ne fait mal à personne en exploitation.
Ce qui peut cependant encore poser problème, c’est lorsqu’un appel de module est présent plusieurs fois dans un module de service plus grand ou dans un module Root, et que différentes versions sont alors appelées. Cela ne fonctionnera pas bien. Il faut prendre une décision quant à la version d’un module que l’on souhaite utiliser.
Car malheureusement, le double pinning ou le pinning incohérent à l’intérieur d’un module Root (mêmes modules de base en différentes versions) n’est pas automatiquement détecté par Terraform. Terraform valide uniquement la résolution des références source individuelles, pas la cohérence globale entre plusieurs appels.
Je mets ici à votre disposition le script check-module-dependencies.sh, que vous pouvez utiliser comme source d’inspiration et dans un cadre non commercial. En raison de sa longueur de près de 200 lignes, je ne montre pas le script lui-même ici, mais je vous donne un lien vers le dépôt Git : https://github.com/ICT-technology/check-module-dependencies/
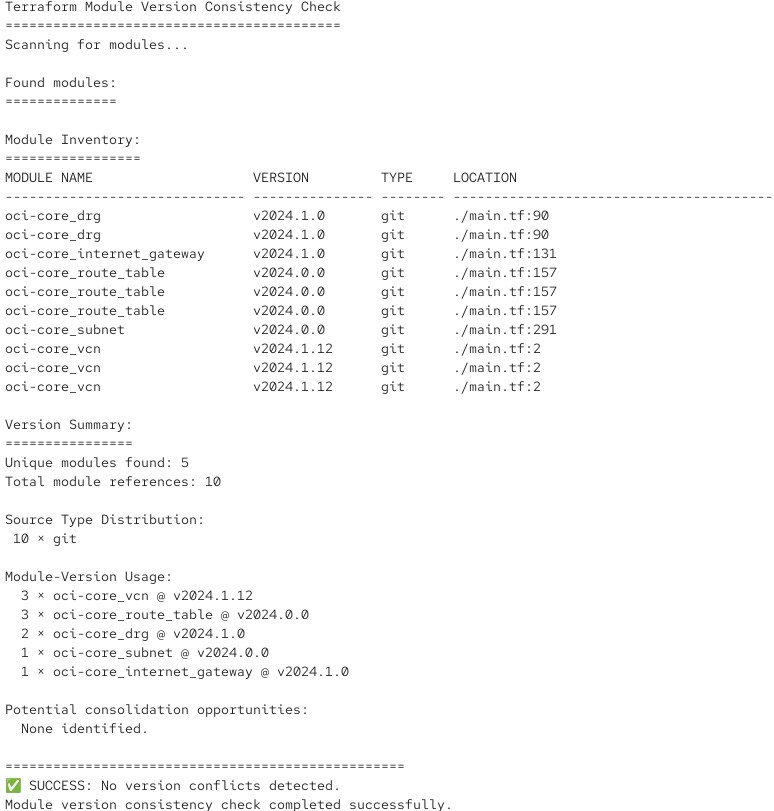
Le script analyse un module Root ou de service et vérifie les numéros de version des modules appelés. Si tout va bien, il produit une sortie comme celle-ci :
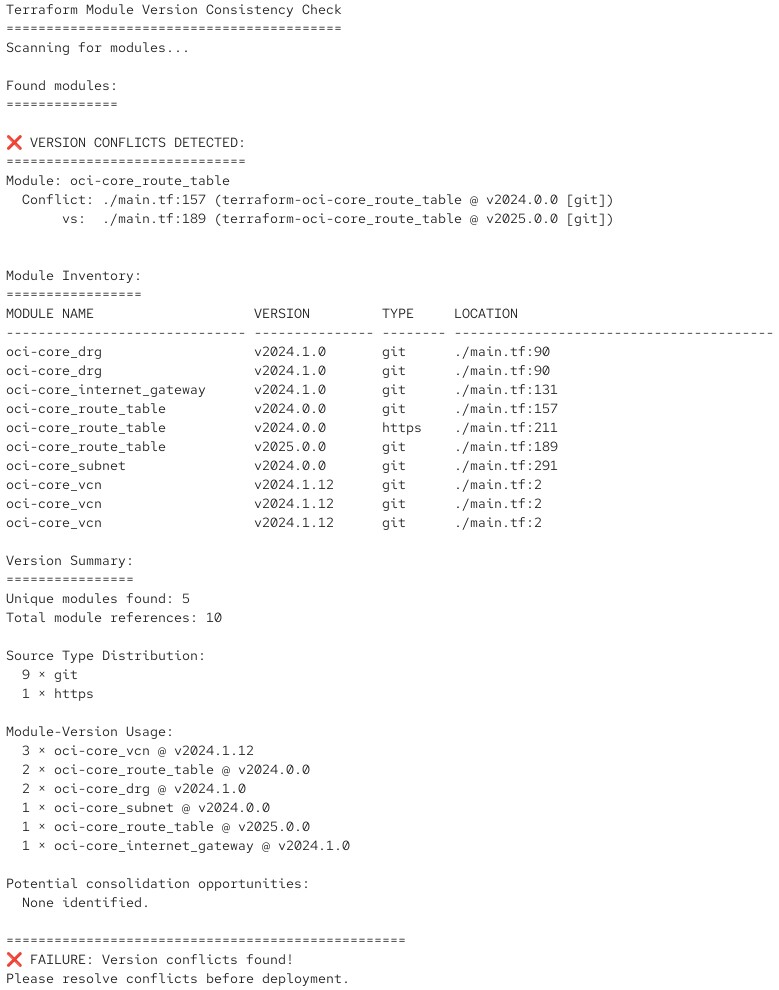
Et s’il détecte que des conflits de version surviendraient, il renvoie un message d’erreur correspondant avec un code retour :
Vous pouvez intégrer un tel script dans votre pipeline CI/CD de l’environnement de test et ainsi automatiser la vérification.
Cela devient plus simple avec la stratégie 2.
Stratégie 2 (Terraform Enterprise) : Semantic Versioning avec Ranges
Avec Terraform Enterprise, les choses deviennent simples (et nettement plus professionnelles). Vous devriez y utiliser le registre privé de modules intégré pour un vrai Semantic Versioning, comme vous le faites déjà pour la version des Providers, mais cette fois comme partie d’un appel de module :
# Terraform Enterprise on-prem and HCP Terraform only
module "web_service" { source = "registry.ict.technology/ict-technology/web-application/oci" version = "~> 1.1.0" # Permits 1.1.0, 1.1.1, 1.1.2 ... 1.1.x, but NOT 1.0.x or 1.2.x environment = "production" }
Voilà à quoi cela ressemble en pratique
Si, dans cette configuration, un module de base ou un module de service est patché et reçoit un nouveau numéro de version, cela ne change rien au bon fonctionnement de votre module Root et de la pipeline. Reprenons encore une fois cette illustration du chapitre précédent :
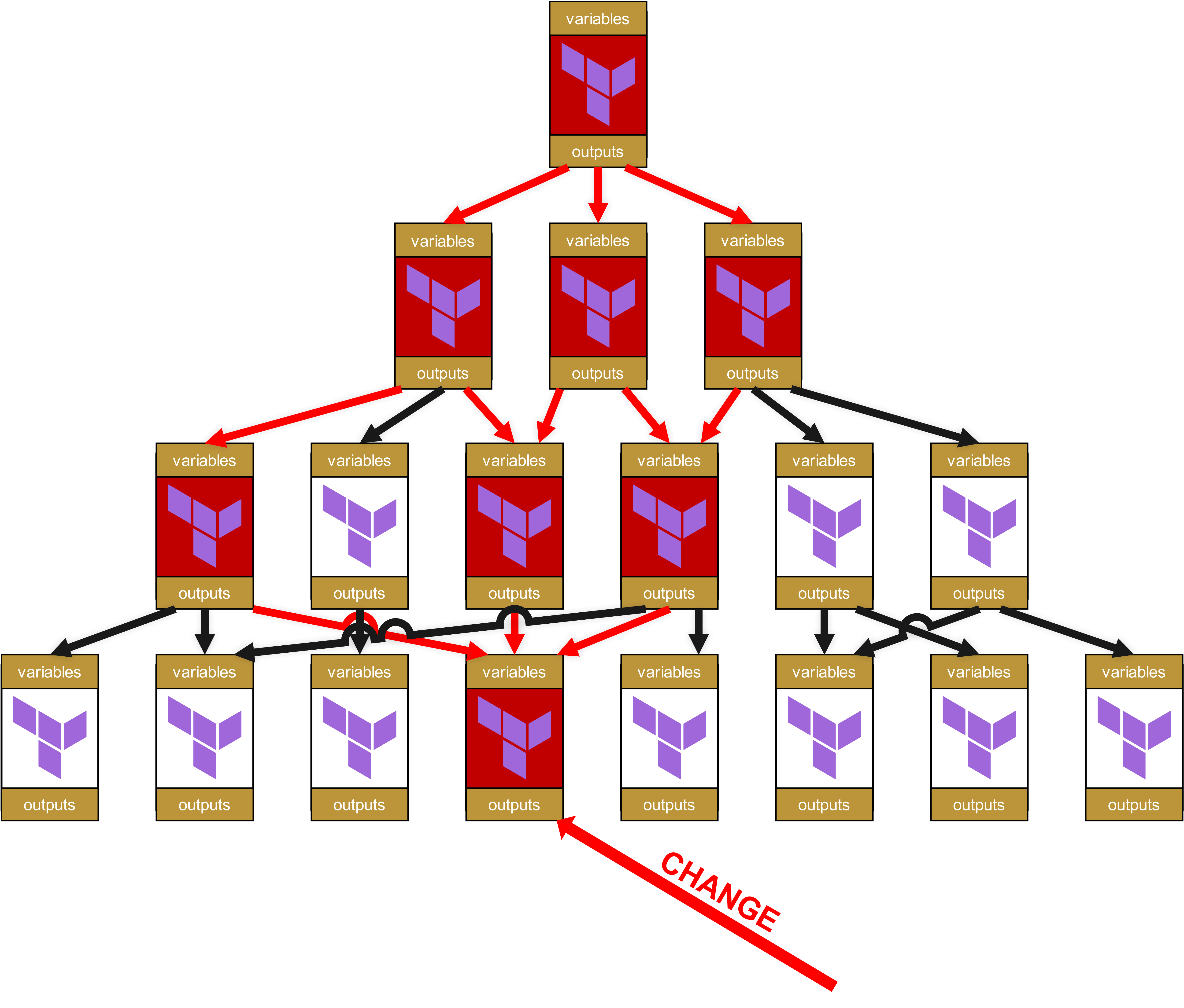
Vous voyez ici les quatre couches. En haut se trouve la couche 1, et en bas, dans la couche 4, il y a un changement. C’est pourquoi le module de la couche 4 reçoit un nouveau numéro de version, par exemple un passage de v1.1.0 à v1.2.0.
Mais comme les modules de la couche 3 ont encore pinné la version v1.1.0, la nouvelle v1.2.0 n’a aucun impact. Les modules de la couche 3 doivent d’abord être testés avec succès. Lors de ces tests, deux scénarios sont possibles :
- Les modules de service de la couche 3 continuent de fonctionner parfaitement -> le pinning du module de base est relevé de v1.1.0 à v1.2.0 et les modules de service sont augmentés vers un nouveau Minor Release, par ex. de v1.3.4 à v1.3.5.
- Les modules de service de la couche 3 ne fonctionnent plus correctement. Cela signifie que le module de base v1.2.0 contenait un Breaking Change. Les modules de service concernés de la couche 3 sont donc patchés et reversionnés, mais cette fois en tant que Major Release, par exemple de v1.3.4 à v1.4.0. Par ce saut de version en Major Release, les mainteneurs des modules de la couche supérieure (couche 2) comprennent immédiatement qu’il s’agit d’une mise à jour fonctionnelle importante et pas seulement d’une modification d’une dépendance.
Avec l’approche de la stratégie 2 sous Terraform Enterprise, la conséquence serait aussi que les Minor Updates, dans le cas décrit de v1.3.4 du module de service vers v1.3.5, sont propagés de manière transparente vers la couche supérieure. Cela entraîne également des conséquences :
- Avec Terraform Enterprise et son registre privé intégré de modules, on s’épargne donc un lifecycle-management inutile dans les modules dépendants. Cela réduit la charge en personnel et les risques d’erreurs -> valeur ajoutée directe et supplémentaire , ce qui explique pourquoi HashiCorp ou IBM font payer cette fonctionnalité Enterprise.
- Cela signifie également que vous devez respecter des règles strictes de versioning et faire attention : Qu’est-ce exactement qu’un Minor Update ? Quelle est la différence entre un Minor Update et un Major Update ? Il faut donc un plan, une structure définie et une compliance interne dans le versioning. On ne peut plus agir comme un cowboy dans la prairie en lançant au hasard des numéros de version qui sonnent bien. Nous verrons comment faire cela correctement dans la partie 7 de cette série d’articles.
Le piège du Rate-of-Change dans les dépendances de modules
Un problème souvent sous-estimé avec les modules imbriqués est le risque cumulatif de changement. Plus la hiérarchie de modules est profonde, plus la probabilité de changements inattendus est élevée. Avec l’entrée en vigueur de NIS2, la gestion des risques devient obligatoire, alors examinons rapidement ce point dans ce contexte. Nous utilisons un modèle simplifié avec un calcul en pourcentage, pas une évaluation des risques vraiment professionnelle et mathématiquement robuste, car l’objectif est que vous compreniez rapidement l’essentiel du sujet.
Dans une hiérarchie plate, il est trivial de définir une fréquence de changement dans le cadre des politiques opérationnelles.
Exemple classique : "Nous avons chaque mardi après-midi de 15h à 18h une fenêtre de maintenance".
En pratique, cela signifie qu’il ne pourrait y avoir un problème en exploitation que chaque mardi après-midi (et peut-être encore le mercredi). Une fois par semaine, donc au maximum 52 fois par an (nous laissons de côté des facteurs comme l’impact et la durée d’une panne, ce calcul simpliste suffit ici).
Si l’on soustrait encore les périodes de congés et les Frozen Zones à Noël et à Pâques, on arrive à environ 34 perturbations potentielles d’exploitation. 1 / 34 = 0,0294, ce qui signifie que nous avons affaire à un risque d’environ 3%.
Avec l’Infrastructure-as-Code et les dépendances de modules, les choses deviennent cependant plus compliquées, surtout dans des environnements branchés et chaotiques sous couvert d’une prétendue agilité et de Continuous Deployment. Dans ce cas, le risque réel n’est plus de 3%.
Par exemple :
Root Module
├── Probabilité de changement : 10% (changements d’environnement rares)
└── Service Module
├── Probabilité de changement : 30% (mises à jour de la logique métier)
└── Base Module
└── Probabilité de changement : 50% (Provider-Updates, Bugfixes)
Probabilité de changement cumulée = 1 - (0,9 × 0,7 × 0,5) = 68,5%
Dans cette hiérarchie à trois niveaux, il y a donc 68,5% de chances qu’au moins un composant soit modifié dans une période donnée.
Il devrait maintenant être tout à fait clair qu’on ne peut plus agir comme James Dean autrefois - face à de tels chiffres, vous devez vraiment savoir ce que vous faites.
Conclusion
Avec un peu de prévoyance et de discipline, on peut donc éviter, même d’un point de vue opérationnel, des incidents potentiellement brutaux liés aux modules imbriqués. Comme vous l’avez vu, il s’agit toutefois d’un risque que vous devez absolument intégrer dans votre gestion des risques.
Dans la prochaine partie 6c, nous conclurons ce sous-thème en examinant encore quelques pratiques avancées et recommandations comme Policy-as-Code. Merci de m’avoir accompagné jusqu’ici.
