











Dans la première partie de notre série, nous avons découvert les concepts fondamentaux du Retrieval-Augmented Generation (RAG) et observé comment ce framework fonctionne de manière similaire à une bibliothèque numérique. Nous avons examiné en détail les trois composants principaux - Retriever, Ranker et Generator - et compris comment ils collaborent pour générer des réponses précises et contextuellement pertinentes.
Dans cette deuxième partie, nous plongeons plus profondément dans les aspects techniques du RAG. Nous examinerons comment le RAG est implémenté dans la pratique, quels sont les différents types de modèles et comment les systèmes enrichis par RAG se distinguent des Large Language Models (LLMs) traditionnels.
Les deux types de modèles RAG : Sequence et Token
Il existe deux approches fondamentales dans l'implémentation du RAG : RAG-Sequence et RAG-Token. Chacune de ces approches possède ses forces spécifiques et convient à différents cas d'utilisation.
RAG-Sequence : L'approche holistique
RAG-Sequence fonctionne comme un auteur minutieux qui étudie d'abord toutes les sources pertinentes avant de rédiger un texte cohérent. L'élégance mathématique de cette approche réside dans sa perspective holistique :
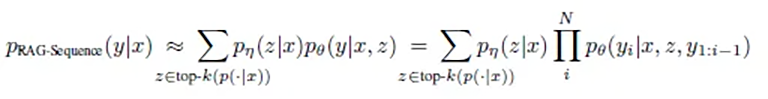
Ou simplifié et traduit : p(réponse | question) = somme sur tous les documents( p(document | question) × p(réponse | question, document) )
En termes simples, cela signifie :
- Le système calcule deux valeurs pour chaque document potentiellement pertinent :
- Quelle est la probabilité que ce document soit pertinent pour la question ?
- Quelle est la probabilité que ce document conduise à la bonne réponse ?
- Ces probabilités sont multipliées et sommées pour tous les documents afin de trouver la meilleure réponse.
Le processus technique se déroule comme suit :
- Le système sélectionne les Top-K documents les plus pertinents pour la requête parmi un index de millions de documents
- Le Generator crée une réponse potentielle complète pour chacun de ces documents
- Ces réponses sont fusionnées en fonction de leur probabilité calculée
La recherche montre que cette approche est particulièrement efficace pour la création de réponses cohérentes et bien structurées. Un détail intéressant des études : la qualité des réponses s'améliore continuellement avec l'inclusion de plus de documents pertinents.
Les résultats de recherche montrent que RAG-Sequence performe particulièrement bien dans les tâches nécessitant une sortie cohérente et consistante. Les réponses sont typiquement plus diverses et nuancées que dans d'autres approches.
Cette approche convient particulièrement pour :
- Les résumés de textes longs
- La création de rapports
- La réponse à des questions complexes nécessitant une compréhension globale
- Les tâches nécessitant une cohérence thématique sur l'ensemble du texte
RAG-Token : L'approche granulaire
RAG-Token fonctionne comme un journaliste consciencieux qui consulte la meilleure source possible pour chaque phrase et chaque mot de son article. La formulation mathématique de cette approche reflète cette minutie :
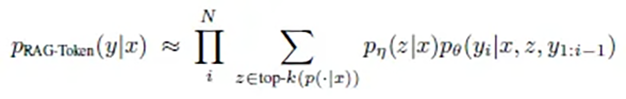
p(réponse | question) = produit pour chaque mot( somme sur tous les documents( p(document | question) × p(mot | question, document, mots précédents) ) )
En pratique, cela signifie :
- Pour chaque mot individuel de la réponse :
- Les documents les plus pertinents sont réévalués
- La probabilité pour chaque mot suivant possible est calculée
- Le mot le plus probable est choisi sur la base de toutes les informations disponibles
- Ce processus se répète mot par mot, chaque nouveau mot étant influencé par :
- Les mots déjà écrits
- La question initiale
- Les documents actuellement les plus pertinents
La recherche a démontré que cette approche fournit des résultats particulièrement précis en ce qui concerne la précision factuelle. Il est intéressant de noter qu'il existe un "sweetspot" optimal dans le nombre de documents considérés : environ 10 documents par token donnent les meilleurs résultats. Plus de documents n'améliorent pas nécessairement les réponses, mais peuvent augmenter significativement le temps de traitement.
Les études ont montré que RAG-Token est particulièrement efficace pour les tâches nécessitant des réponses détaillées et factuelles. Le nombre optimal de documents récupérés, conformément au sweetspot, se situe généralement autour de 10 documents - car plus de documents n'améliorent pas nécessairement les résultats, mais intensifient les coûts.
Cette approche est optimale pour :
- Les explications techniques détaillées
- Les réponses basées sur des faits
- Les situations nécessitant des informations hautement spécifiques
- Les cas où différentes parties de la réponse nécessitent des sources différentes
L'implémentation technique : Le pipeline RAG
L'implémentation pratique d'un système RAG se déroule en trois phases principales : Ingestion, Retrieval et Generation. Chacune de ces phases joue un rôle décisif dans la qualité des résultats finaux.
1. La phase d'Ingestion
Dans cette première phase, les documents sont introduits dans le système et préparés pour une utilisation ultérieure. L'implémentation RAG originale utilisait par exemple un dump Wikipedia contenant 21 millions de documents, chacun divisé en chunks de 100 mots. Le processus se déroule comme suit :
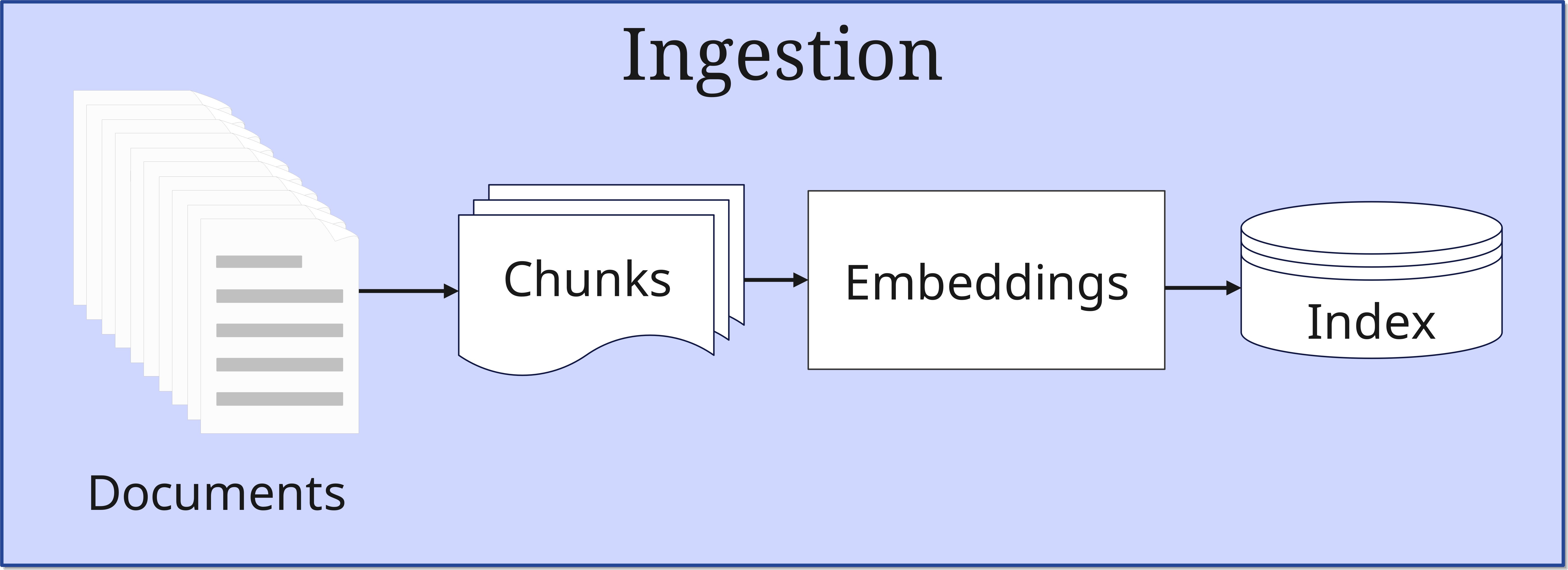
- Préparation des documents :
- Les documents (Documents) sont divisés en morceaux plus petits et gérables (Chunks)
- La taille des chunks est optimisée en fonction du cas d'utilisation
- Génération d'Embedding :
- Chaque chunk est converti en un vecteur mathématique multidimensionnel (généralement jusqu'à 1024 dimensions) par un Document Encoder basé sur BERT
- Ces vecteurs capturent la sémantique du texte, donc pas la formulation mais la signification (nous en apprendrons davantage sur les vecteurs dans un futur article sur les bases de données vectorielles)
- Indexation :
- Les embeddings sont stockés dans une base de données vectorielle
- Un index MIPS (Maximum Inner Product Search) est créé pour une recherche efficace
- Des technologies comme FAISS permettent une recherche approximative rapide en temps sublinéaire
Ce processus est crucial pour l'efficacité ultérieure du système. L'art consiste à découper les documents de manière à ne pas séparer les informations connexes tout en maintenant les chunks suffisamment petits pour fournir des résultats précis.
2. La phase de Retrieval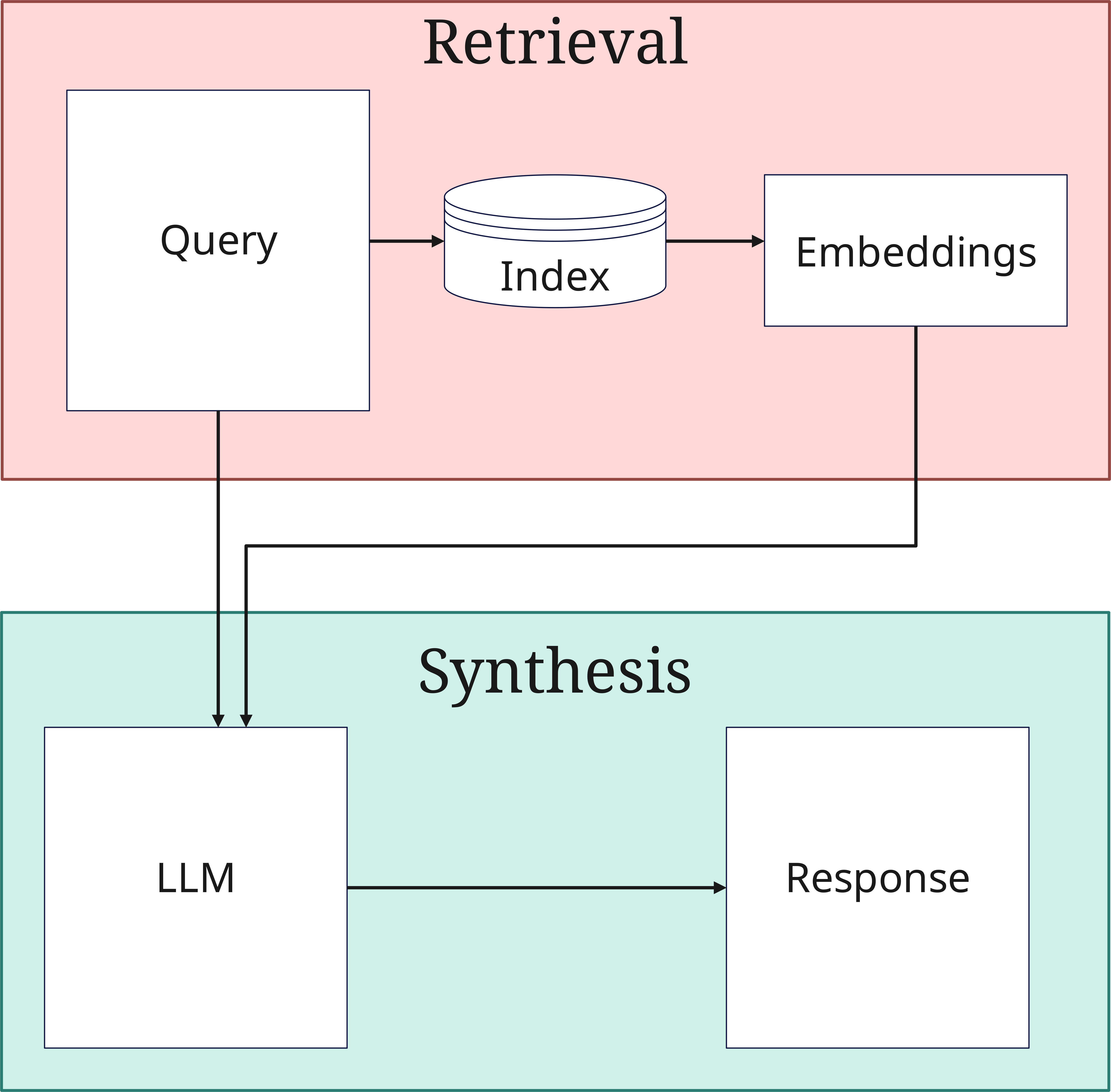
Lorsqu'une requête arrive, la phase de Retrieval commence :
- Traitement de la requête : La requête est également convertie en vecteur. Cette requête est à la fois stockée par le Retriever dans la base de données vectorielle et envoyée directement dans sa forme originale à la synthèse de la réponse dans le Generator
- Recherche de similarité : Le système recherche dans la base de données vectorielle (Index) les documents similaires à ceux transmis à la base de données. Ici, les vecteurs de la requête sont comparés à ceux des documents indexés
- Sélection Top-K : Les documents les plus pertinents sont sélectionnés
Le nombre de documents sélectionnés (Top-K) est un paramètre important qui influence l'équilibre entre l'exhaustivité et l'efficacité du traitement.
3. La phase de Génération (Synthesis)
Dans la phase finale, les informations trouvées sont traitées pour former une réponse :
- Intégration du contexte : Les documents Top-K sélectionnés sont combinés avec la requête originale
- Génération de la réponse : Le LLM crée une réponse cohérente
- Assurance qualité : La réponse est vérifiée pour sa cohérence et sa pertinence, puis émise
Un exemple compréhensible
Étape 1 : Création d'un prompt (Query)
Imaginez un collaborateur qui s'approche de votre bureau et vous pose une question :
"Nous avions une idée de projet. Nous voulons faire xyz. Quelles sont les directives légales à ce sujet ?"
Cette demande est un prompt.
Mettez-vous maintenant dans la situation de l'intelligence artificielle. La question est claire et directe. Mais pour pouvoir y répondre, vous avez besoin de plus de contexte. Vous explorez donc tous vos souvenirs des conversations précédentes avec ce collaborateur et établissez ainsi une meilleure relation avec le sujet, ce qui conduira à une meilleure compréhension globale de la question.
Toutes les informations trouvées constituent le contexte. Le prompt est maintenant enrichi du contexte - les informations historiques sont pour ainsi dire attachées à la question initiale du collaborateur. Le prompt devient alors ce qu'on appelle un Enhanced Prompt.
De plus, en tant que supérieur, vous vous demandez également comment exactement l'idée du projet profite à votre entreprise. Vous y réfléchissez donc vous-même, posez peut-être une question supplémentaire, et complétez encore davantage l'Enhanced Prompt avec les connaissances acquises. Progressivement, la Query est ainsi complétée.
Étape 2 : Embedding
À l'étape suivante, vous alimentez votre Query dans un Embedding Model, qui la convertit en un vecteur à 1024 dimensions. Donc pas seulement tridimensionnel, mais une valeur vraiment inimaginable pour les humains ordinaires. Ces 1024 dimensions permettent alors de saisir la signification de la Query avec une certaine précision. Donc pas les mots individuels, mais le sens. L'Embedding Model stocke maintenant ce vecteur dans la base de données vectorielle.
La base de données vectorielle effectue maintenant une recherche de similarité par rapport au vecteur de la Query. La similarité trouvée d'un document signifie qu'il est présélectionné. À la fin de la recherche, les meilleurs résultats sont sélectionnés et les documents, entrées de base de données, etc. correspondants sont référencés.
Ces documents et autres informations trouvés sont maintenant attachés à la Query. Imaginez-le comme si vous joigniez des documents à un e-mail déjà formulé. L'Enhanced Prompt devient ainsi un Augmented Prompt.
Étape 3 : Génération d'une réponse
Cet Augmented Prompt va maintenant au Generator, plus précisément au LLM impliqué, avec la Query originale. Le LLM synthétise maintenant une réponse à partir de la requête originale et de toutes les informations supplémentaires trouvées. Cette Response est ensuite renvoyée au collaborateur qui, espérons-le, est satisfait du contenu.
La RAG Triad : Évaluation de la qualité
Même si un LLM a accès aux informations les plus récentes dans le pool d'informations grâce au RAG et peut donner des réponses très précises, cela n'élimine pas le risque d'hallucinations. Il y a plusieurs raisons à cela :
- Le Retriever ne collecte tout simplement pas assez de contexte (quantitativement), ou il collecte de mauvaises informations (qualitativement).
- Peut-être que la réponse n'est pas entièrement soutenue par le contexte collecté, mais a été trop influencée par le LLM et les données d'entraînement.
- Un RAG collecte peut-être les informations pertinentes et construit une réponse fondamentalement correcte à partir de celles-ci, mais la réponse ne correspond peut-être pas à la question initiale.
Pour éviter cela, la RAG Triad a été développée.
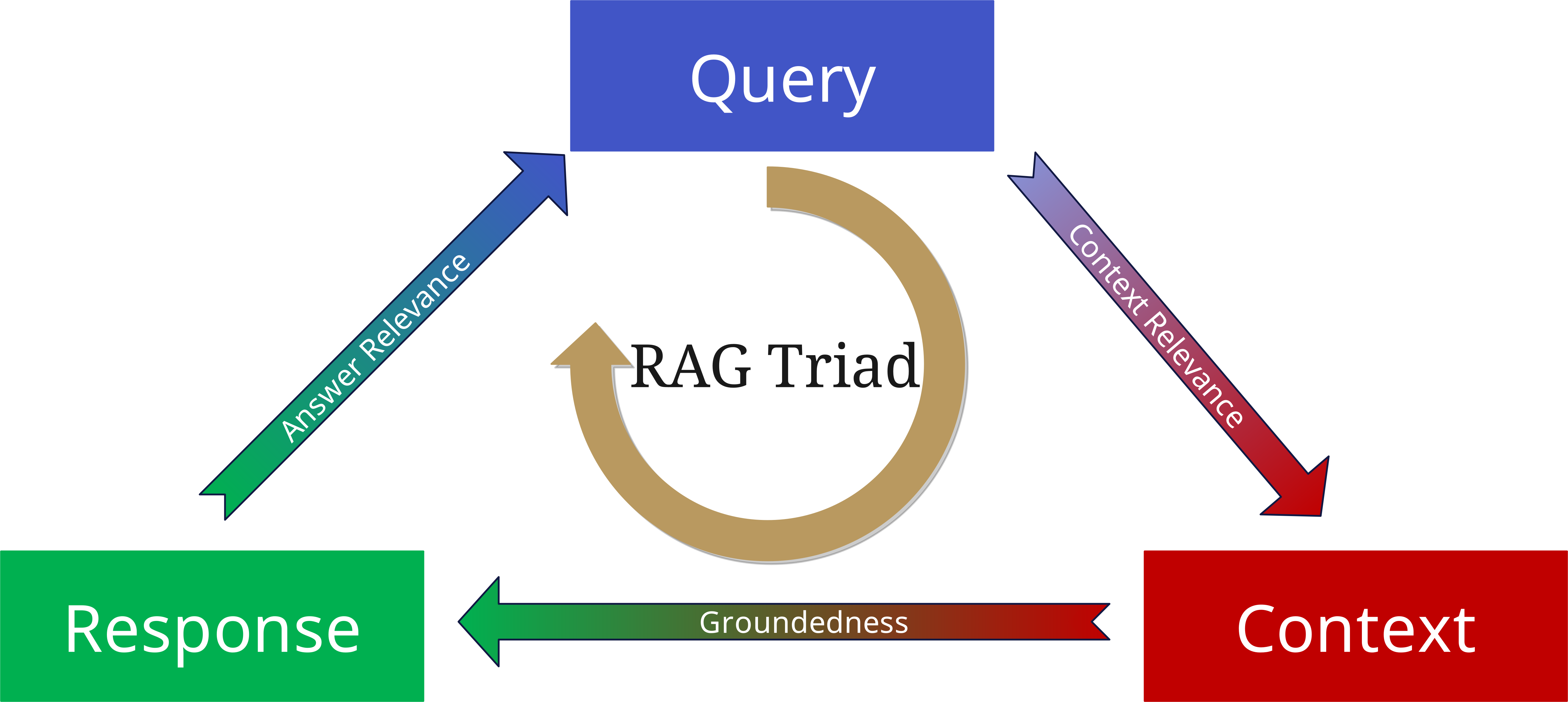
Pour évaluer la qualité d'un système RAG, nous considérons trois aspects centraux :
1. Context Relevance (Pertinence du contexte)
- Dans quelle mesure les documents récupérés correspondent-ils à la requête ?
- Le bon contexte a-t-il été trouvé ?
- Les informations sont-elles actuelles et appropriées ?
2. Groundedness (Fondement)
- La réponse est-elle réellement basée sur les documents récupérés ?
- Les affirmations sont-elles étayées par les sources ?
- Y a-t-il des hallucinations ou des conclusions non fondées ?
3. Answer Relevance (Pertinence de la réponse)
- La réponse générée répond-elle à la question initiale ?
- La réponse est-elle complète et précise ?
- La profondeur des informations est-elle appropriée ?
En appliquant à nouveau ces trois aspects comme paramètres à la Query, au contexte et à la réponse générée, on peut minimiser les hallucinations et construire des applications basées sur RAG plus fiables et plus robustes.
LLMs avec et sans RAG : Une comparaison
Les LLMs traditionnels et les systèmes enrichis par RAG diffèrent fondamentalement dans leur mode de fonctionnement :
LLMs traditionnels
- Basés exclusivement sur des connaissances préentraînées
- Ne peuvent pas accéder à de nouvelles informations spécifiques
- Sont plus susceptibles aux hallucinations
- Ont un état de connaissance "figé"
Systèmes enrichis par RAG
- Combinent les connaissances préentraînées avec des sources externes
- Peuvent accéder à des informations actuelles et spécifiques
- Fournissent des réponses traçables basées sur des sources
- Sont extensibles de manière flexible
Ces différences font du RAG une solution idéale pour les applications d'entreprise, où la précision, l'actualité et la traçabilité sont cruciales.
Aperçu de la partie 3 : Le rôle des bases de données vectorielles
Un composant central qui rend le RAG possible est la base de données vectorielle. Ces bases de données spécialisées sont optimisées pour le stockage et l'interrogation de vecteurs - les représentations mathématiques du texte qui constituent le fondement du RAG.
Dans la partie 3 de notre série, nous nous concentrerons sur les bases de données vectorielles :
- Comment fonctionnent-elles en détail ?
- Quels types de bases de données vectorielles existe-t-il ?
- Comment choisir la bonne base de données vectorielle pour son projet ?
- Quelles sont les meilleures pratiques pour l'implémentation ?
La base de données vectorielle est le cœur d'un système RAG et mérite donc une attention particulière. Elle est la clé d'une recherche et d'un traitement efficaces de l'information et donc cruciale pour la performance du système dans son ensemble.
