











在本系列的第一部分中,我们了解了Retrieval-Augmented Generation (RAG)的基本概念,并了解了这个框架如何像数字图书馆一样运作。我们详细研究了三个主要组件 - Retriever、Ranker和Generator,并理解它们如何协同工作以生成准确和与上下文相关的回答。
在第二部分中,我们将深入探讨RAG的技术层面。我们将研究RAG在实践中如何实施,有哪些不同的模型类型,以及RAG增强系统与传统Large Language Models (LLMs)有何不同。
两种RAG模型类型:Sequence和Token
在实施RAG时,有两种基本方法:RAG-Sequence和RAG-Token。每种方法都有其特定的优势,适用于不同的应用场景。
RAG-Sequence:整体方法
RAG-Sequence的工作方式类似于一位细心的作者,首先研究所有相关资料,然后撰写连贯的文本。这种方法的数学优雅性体现在其整体观察方式上:
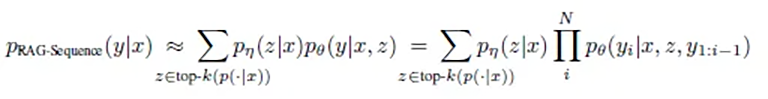
或简化表述:p(答案 | 问题) = 所有文档的总和( p(文档 | 问题) × p(答案 | 问题, 文档) )
用简单的话来说,这意味着:
- 系统为每个潜在相关文档计算两个值:
- 该文档与问题相关的可能性有多大?
- 该文档能引导出正确答案的可能性有多大?
- 这些概率相乘并对所有文档求和,以找出最佳答案。
技术流程如下:
- 系统从数百万文档的索引中选择与查询最相关的前K个文档
- Generator为每个文档创建一个完整的潜在答案
- 这些答案根据其计算出的概率进行合并
研究表明,这种方法在创建连贯、结构良好的答案方面特别有效。研究中的一个有趣细节是:随着相关文档数量的增加,答案质量会持续提高。
研究结果表明,RAG-Sequence在需要一致性和连贯性输出的任务中表现特别出色。与其他方法相比,答案通常更加多样化且细致入微。
这种方法特别适用于:
- 长文本摘要
- 报告生成
- 需要全面理解的复杂问题答复
- 需要整体主题一致性的任务
RAG-Token:精细方法
RAG-Token的工作方式类似于一位认真的记者,为每个句子和每个词都寻找最佳的信息来源。这种方法的数学表达反映了这种严谨性:
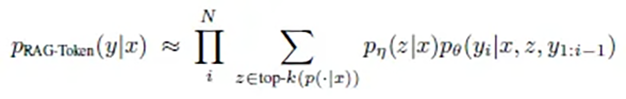
p(答案 | 问题) = 每个词的乘积( 所有文档的总和( p(文档 | 问题) × p(词 | 问题, 文档, 前面的词) ) )
在实践中,这意味着:
- 对于答案中的每个词:
- 重新评估最相关的文档
- 计算每个可能的下一个词的概率
- 基于所有可用信息选择最可能的词
- 这个过程逐词重复,每个新词受以下因素影响:
- 已写出的词
- 原始问题
- 当前最相关的文档
研究表明,这种方法在涉及事实准确性时能产生特别精确的结果。有趣的是,考虑文档数量有一个最佳"甜点":每个Token约10个文档能产生最佳结果。更多文档不一定能带来更好的答案,但会显著增加处理时间。
研究表明,RAG-Token在需要详细、基于事实的答案的任务中特别有效。根据最佳点,检索文档的最佳数量通常在约10个文档左右 - 因为更多文档不一定能改善结果,但会增加成本。
这种方法最适合:
- 详细的技术解释
- 基于事实的回答
- 需要高度具体信息的情况
- 答案不同部分需要不同来源的情况
技术实现:RAG管道
RAG系统的实际实现分为三个主要阶段:摄入、检索和生成。每个阶段对最终结果的质量都起着决定性作用。
1. 摄入阶段
在这第一阶段,文档被输入系统并为后续使用做准备。最初的RAG实现使用了包含2100万文档的Wikipedia数据,每个文档被分割成100个词的块。过程如下:
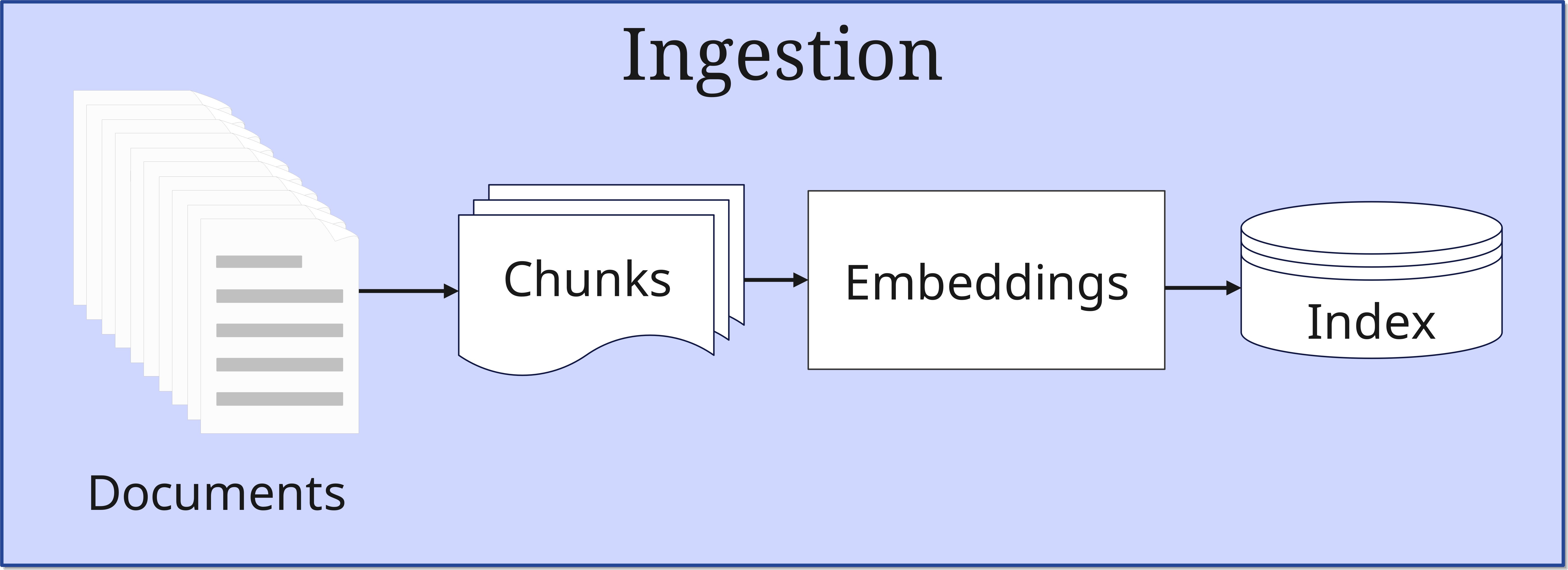
- 文档准备:
- 文档被分割成较小的、可管理的块
- 块大小根据应用场景进行优化
- Embedding生成:
- 每个块通过基于BERT的文档编码器转换为数学多维向量(通常最多1024维)
- 这些向量捕获文本的语义,即不是字面意思,而是含义(关于向量的更多内容将在未来关于向量数据库的文章中讨论)
- 索引:
- Embeddings存储在向量数据库中
- 为高效搜索创建MIPS索引(Maximum Inner Product Search)
- 像FAISS这样的技术能够在亚线性时间内进行快速、近似搜索
这个过程对系统后续的效率至关重要。技巧在于如何分割文档,既不破坏相关信息的连贯性,又保持块的大小足够小以提供精确结果。
2. 检索阶段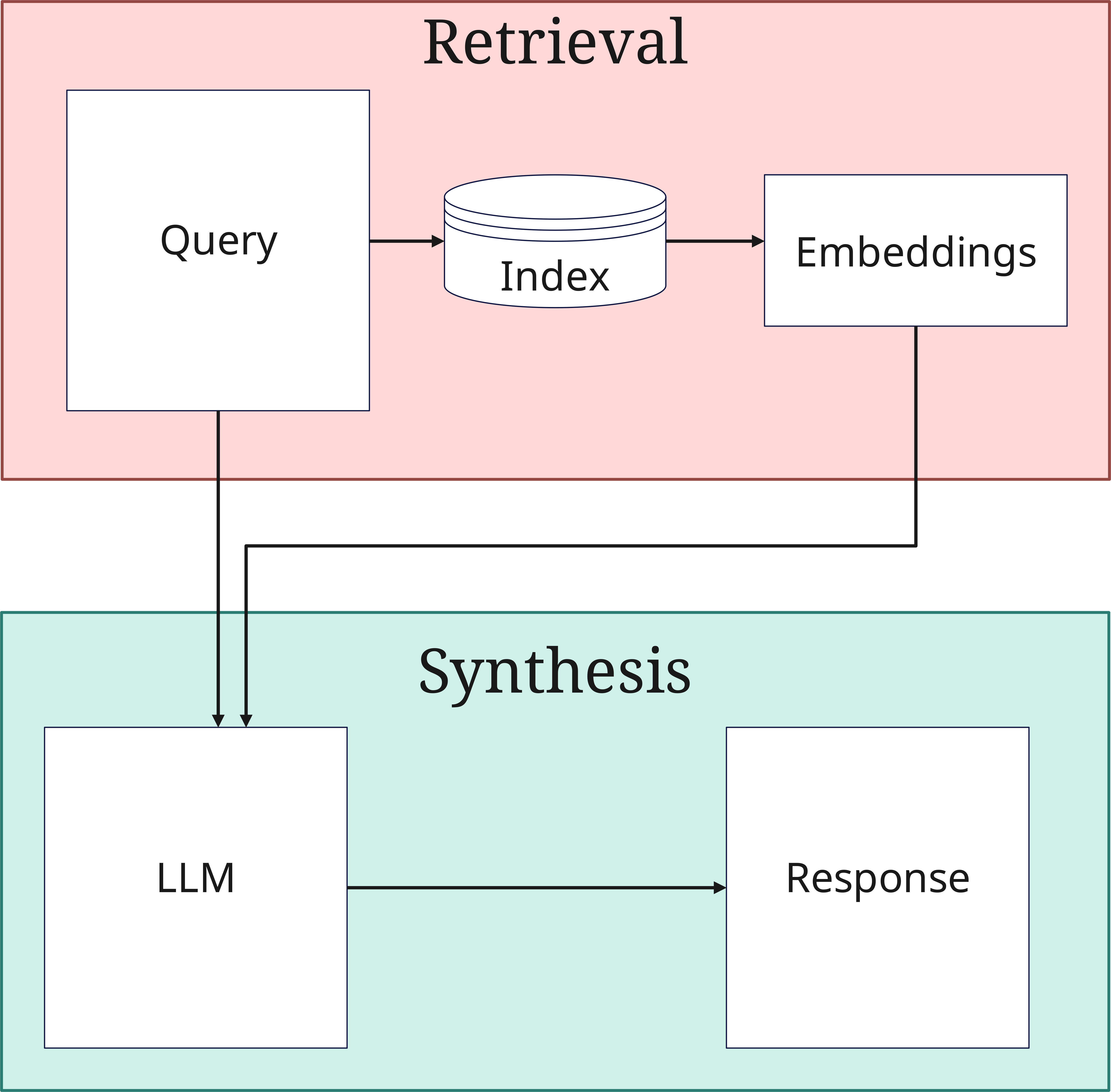
当收到查询时,检索阶段开始:
- 查询处理:查询也被转换为向量。这个查询被Retriever既存储在向量数据库中,又直接发送到Generator进行答案合成
- 相似度搜索:系统在向量数据库(索引)中搜索与发送到数据库的向量相似的文档。这里比较查询向量与索引文档的向量
- Top-K选择:选择最相关的文档
选择的文档数量(Top-K)是一个重要参数,它影响完整性和处理效率之间的平衡。
3. 生成阶段 (Synthesis)
在最后阶段,找到的信息被处理成答案:
- 上下文整合:选定的Top-K文档与原始查询结合
- 答案生成:LLM创建一个连贯的答案
- 质量保证:答案经过一致性和相关性检查后输出
一个易懂的例子
步骤1:创建提示(Query)
想象一个员工走到你的办公桌前向你提问:
"我们有一个项目想法。我们想做xyz。这方面的法律规定是什么?"
这个查询就是一个Prompt。
现在设身处地为人工智能着想。问题清晰直接。但要回答它,你还需要更多上下文。所以你搜索所有与这位员工之前的对话记忆,从而建立更好的主题联系,这将导致对问题更好和更全面的理解。
所有找到的信息就是上下文。Prompt现在通过上下文得到扩展 - 历史信息被附加到员工的实际问题上。Prompt现在变成了所谓的Enhanced Prompt。
此外,作为主管,你还会思考项目想法究竟如何帮助你的公司。你自己还会思考一下,可能会再次询问,并用发现的见解进一步补充Enhanced Prompt。这样,Query逐渐完善。
步骤2:Embedding
下一步,你将Query输入Embedding Model,它将其转换为1024维向量。这不仅仅是三维,而是对普通人来说难以想象的维度。通过这1024个维度,就可以相当准确地捕捉Query的含义。不是单个词,而是意义。Embedding Model现在将这个向量存储在向量数据库中。
现在,向量数据库对Query的向量进行相似度搜索。找到文档的相似性意味着该文档被标记。在搜索结束时,选择最佳结果并引用相应的文档、数据库条目等。
这些找到的文档和其他信息现在被附加到Query上。想象一下,就像你在一封写好的电子邮件上附加文档。这样,Enhanced Prompt变成了Augmented Prompt。
步骤3:生成答案
这个Augmented Prompt现在与原始Query一起发送给Generator,更具体地说是发送给涉及的LLM。LLM现在从原始查询和所有找到的附加信息中合成答案。这个Response然后返回给员工,希望他对内容满意。
RAG Triad:质量评估
即使LLM通过RAG能够访问信息池中最新的信息并能给出非常准确的答案,这也不能消除幻觉的风险。这有几个原因:
- Retriever简单地没有收集到足够的上下文(数量上),或者收集了错误的信息(质量上)。
- 可能答案并不完全由收集的上下文支持,而是受到了LLM和训练数据的过度影响。
- RAG可能收集了相关信息并建立了基本正确的答案,但答案可能与实际问题不符。
为了避免这种情况,开发了RAG Triad。
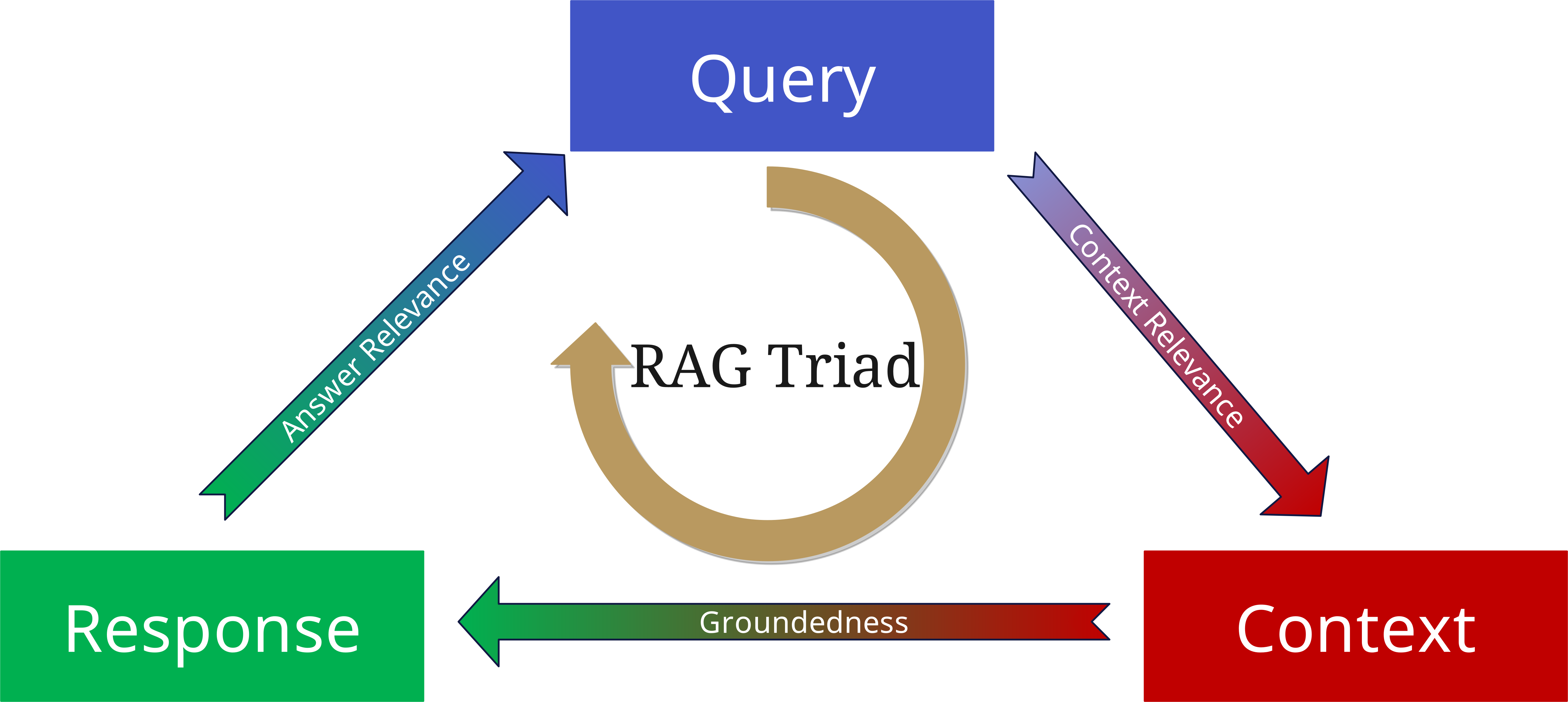
为了评估RAG系统的质量,我们考虑三个核心方面:
1. Context Relevance(上下文相关性)
- 检索到的文档与查询的匹配程度如何?
- 是否找到了正确的上下文?
- 信息是否最新和适当?
2. Groundedness(基础性)
- 答案是否真正基于检索到的文档?
- 陈述是否有源文件支持?
- 是否存在幻觉或未经证实的结论?
3. Answer Relevance(答案相关性)
- 生成的答案是否回答了原始问题?
- 答案是否完整和准确?
- 信息深度是否适当?
当将这三个方面作为参数应用于查询、上下文和生成的答案时,可以最小化幻觉并构建更可靠和更稳健的基于RAG的应用。
有无RAG的LLMs:比较
传统LLMs和RAG增强系统在工作方式上有根本区别:
传统LLMs
- 仅基于预训练知识
- 无法访问新的或特定信息
- 更容易产生幻觉
- 具有"冻结"的知识状态
RAG增强系统
- 将预训练知识与外部源结合
- 可以访问当前和特定信息
- 提供可追溯的、基于源的答案
- 可灵活扩展
这些差异使RAG成为企业应用的理想解决方案,在这些应用中,精确性、时效性和可追溯性至关重要。
第3部分展望:向量数据库的作用
使RAG成为可能的核心组件是向量数据库。这些专门的数据库针对向量的存储和查询进行了优化 - 这些向量是文本的数学表示,构成了RAG的基础。
在系列的第3部分中,我们将深入研究向量数据库:
- 它们的详细工作原理是什么?
- 有哪些类型的向量数据库?
- 如何为项目选择正确的向量数据库?
- 实施有哪些最佳实践?
向量数据库是RAG系统的核心,因此值得特别关注。它是高效信息搜索和处理的关键,因此对整个系统的性能至关重要。
