









It is 2:30 p.m. on a regular Tuesday afternoon. The DevOps team of a Swiss financial services provider routinely launches its Terraform pipeline for the monthly disaster recovery testing. 300 virtual machines, 150 load balancer backends, 500 DNS entries, and countless network rules are to be provisioned in the backup region.
After 5 minutes, the pipeline fails. HTTP 429: Too Many Requests.
The next 3 hours are spent by the team manually cleaning up half-provisioned resources, while management nervously watches the clock.
The DR test has failed before it even began.
Read more: Terraform @ Scale - Part 5a: Understanding API Limits

TLS Certificate Lifespans Are Being Drastically Shortened: IT Decision-Makers Must Take Action NOW!
Starting in March 2026, the maximum validity of server certificates will first be halved to 200 days, then gradually reduced to 100 and ultimately to 47 days.
Companies without an enterprise PKI strategy risk operational bottlenecks and visible compliance issues for their customers.
The Facts - Resolution of the CA/Browser Forum
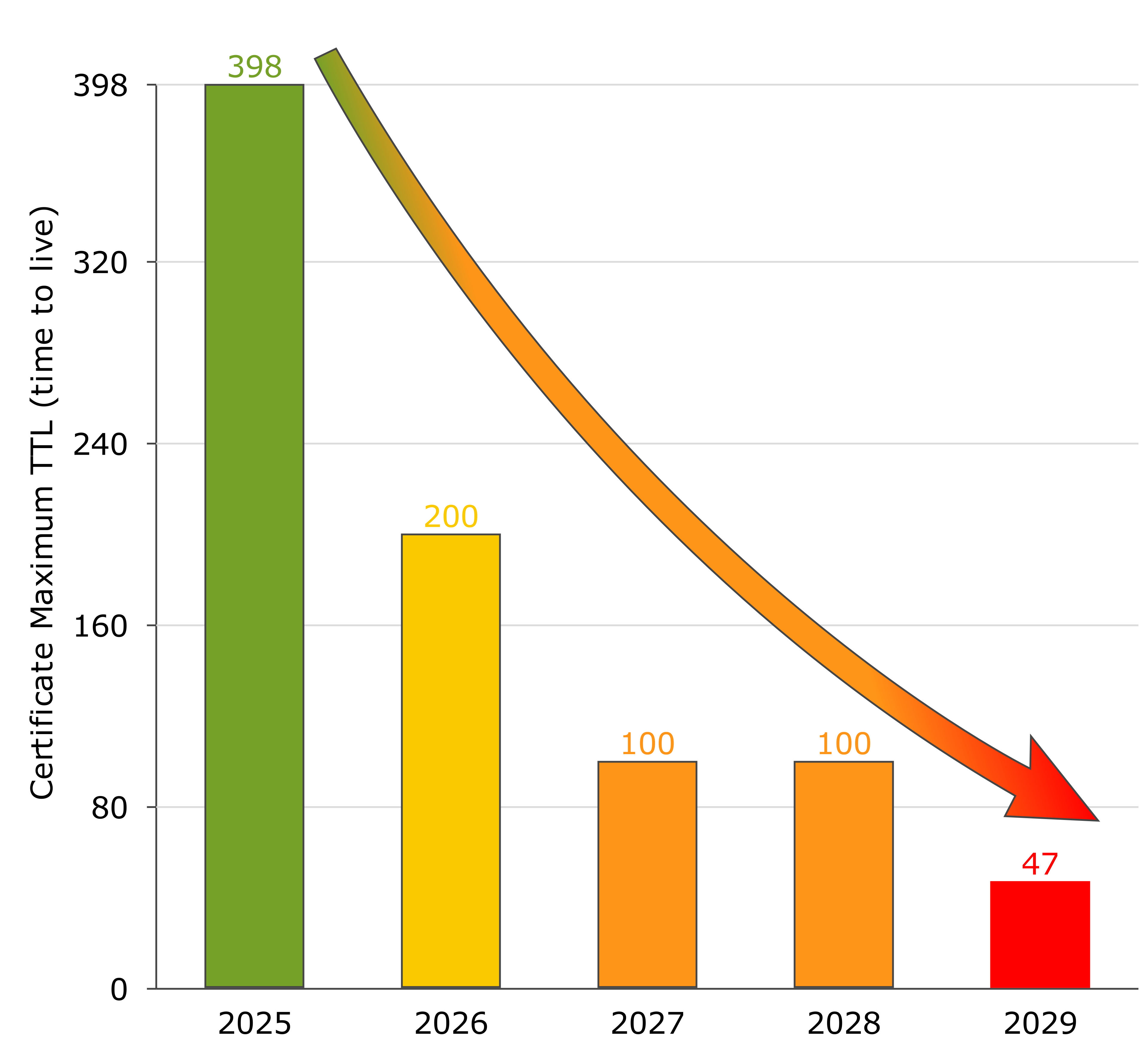 On April 11, 2025, the CA/Browser Forum adopted a binding roadmap for shortening certificate lifespans with Ballot SC‑081 v3:
On April 11, 2025, the CA/Browser Forum adopted a binding roadmap for shortening certificate lifespans with Ballot SC‑081 v3:
| Effective Date | Maximum Validity | Renewal Frequency |
|---|---|---|
| March 15, 2026 | 200 days | ~2× per year |
| March 15, 2027 | 100 days | ~4× per year |
| March 15, 2029 | 47 days | ~8× per year |
All major browser vendors have announced they will block longer certificates as invalid starting on these dates. (CA/Browser Forum, Business Wire)
This decision is final - there will be no grace period.
Business Impact - What This Means for Your Company
Operational Load Will Rise Almost Exponentially
The shorter intervals multiply the workload for your teams:
- Today: 1 renewal/year
- 2026: 2 renewals/year
- 2027: 4 renewals/year
- 2029: 8 renewals/year
Now imagine you are using 100 TLS certificates to secure your public web servers, internal services and internal communication. For mid-sized and larger organizations, this quickly turns into several thousand individual certificates.
The days of ordering and installing new certificates manually are over.
Without automation, your engineers would spend a large portion of their time acquiring, distributing and managing certificates.
Downtime Risk Due to Human Error
According to a Ponemon study, 73 % of unplanned outages are already caused by expired or mismanaged certificates. (mcpmag.com)
Multiplying the number of renewals by a factor of eight inevitably increases the risk that a certificate is overlooked in production.
Compliance and Audit Complexity
Each shortening of certificate lifespan forces additional documentation - especially in regulated industries. Manual tracking with spreadsheets or individual scripts will not scale here.
Why Standard Approaches Are Not Enough
| Approach | Strengths | Limiting Factors |
|---|---|---|
| Let’s Encrypt | Free of charge, ACME automation | No central policy or role model, no audit logs, no private CAs |
| Cloud PKI Services | Quick to deploy | Vendor lock-in, multi-cloud obstacles, limited governance |
| Traditional CAs | Established trust anchors | Manual ordering processes, no API integration, scaling issues |
Our Offering - The Enterprise Response to Shortened Certificate Lifespans
 We implement PKI and certificate management based on HashiCorp Vault (from Q4/2025 also known as IBM Vault). Whether you choose the free version (Open Source) or the Enterprise edition is entirely up to you, based on your specific use case.
We implement PKI and certificate management based on HashiCorp Vault (from Q4/2025 also known as IBM Vault). Whether you choose the free version (Open Source) or the Enterprise edition is entirely up to you, based on your specific use case.
Centralized PKI Governance
Vault acts as an internal certificate authority and enforces consistent policies across all environments - on-premise, AWS, OCI or multi-cloud.
Automation Without Vendor Lock-In
The API-first approach enables full CI/CD integration and eliminates human touchpoints for issuing, renewing or revoking certificates.
Compliance-Ready Audit Trails
Every step - from key generation to revocation - is immutably logged. Audit readiness is built in by design.
Measurable ROI
HashiCorp customer reports show a reduction of over 60 % in operational workload in comparable environments. The shorter the lifespans, the greater the effect.
Strategic Options for Action
| Option | Risk | Suitable For |
|---|---|---|
| Maintain Status Quo | Highest risk - staffing overload, outages, audit findings | Small environments with few external certificates |
| Cloud PKI Service | Medium - lock-in, limited multi-cloud strategy | Mono-cloud workloads without strict regulatory requirements |
| Enterprise PKI with HashiCorp Vault | Low - full control, scalable, auditable | Organizations with critical applications and a multi-cloud roadmap |
Timing and Budget Considerations
- Secure budget before the end of 2025 - the first reduction takes effect mid FY 2026.
- Plan for 6–9 months lead time for introducing processes and tools.
- Pilot phase: Start with less critical services, collect KPIs, then scale up.
Why ICT.technology Is Your Trusted Advisor

- HashiCorp Partner with certified Vault consultants
- Legal & Regulatory Expertise: Deep experience in FinTech, healthcare and industrial sectors
- End-to-End Methodology: From strategic consulting to IaC implementation (Terraform stacks, Ansible, OCI, AWS) through to managed PKI operations
- Proven success patterns from numerous projects
Next Steps
Ready for PKI transformation?
Book an appointment for a non-binding assessment and a customized Vault strategy.
After that, I recommend the following approach:
- PKI Assessment: Determine current inventory and maturity level
- Define target architecture: On-premise, cloud or hybrid
- Design PKI strategy: Tailored to your specific needs
- Pilot / Proof of Concept with Vault: Low-risk, measurable, scalable
- Roll-out: Step-by-step migration of business-critical systems
Sources
- CA/Browser Forum, Ballot SC‑081v3, April 11, 2025 (CA/Browser Forum)
- BusinessWire: “CA/Browser Forum Passes Ballot to Reduce SSL/TLS Certificates to 47 Day Maximum Term”, April 14, 2025 (Business Wire)
- Ponemon Institute: “Key and Certificate Errors Survey”, 2020 (73 % outages) (mcpmag.com)
- HashiCorp Case Study “Running HashiCorp with HashiCorp”, 2021 - 60 %+ cost reduction (HashiCorp - PDF download)

In the last part of this series, we showed how seemingly harmless data sources in Terraform modules can become a serious performance issue. Multi-minute terraform plan runtimes, unstable pipelines and uncontrollable API throttling effects were the result.
But how can you avoid this scalability trap in an elegant and sustainable way?
In this part, we present proven architectural patterns that allow you to centralize data sources, inject them efficiently and thereby achieve fast, stable and predictable Terraform executions even with hundreds of module instances.
Included: three scalable solution strategies, a practical step-by-step guide and a best practices checklist for production-ready infrastructure modules.
Read more: Terraform @ Scale - Part 4b: Best Practices for Scaling Data Sources

Terraform's Data Sources are a popular way to dynamically populate variables with real-world values from the respective cloud environment. However, using them in dynamic infrastructures requires some foresight. A harmless data.oci_identity_availability_domains in a module, for example, is enough - and suddenly every terraform plan takes minutes instead of seconds. Because 100 module instances mean 100 API calls, and your cloud provider starts throttling. Welcome to the world of unintended API amplification through Data Sources.
In this article, I will show you why Data Sources in Terraform modules can pose a scaling problem.
Read more: Terraform @ Scale - Part 4a: Data Sources are Dangerous!

Even the most sophisticated infrastructure architecture cannot prevent every error. That is why it is essential to monitor Terraform operations proactively - especially those with potentially destructive impact. The goal is to detect critical changes early and trigger automated alerts before an uncontrolled blast radius occurs.
Sure - your system engineer will undoubtedly point out that Terraform displays the full plan before executing an apply, and that execution must be confirmed by entering "yes".
What your engineer does not mention: they do not actually read the plan before allowing it to proceed.
“It'll be fine.”
Read more: Terraform @ Scale - Part 3c: Monitoring and Alerting for Blast Radius Events