
🔥 A single terraform destroy - and suddenly, 15 customer systems go offline 🔥
The "Friday afternoon destroyer" has struck again.
In this two-part article, we examine one of the most significant structural infrastructure problems, as well as one of the most underestimated risks of Infrastructure-as-Code, from a management perspective. We help companies systematically minimize blast radius risks.
Because the best explosion is the one that never happens.
The Anatomy of a Terraform Catastrophe
Scenario: The Friday Afternoon Destroyer
It’s 4:30 PM on a Friday. A developer wants to quickly clean up a test environment and runs terraform destroy. What he doesn’t realize: the VPC he is trying to delete is referenced via remote state by three other states that manage production workloads for different customers.
⚠️ The result:
- 15 customer systems go down simultaneously
- Database connections break
- Load balancers lose their targets
- Monitoring systems report total outages
- The weekend is ruined
This scenario is not hypothetical – it happens in real life more often than you might think. The cause usually lies in a combination of:
- Monolithic states: Too many resources in a single state result in unmanageable dependencies
- Unclear ownership: No one knows exactly who is responsible for which resources
- Missing guardrails: No technical safeguards against accidental deletions
Infrastructure-as-Code promises control, reproducibility, and efficiency. But when Terraform states are poorly structured, a seemingly harmless terraform destroy or terraform apply can turn into a disaster. The so-called blast radius – the range of unintended consequences – quickly becomes larger than expected.
Following our previous article on the Goldilocks principle for optimal state sizes, we now turn to one of the most critical aspects of scaling Terraform: managing the blast radius. Because the question is not whether something will go wrong, but how much will be affected when it does.
What is the Blast Radius in Terraform?
The term blast radius originates from explosives engineering and describes the area in which an explosion causes damage. In the Terraform world, it refers to the part of the infrastructure that can be affected by changes, errors, or outages.
The connection between individual resources is defined by their interdependencies. Terraform internally generates a dependency graph dynamically, which is not always fully and intuitively visible to the engineer.
Some dependencies are obvious. For example, a virtual server needs a network in which it is placed. This network is usually wired into the compute resource associated with the server by the engineer, so the dependency is not only logical, but also documented in the Terraform module code.
But what about indirect and dynamically generated dependencies that only arise through Terraform’s internal calculations? For instance, the IP address of a web service is not assigned directly to the virtual server but to an IP address resource, which is then wired into a VNIC resource, which may - or may not - be assigned to one or more virtual servers, or a load balancer, or possibly a firewall. At that point, it becomes difficult to spontaneously determine how a change in the subnet’s netmask will affect the assigned IP address that originates from that subnet’s IP address pool.
IT infrastructures, especially with a generous helping of historical growth and change, quickly become more complex than initially anticipated during the design phase. You then end up relying on every engineer and the automation in the pipeline to not only read the execution plan created by terraform plan as it scrolls past in the shell window, but also to fully understand and verify it for correctness - something that hardly any human operator does due to lack of global perspective, time, and motivation, and which the average CI/CD pipeline is certainly not capable of.
Blast Radius Visualization:
- Small states = few direct and indirect dependencies = small blast radius: An error affects only a few resources
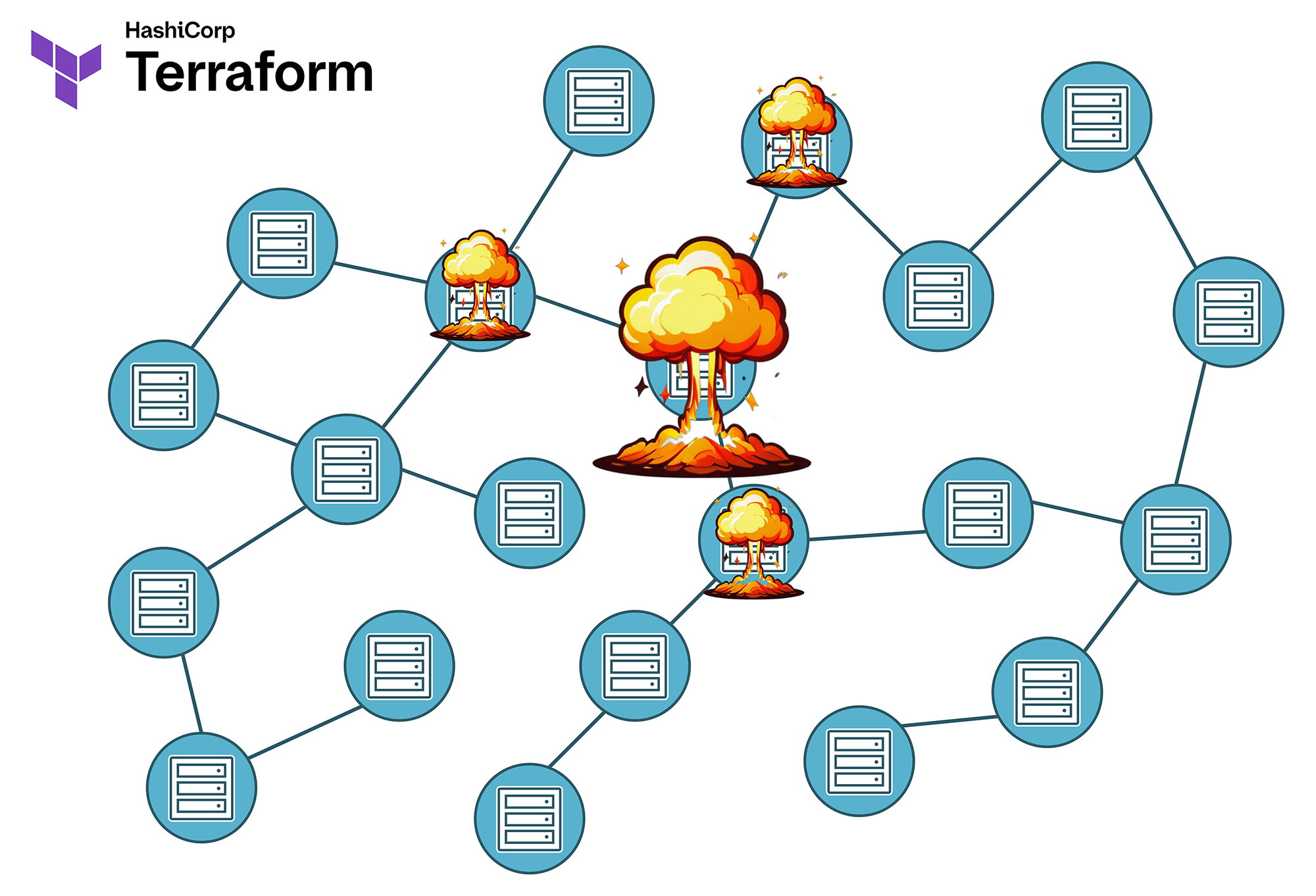
- Large states = more direct and indirect dependencies = large blast radius: An error can have extensive, unpredictable effects.
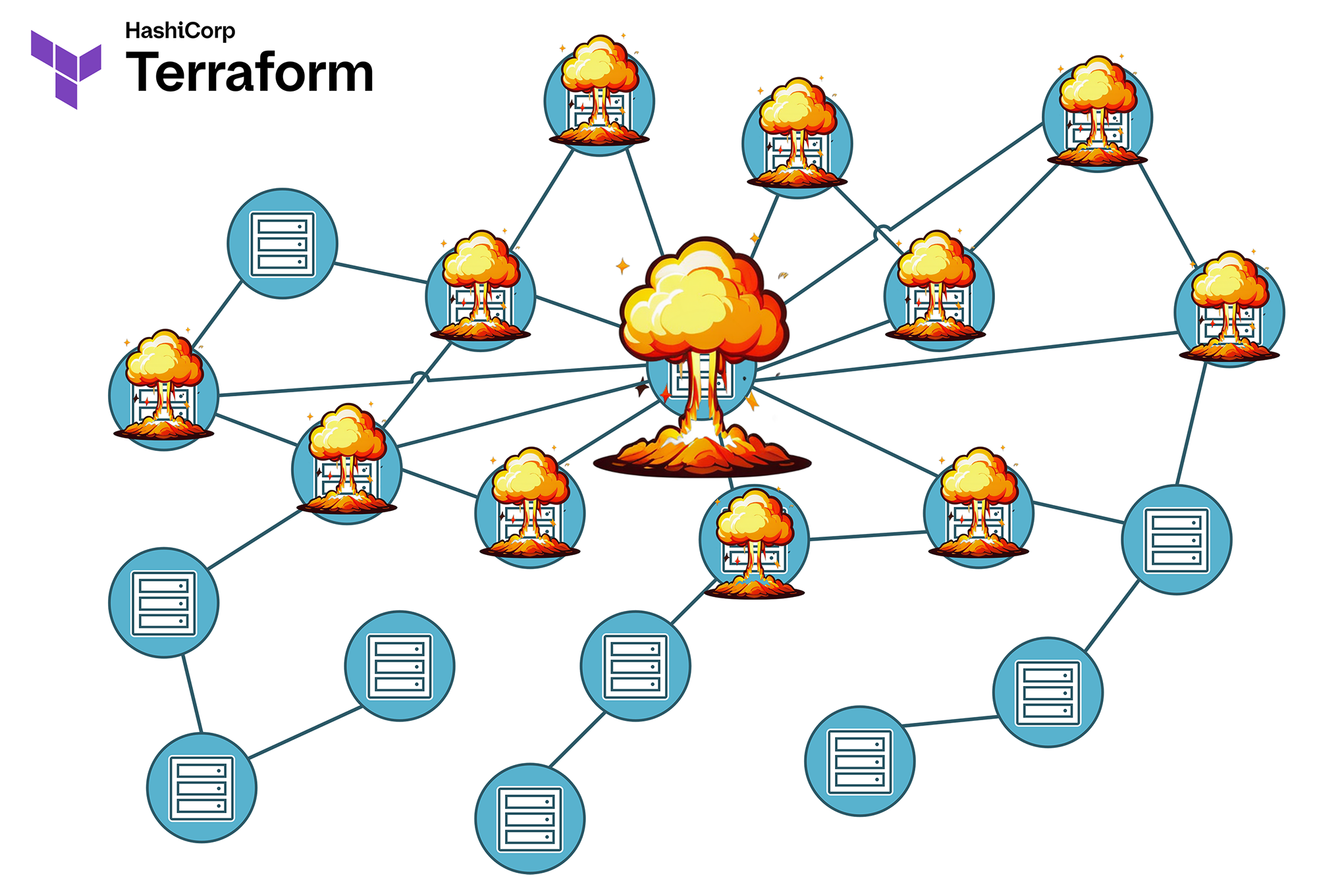
In practice, an uncontrolled blast radius manifests in various ways:
- Unintended deletions: A terraform destroy not only removes the intended resources, but also dependent components in other systems. This means you're tweaking one corner of the infrastructure landscape, and then something explodes in a completely different, unexpected area. This mostly happens in large, monolithic states.
- Cascading failures: A change to a central resource causes outages in seemingly independent services or resources. This can happen not only due to dependencies, but also due to organizing resources in the wrong data types, i.e., coding errors. I once had a customer, for instance, where several hundred DNS records were stored as individual resources using count instead of for_each in a list. Then, during a terraform apply, one of the first entries in the list was deleted ... and several hundred subsequent DNS entries were deleted as well, because their index shifted and Terraform, in this case, deleted and recreated the resources. What made it really bad was that the public cloud provider’s tight API limits ensured the new DNS records were recreated only slowly and in blocks of at most five at a time, instead of quickly in one go. That left almost all unrelated customer services offline for more than an hour. How do you explain such an incident to change management and the press spokesperson?
- Cross-state dependencies: Remote state references lead to unexpected side effects during apply or destroy. That means a Terraform instance works with data from a different state file than its own. "Oops, there was still a production bare metal machine for another customer in that network..."
- Tenant overlaps: Changes for one customer accidentally affect other tenants as well. Think, for example, of dynamically managed firewall rules in a shared environment.
- Total chaos: Things get really interesting when multiple of the above scenarios happen at once. If you’re lucky, the entire site is still redundantly replicated elsewhere.
Typical Blast Radius Scenarios
1. The Remote State Disaster
# State A: Network foundation
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
}
output "vpc_id" {
value = aws_vpc.main.id
}
# State B: Application (references State A)
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "terraform-states"
key = "network/terraform.tfstate"
}
}
resource "aws_instance" "app" {
[...]
subnet_id = data.terraform_remote_state.network.outputs.private_subnet_ids[0]
[...]
}
⚠️ The problem: If the VPC in State A is destroyed, State B loses its references. This leads to inconsistent states and requires manual terraform import or terraform state rm to fix. In many organizations, this also causes organizational problems, since networks and server instances are often managed in separate silos, and timely, constructive communication during such an incident is not always guaranteed.
2. The Multi-Tenant Chaos
A particularly critical scenario arises when multiple tenants (customers) share resources in the same state:
Example: Shared Infrastructure State
├── shared-infrastructure/ │ ├── customer-a-resources.tf │ ├── customer-b-resources.tf │ ├── customer-c-resources.tf │ └── shared-services.tf
A change for Customer A can unintentionally affect Customer B and C. Even worse, a terraform destroy could affect all customers at once.
That is why it is absolutely essential to isolate all tenants completely from each other. Yes, this may cost more money initially. But an outage is more expensive.
3. The Dependency Hell
Complex dependency chains between resources can lead to unpredictable cascading effects:
Dependency chain: 
A change at the beginning of the chain can have effects all the way to the end. This leads to unexpected side effects, mostly due to dependencies that are invisible in the code but calculated internally by Terraform.
The responsibility here actually lies with the respective Terraform providers. Dependencies also require that the provider not only passes input values unchecked and uncorrelated to the cloud provider’s API, but also implements at least a minimum level of logic and reasoning. And believe me, many providers are very, very bad at this.
Blast Radius Minimization: Strategies and Best Practices
By now, I’ve probably left you with more than a few new worry lines. So let’s now talk about how to prevent these issues in the first place.
Approach 1: State Segmentation Based on Blast Radius
The most effective method for controlling blast radius is thoughtful state segmentation. When designing an automation solution, we follow these architectural principles:
Isolation by Impact Level:
- Critical States: Core infrastructure with a high blast radius (network, IAM, DNS)
- Service States: Application-specific resources with a medium blast radius
- Ephemeral States: Temporary resources with minimal blast radius
# Example of a blast-radius-optimized structure in AWS
├── foundation/ # Critical infrastructure
│ ├── network-core/ # VPCs, Transit Gateways (high blast radius)
│ ├── security-baseline/ # IAM, KMS Keys (high blast radius)
│ └── dns-zones/ # Route53 Zones (medium blast radius)
│
├── platform/ # Platform services
│ ├── kubernetes-cluster/ # EKS/OKE clusters (medium blast radius)
│ ├── databases/ # RDS, DocumentDB (medium blast radius)
│ └── monitoring/ # CloudWatch, Grafana (low blast radius)
│
└── applications/ # Application layer
├── frontend-dev/ # Development environment (low blast radius)
├── frontend-prod/ # Production environment (medium blast radius)
└── batch-jobs/ # Batch processing (low blast radius)
Important: Whenever possible, take the rate of change into account. This means you should avoid having frequently changing states referenced by states that must remain more stable. If a resource is subject to regular changes every few weeks or months, it might be better to ensure that it cannot play a critical role in the infrastructure and instead place it in a dedicated ephemeral state.
High change rates and critical infrastructure are mutually exclusive - but where you draw the line is your own decision, and it is a decision you should make and document as early as possible.
We will discuss the rate of change and how to manage it in detail in a later article in this series.
Approach 2: Dependency Inversion with Remote State
Instead of creating direct dependencies, we defuse the situation using data sources and lifecycle preconditions. Let me explain this with an example.
The Problem: Direct Dependencies (Anti-Pattern)
# Anti-pattern: Direct dependency
resource "aws_instance" "app" {
subnet_id = aws_subnet.main.id
}
Let’s take a closer look:
- The EC2 instance references a subnet resource directly within the same state. This means both resources are coupled in the same terraform.tfstate file.
- A terraform destroy on the subnet will delete both resources simultaneously. This can also occur during a terraform apply if a change requires the subnet to be temporarily deleted and rebuilt, in which case the
aws_instancewill also be destroyed and redeployed. - The implication: even changes to the subnet can unintentionally affect the EC2 instance.
This is dangerous because:
- High blast radius: A change to the network can destroy the application - in the worst case, also the data stored locally on the EC2 instance.
- Coupled lifecycles: Subnet and EC2 instance must always be managed together. A change to the network automatically requires a change request for the application.
- Conflicting responsibility domains: The network team and the application team may end up blocking each other.
- Rollback issues: In case of failure, the EC2 instance may no longer be restorable from backup, because the network configuration in the backup no longer matches the current state reliably.
A Partial Solution: Dependency Inversion (Best Practice)
We are still largely powerless against changes (or mutations). However, we can protect ourselves against accidental destroy operations by using dependency inversion to decouple the EC2 instance from the networks.
# App State (consumes Network Outputs)
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "terraform-states"
key = "foundation/network/terraform.tfstate"
}
}
What’s different now?
- The VPC and subnet are located in a separate state (foundation/network/).
- The app no longer directly references the subnet but instead accesses it through the remote state data source.
- This means there is no longer a direct resource-to-resource dependency between the EC2 instance and the subnet.
The app is no longer directly dependent on the subnet resource, but rather on an abstract output of the network state. Indirectly, the dependency still exists.
Remote state dependencies are not a complete blast radius safeguard. They act more like a circuit breaker that gives you time to respond, but ultimately, dependencies still need to be resolved.
This is therefore only the first step, because changes to the network resource in the remote state can still affect our EC2 instance. That’s why we now take an additional step by implementing validation and, if needed, triggering a failsafe.
Validation and Defensive Programming
In locals.tf we define:
locals {
vpc_id = try(data.terraform_remote_state.network.outputs.vpc_id, null)
subnet_ids = try(data.terraform_remote_state.network.outputs.subnet_ids, [])
}
What’s happening here?
This implements defensive behavior: the try() function prevents errors if the remote state does not exist. If this happens, vpc_id is assigned the value null, and subnet_ids becomes an empty list (since a VPC can contain multiple subnets).
Now, several approaches are possible.
Option 1: Detect-Only Pattern
We now declare our EC2 instance with a lifecycle:
resource "aws_instance" "app" {
lifecycle {
precondition {
condition = can(data.terraform_remote_state.network.outputs.vpc_id)
error_message = "WARNING: Network state not available - using fallback configuration"
}
}
subnet_id = try(
data.terraform_remote_state.network.outputs.private_subnet_ids[0],
"subnet-fallback-12345" # Fallback to known, stable subnet ID
)
}
This example is highly simplified so you can understand the basic principle. In practice, it can certainly be improved and refined, I do not deny that. But the approach remains similar:
- If no VPC is defined in the remote state (local.vpc_id is then null), terraform plan will fail with the warning as an error message.
- If the VPC exists but the subnet ID does not, a fallback to another subnet ID is used. This can be hardcoded (ugly) or sourced from somewhere else - for simplicity's sake, I am showing the former here.
In this specific case, however, this would cause the server to be moved to another subnet, which means a destroy operation followed by a rebuild. That doesn't really help us, at least not with this type of resource. It might therefore make sense to define a lifecycle precondition for the subnet ID as well and force a failure during the plan phase. Or, alternatively, just prevent Terraform from tearing down the EC2 instance - as we will look at next.
Option 2: Prevent Destroy Pattern
This is how you prevent Terraform from destroying a resource and instead force it to fail with an error message:
resource "aws_instance" "app" {
lifecycle {
prevent_destroy = true # Prevents accidental deletion
precondition {
condition = can(data.terraform_remote_state.network.outputs.vpc_id)
error_message = "WARNING: Network state not available - using fallback configuration"
}
}
subnet_id = try(
data.terraform_remote_state.network.outputs.private_subnet_ids[0],
"subnet-fallback-12345" # Fallback to known, stable subnet ID
)
}
The only addition here is the line prevent_destroy = true, everything else in the example is identical to the previous one.
There is also a third variant that can be combined with this solution.
Option 3: Explicit Confirmation Pattern
Here, you set a Boolean variable to true in order to approve the automatic teardown and rebuild.
Warning: This does not protect against a teardown of the EC2 instance due to changes in the networks! This expression in the for_each loop only protects you from yourself, by requiring you to explicitly confirm via var.confirm_network_dependency_removal that you are aware of this risk. Therefore, only follow this approach if having a stable CI/CD pipeline is more important to you than the existence of the server instance - for example, in dev environments or in cases of strictly enforced immutability.
variable "confirm_network_dependency_removal" {
type = bool
default = false
}
data "terraform_remote_state" "network" {
backend = "s3"
config = {
bucket = "terraform-states"
key = "foundation/network/terraform.tfstate"
region = "eu-central-1"
}
}
locals {
vpc_ok = can(data.terraform_remote_state.network.outputs.vpc_id)
subnet_ok = can(data.terraform_remote_state.network.outputs.private_subnet_ids[0])
deploy_app = (
local.vpc_ok || var.confirm_network_dependency_removal
) && local.subnet_ok
app_instances = local.deploy_app ? { "main" = true } : {}
}
resource "aws_instance" "app" {
for_each = local.app_instances
ami = "ami-12345678"
instance_type = "t3.micro"
subnet_id = data.terraform_remote_state.network.outputs.private_subnet_ids[0]
lifecycle {
prevent_destroy = true
precondition {
condition = local.vpc_ok
error_message = "VPC missing – deployment denied"
}
precondition {
condition = local.subnet_ok
error_message = "Subnet missing – deployment denied"
}
}
tags = {
Name = "BlastRadiusProtected"
}
}
Approach 3: Blast Radius Guardrails with Lifecycle Rules
I already hinted at this in the explanations for Approach 2: Terraform provides several mechanisms to prevent accidental deletions.
Option 1: prevent_destroy for critical resources
We already discussed this above, but let us briefly revisit the concept:
# Prevent destroy for critical resources
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
lifecycle {
prevent_destroy = true
}
tags = {
Name = "Production-VPC"
Environment = "production"
BlastRadius = "high"
}
}
Note what exactly we are doing here: We protect dependent resources such as the subnet and EC2 instance by declaring the VPC as a critical resource and protecting it from deletion. This is, of course, only possible if the VPC is managed by us and not coming from a remote state.
Option 2: create_before_destroy for stateful resources
When a provider states that it is not possible to update the arguments of a resource during runtime, the resource must be destroyed and rebuilt. Since many resources in infrastructure are only allowed to exist once (like IP addresses), Terraform will destroy a resource first and then rebuild it.
However, it is possible to allow the destruction of a resource on the condition that the new resource is provisioned first, before the old resource is removed:
resource "aws_db_instance" "main" {
lifecycle {
create_before_destroy = true
ignore_changes = [
password, # Ignore password changes to prevent unnecessary replacements
]
}
[...]
}
Here, however, you yourself are responsible for ensuring that no conflicts occur. The old resource and the new one must be able to coexist; in the case of an IP address, which must be unique in the same network, it would be sensible to create the new resource without the IP address first, and then move the IP address from the old resource to the new one. This naturally increases complexity and can only be applied selectively.
Option 3: Conditional Destroy with Preconditions
The third option is to use a lifecycle precondition again and check a flag that determines whether a resource may be deleted or whether terraform plan should throw an error and abort:
variable "confirmed_destroy" {
type = bool
default = false
description = "Explicitely allows destruction of resources if set to `true`."
}
resource "aws_instance" "app" {
lifecycle {
precondition {
condition = var.environment != "production" || var.confirmed_destroy == true
error_message = "Production resources require explicit confirmation for destruction."
}
}
[...]
}
Approach 4: Professional Solution via Policy-as-Code (Terraform Enterprise)
The previous solutions all have one thing in common: they are, in some way, half-baked workarounds and require compromises. If you're looking for a professional solution, Terraform Enterprise is the answer. For enterprise environments, Terraform Enterprise offers deep Policy-as-Code functionality through Sentinel:
# Sentinel Policy: Blast Radius Control
import "tfplan/v2" as tfplan
# Prevent deletion of high blast radius resources
high_blast_radius_resources = [
"aws_vpc",
"aws_route53_zone",
"aws_iam_role"
]
main = rule {
all tfplan.resource_changes as _, resource {
resource.type not in high_blast_radius_resources or
resource.change.actions not contains "delete"
}
}
In this example, AWS VPCs, IAM roles and Route 53 DNS zones are first declared as critical infrastructure with a high blast radius.
In the second step, all attempts to delete resources of one of these types are intercepted by the corresponding rule. If this rule is triggered, Terraform blocks a terraform apply immediately after the plan phase and refuses further execution.
Conclusion (so far)
The blast radius in Terraform should be considered early, otherwise you expose yourself to significant risk. The threat can be somewhat mitigated in the free version of Terraform by applying various tricks and workarounds during module implementation, but it cannot be reliably prevented.
If you're looking for a professional-grade solution that can be enforced and audited company-wide, you should consider Terraform Enterprise with the Sentinel module. If your risk management team can quantify the risk and cost of an outage, a corresponding Terraform Enterprise license represents a form of insurance, whose cost and benefit can be directly compared.
Outlook
We have now covered in great detail what steps we can take to reduce the risk of an excessive blast radius.
But what do we do if it still happens? What options do we have to mitigate the resulting damage and bring the infrastructure back to an operational state?
That is what we will explore in the next part of this article series.
