















Terraform @ Scale non è una questione di utilizzo dello strumento. È una questione di operating model.
Senza un modello di governance strutturato emergono:
- fork dei moduli incontrollati
- standard di sicurezza divergenti
- responsabilità poco chiare
- rischi operativi in aumento
- superfici di attacco regolatorie
- un impatto finanziario significativo dovuto a configurazioni errate
Questo articolo conclusivo della nostra serie descrive in sintesi:
- un Terraform Operating Model trasversale
- principi di governance e di struttura
- responsabilità organizzative
- integrazione CI/CD e delle policy
- aggregazione del rischio a livello aziendale
- un blueprint completo per Terraform @ Scale
Target: CIO, CISO, Head of Platform Engineering, Cloud Architects.
Guida operativa per decisori e architetti
1. Il Terraform Operating Model (architettura di riferimento)
Terraform non scala con più codice. Scala piuttosto grazie a una struttura pulita.
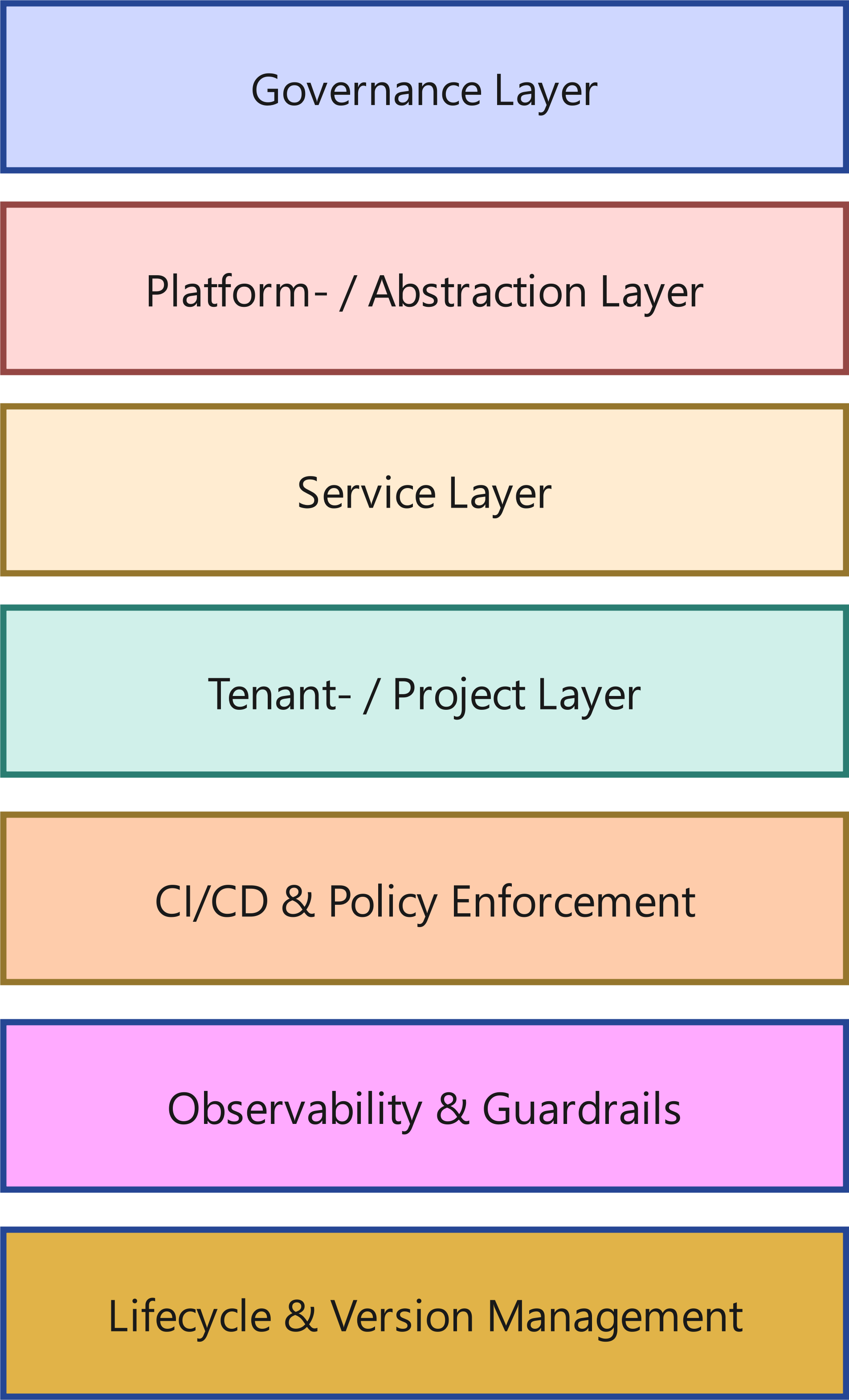 Un operating model robusto è composto da livelli chiaramente separati:
Un operating model robusto è composto da livelli chiaramente separati:
1.1 Governance Layer
- Policy-as-Code (Sentinel, OPA)
- Regole di compliance
- Standard di naming
- Requisiti di sicurezza
- Meccanismi di cost control
1.2 Layer di piattaforma / astrazione
- Moduli base
- Standard di rete
- Pattern IAM
- Fondamenta di logging & monitoring
- Security controls
1.3 Service Layer
- Moduli di servizio riutilizzabili
- Infrastruttura vicina all’applicazione
- Pattern database
- Pattern messaging
1.4 Tenant- / Project Layer
- Configurazione di prodotto o progetto
- Parametri specifici dell’environment
- Root module
1.5 CI/CD & Policy Enforcement
- Pipeline automatizzate
- Review obbligatorie
- Validazione del plan
- Policy check prima dell’apply
1.6 Observability & Guardrails
- Drift detection
- Monitoraggio dei deployment
- Audit trail
- Alerting in caso di violazioni di policy
1.7 Lifecycle- & Version management
- Versionamento dei moduli
- Versionamento semantico
- Strategie di deprecazione
- Percorsi di migrazione
L’aspetto decisivo: questi livelli esistono deliberatamente separati - sia tecnicamente sia organizzativamente.
2. Come orchestrare Terraform a livello aziendale
Terraform in contesto enterprise non è una raccolta di repository.
È un sistema orchestrato.
2.1 Struttura GitOps
Struttura consigliata:
- Repository di moduli base
- Repository di moduli di servizio
- Repository di environment/root
- Repository centralizzati di policy
Strategie di branching:
- Protected main branches
- Pull request review
- Tag di versione per release in produzione
2.2 Ruoli & responsabilità
- Team di piattaforma: moduli base & governance
- Team di prodotto: moduli di servizio & root module
- Security: definizione delle policy & review
- FinOps: controllo dei costi & reporting
Senza una chiara separazione dei ruoli nasce il caos.
Con una chiara separazione dei ruoli nasce la scalabilità.
2.3 Workspaces / Stacks / Environments
- Separazione chiara tra Dev / Stage / Prod
- Nessun environment switch implicito
- Nessuna manipolazione manuale dello state
2.4 Moduli base vs. moduli di servizio vs. root module
- Moduli base: standard tecnici
- Moduli di servizio: servizi riutilizzabili
- Root module: implementazione concreta
Questa separazione riduce in modo significativo il blast radius.
2.5 Processi di migrazione
- Strategie di upgrade di versione
- Canary deployment
- Rollout progressivi
- Regression testing prima della propagazione
2.6 Processi di review e automazione
- Pipeline obbligatorie
- Policy check
- Test automatizzati
- Nessun diritto di apply diretto in produzione
3. Blueprint: Terraform @ Scale nella pratica
Questo blueprint mostra un flusso di riferimento end-to-end che funziona in modo affidabile nel contesto enterprise: dalla modifica del modulo fino a un rollout auditabile su più team di prodotto - includendo governance, testing, propagazione e observability.
3.1 Target in una frase
Il team di piattaforma fornisce moduli base versionati + guardrail; i team di prodotto li consumano tramite root module chiaramente definiti; CI/CD impone test, policy e apply controllato; drift e audit girano in modo continuo.
3.2 Tipi di moduli & contratti
3.2.1 Moduli base
- definiscono standard tecnici (rete, baseline IAM, logging, encryption defaults)
- possono introdurre breaking changes - ma solo in modo controllato e raramente
- sono SemVer-strict: MAJOR.MINOR.PATCH
3.2.2 Moduli di servizio
- incapsulano servizi ricorrenti
- usano moduli base
- hanno interfacce stabili (input/output)
3.2.3 Root module
- “assemblies”: combinano moduli di servizio e moduli base per un environment concreto
- non contengono logica che appartiene ai moduli
- sono il punto in cui si parametrizza in modo specifico per prodotto/env (cosiddette "T-Shirt Sizes" con implementazione di requisiti e condizioni quadro vincolanti)
3.2.4 Regola di contract (semplice, ma efficace):
- I moduli forniscono output trattati come API.
- Breaking output changes = major version.
- Opzionale: fase di deprecazione (avviso), poi removal.
3.3 Mappa degli artefatti: cosa esiste dove?
3.3.1 Repository (struttura di esempio)
A) Moduli base (platform-owned)
- terraform-<provider>-network
- terraform-<provider>-iam
- terraform-<provider>-logging
- terraform-<provider>-kms
B) Moduli di servizio (shared, spesso curati dalla platform)
- terraform-<service>-rds
- terraform-<service>-kafka
- terraform-<service>-ecs
- terraform-<service>-oke
C) Root module / environments (product-owned, sotto governance)
- terraform-prod-app1
- terraform-stage-app1
- terraform-prod-app2
- terraform-prod-shared
D) Policy & controls (security-owned, integrati nella platform)
- policies-opa o policies-sentinel
- terraform-standards (tagging, naming, conventions)
E) Template CI/CD (platform-owned)
- pipelines-terraform-template
- pipelines-policy-gates
3.4 Governance gate: cosa può succedere dove?
Vale il principio: Se qualcosa è abbastanza importante da girare in produzione, è abbastanza importante da essere verificato in modo automatizzato.
Esempio: Sentinel come mandatory gate (AWS & OCI)
Perché “Policy-as-Code” non resti solo una parola da PowerPoint, ecco due esempi minimi che hanno subito senso nella pratica: la cifratura deve essere attiva - automaticamente, non “a sensazione”.
Esempio AWS: S3 non può esistere senza default encryption
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.aws_s3_bucket as bucket {
bucket.applied.server_side_encryption_configuration is not null
}
}Esempio OCI: i block volume devono essere cifrati
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.oci_core_volume as volume {
volume.applied.is_encrypted is true
}
}Importante: Queste sono volutamente policy “piccole” - ma mostrano il punto: la governance non si discute, si verifica. Tutto il resto è speranza con un’etichetta di audit.
Mandatory gate (prima di ogni apply in non-dev / prod)
- terraform fmt / validate
- terraform plan in CI, plan come artefatto
- Policy-as-Code (OPA/Sentinel)
- Security scan (ad es. tfsec/checkov) o equivalente
- Cost estimation (FinOps gate) - almeno indicazione del delta
- Review (min. 2 eyes, di cui 1 platform o security per modifiche sensibili)
- Apply solo via pipeline (niente “laptop-apply”)
3.5 Esempio di repo layout (root module)
Importante: I root module sono leggibili, piccoli e seguono standard. La complessità sta nei moduli, non nel root. Questo significa anche: i root module dovrebbero il più possibile solo comporre moduli; le risorse dovrebbero essere dichiarate direttamente solo in eccezioni motivate.
terraform-prod-app1/
main.tf
variables.tf
outputs.tf
backend.tf
env/
prod.tfvars
stage.tfvars
README.md
3.6 Il flusso end-to-end (blueprint)
 Fase 0 - situazione iniziale
Fase 0 - situazione iniziale
- I moduli base sono versionati (tag)
- I root module fissano le versioni dei moduli (nessun riferimento a “main branch”)
- Le policy sono attivate nel CI
Blueprint in code: i root module consumano moduli versionati (esempio OCI)
Così appare nella pratica: un root module che resta consapevolmente “stupido” e si limita a comporre. L’intelligenza sta nei moduli - e la stabilità nelle versioni pinnate.
# main.tf (Rootmodule: terraform-prod-app1)
module "network" {
source = "git::ssh://git@repo/platform/terraform-oci-network.git?ref=v2.4.0"
compartment_id = var.compartment_id
vcn_cidr = var.vcn_cidr
}
module "db" {
source = "git::ssh://git@repo/services/terraform-oci-db.git?ref=v1.3.2"
compartment_id = var.compartment_id
subnet_id = module.network.private_subnet_id
db_name = var.db_name
shape = var.db_shape
}Da ricordare: questo root module si può revieware. Questo root module si può auditare. E se qualcosa si rompe, sapete quale release del modulo ne è responsabile, invece di svegliarvi in un horrorfilm basato su diff.
Fase 1 - modifica nel modulo base (platform team)
Esempio: adattamento nel modulo di rete (ad es. opzione subnet aggiuntiva, default di logging, regole SG più restrittive).
Regole:
- PR con chiara change classification: PATCH/MINOR/MAJOR
- Voce di changelog + nota di migrazione (in caso di breaking)
- I test girano automaticamente (vedi 3.7)
Output:
Tag v2.4.0 (o v3.0.0 in caso di breaking)
Fase 2 - modulo release & distribuzione
Artefatti di release:
- Git tag + release note
- Documentazione del modulo aggiornata
- “Upgrade notes” per i consumer
Meccanica di distribuzione:
- I root module referenziano i moduli tramite versione (registry o Git tag)
- Opzionale: registry interna per centralizzare le approvazioni
Fase 3 - propagazione nei moduli di servizio (opzionale, ma spesso sensata)
Se i moduli di servizio usano il modulo base:
- PR nei moduli di servizio che recepiscono la nuova versione del modulo base
- Regression test a livello di modulo di servizio
- Release tag per i moduli di servizio
Fase 4 - update nei root module (team di prodotto)
Meccanica (consigliata):
- PR automatico (Dependency Bot / Renovate) alza la versione del modulo:
- base-network v2.3.1 → v2.4.0
- CI produce plan diff
- Il PR mostra:
- Modifiche alle risorse
- Risultati delle policy
- Indicazioni di costo
Decisione:
Merge solo se i gate sono verdi e la modifica è compresa.
Fase 5 - pipeline apply (controllato)
L’apply avviene:
- prima in DEV / INT
- poi STAGE
- poi PROD
Strategia di rollout (per modifiche critiche):
- Canary: prima 1 - 2 tenant non critici
- poi rollout a ondate (Wave 1 - N)
Principio:
Non scalate il coraggio - scalate il procedimento.
Fase 6 - observability & audit
Dopo l’apply:
- Log/audit trail:
- Chi ha fatto merge?
- Quale plan è stato applied?
- Quali policy check sono girati?
- Drift detection:
- Scheduled plan (read-only) + allarme in caso di drift
- Incident hook:
- Se drift / policy violation: ticket/alert
3.7 Testing blueprint: cosa viene testato e come?
A) Test di unità/contract del modulo
- Input validation test (variable validations)
- Output contract test (breaking detection)
- Static analysis
B) Integration test (ephemeral environment)
- stack temporanei per PR
- Apply + assertion (ad es. risorse esistono, tag impostati, cifratura attiva)
- Destroy alla fine (cleanup)
C) Regression test
- Controllo diff basato su snapshot per moduli critici
- Testcase “golden” per versione del modulo
Standard minimo:
Almeno un test di ephemeral apply per ogni release del modulo base deve essere eseguito; l’ideale sarebbero contract test ed eventualmente integration test dei moduli base tramite terraform test e il Terraform Testing Framework integrato (consigliato perché integrato in Terraform e standardizzato) oppure un testing harness equivalente. Altrimenti non è una release, è un lancio di moneta.
Esempio: terraform test come test di contract/default
Un test non deve essere “grande” per essere efficace. Già una singola assertion vi protegge dal classico: qualcuno cambia silenziosamente un default - e settimane dopo tutti si chiedono perché all’improvviso esplodono volumi di log e costi.
# tests/network_defaults.tftest.hcl
run "validate_defaults" {
command = plan
assert {
condition = module.network.enable_flow_logs == true
error_message = "I Flow Logs devono essere attivi per impostazione predefinita."
}
}Non è un test accademico. È una cintura di sicurezza. E sì: se non verificate una cosa del genere in modo automatizzato, ogni release alla fine è un lancio di moneta - solo che con budget di produzione.
3.8 Policy-Blueprint: Cosa deve essere sempre vero?
Esempi di policy che hanno praticamente sempre senso:
- Obbligo di tagging/owner/cost center
- Cifratura by default (storage, DB, secrets)
- Nessuna security group aperta (0.0.0.0/0) senza processo di eccezione
- Pattern IAM di least privilege (nessuna wildcard senza motivazione)
- Restrizioni su region/account/subscription
- Obbligo di approvazione per classi ad alto impatto sui costi
Gestione delle eccezioni:
- Eccezione solo via pull request (PR). Le eccezioni devono essere marcate come codice leggibile dalle macchine (ad es. annotation/tag/policy input), altrimenti si torna alla discussione invece che al processo. Una pull request impone trasparenza, review da parte di almeno un’altra persona, documentazione e un audit trail.
- con data di scadenza (expiry)
- con owner
- con ticket/motivazione
3.9 Blueprint di rollback e recovery
Il rollback con IaC non è sempre “git revert e va tutto bene”. Per questo:
- Prefer forward-fix per errori non distruttivi
- Operazioni sullo state solo con processo di emergenza
- Breaking changes devono avere un percorso di migrazione
- Backup/versioning per lo state e le risorse critiche
- Runbook per i failure mode frequenti (locking, throttling, provider bug)
3.10 Risultato: cosa ottenete con questo
- Governance dei moduli scalabile senza bottleneck
- Change riproducibili con responsabilità chiare
- Visibilità (plan/policy/cost) prima dell’apply
- Rollout controllato invece di “big bang”
- Auditabilità che non nasce “a richiesta”
Questo è il punto: Terraform @ Scale non è solo “più Terraform”. È anche un framework per l’organizzazione operativa e il change management.
3.11 Checklist del pipeline blueprint: Terraform deployment control flow (stage-by-stage)
Questo è il framework di controllo compatto per decisori. Se questi step vengono rispettati, Terraform è controllabile.
Un deployment Terraform può avvenire solo se:
- il codice è valido
- il plan è trasparente
- le policy sono soddisfatte
- le review sono state eseguite
- apply gira esclusivamente via pipeline
- audit & drift detection sono attivi
Se manca uno di questi punti, non è un esercizio controllato.
Stage 1 - Static validation (shift left)
Obiettivo: fermare gli errori prima che l’infrastruttura sia coinvolta.
- terraform fmt
- terraform validate
- Variable validations
- Linting
- Static security scan
Gate:
❌ errore → nessun merge del PR possibile
Stage 2 - Plan & trasparenza
Obiettivo: piena visibilità sulle modifiche.
- terraform plan in CI
- salvare il plan come artefatto
- analisi del diff (add/change/destroy)
- mostrare la differenza di costo
Gate:
❌ plan non verificato → nessun merge
Stage 3 - Policy enforcement
Obiettivo: imporre la governance, non discuterla.
- OPA/Sentinel policy check
- validazione del tagging
- encryption policy
- restrizioni IAM
- limitazioni region/account
Gate:
❌ violazione di policy → merge bloccato
✔ eccezione solo via pull request con motivazione & data di scadenza
Stage 4 - Review & approvazione
Obiettivo: controllo umano a complemento dell’automazione.
- almeno 2 reviewer
- security review per modifiche sensibili
- platform review per modifiche ai moduli base
Gate:
❌ PR non approvato → nessun apply
Stage 5 - Controlled apply
Obiettivo: deployment riproducibile e auditabile.
- apply solo via pipeline
- nessun apply manuale
- deployment in produzione serializzati
- opzionale: canary / wave rollout
Stage 6 - Post-apply observability
Obiettivo: controllo sostenibile dopo il deployment.
- salvare audit log
- drift detection (scheduled plan)
- monitoring su misconfiguration
- incident hook
4. Matrice dei rischi centrale: il quadro complessivo del rischio
I rischi di Terraform non nascono in modo isolato, ma si sommano.
Una matrice dei rischi non è un elemento decorativo. È un navigatore: dove è più probabile che succeda qualcosa - e quanto costa quando succede?
Scala: probabilità di accadimento (EW) e impatto (AW) ciascuno da 1 (basso) a 5 (alto).
Score = EW × AW.
Classe di rischio: 1 - 5 bassa, 6 - 10 media, 11 - 15 alta, 16 - 25 critica.
|
ID |
Rischio |
Categoria |
Causa tipica |
EW |
AW |
Score |
Indicatori precoci |
Controlli / contromisure |
Owner (tipico) |
|
R1 |
Blast radius dovuto a root module “troppo grandi” |
Esercizio |
Root module monolitici, segmentazione mancante, separazione mancante di stack/workspace |
4 |
5 |
20 |
Plan grandi (molte risorse), tempi di apply lunghi, rollback frequenti |
Tagliare i root module (domini/servizi), stack/env separati, rollout progressivi/canary |
Platform + Product |
|
R2 |
Version drift (provider/moduli/Terraform) |
Tecnica/esercizio |
Non pinnato/incoerente, toolchain diverse, processo di upgrade mancante |
5 |
4 |
20 |
Lockfile diversi, “works on my machine”, plan diff inspiegabili |
Version pinning + lockfile policy, flow Renovate/Dependabot, finestre di upgrade definite |
Platform |
|
R3 |
Rischi dello state (corruption, problemi di locking, interventi manuali) |
Esercizio |
Operazioni manuali sullo state, locking mancante, apply paralleli |
3 |
5 |
15 |
Conflitti di lock frequenti, “force-unlock”, state edit nei ticket |
Remote state con locking, serializzazione dell’apply, processo di emergenza per operazioni sullo state |
Platform |
|
R4 |
Policy assente o non applicata (policy drift) |
Security/governance |
Le policy esistono “come documento”, ma non come gate; eccezioni senza data di scadenza |
4 |
5 |
20 |
Finding ricorrenti, approvazioni manuali, eccezioni “temporanee” che restano |
Policy-as-Code (OPA/Sentinel) come gate obbligatorio, workflow di eccezione con expiry |
Security + Platform |
|
R5 |
Misconfigurazione IAM (over-permissioning, privilege escalation) |
Security |
Riutilizzo di pattern non sicuri, least-privilege review mancante, ownership poco chiara |
4 |
5 |
20 |
Ruoli troppo ampi, troppi admin, policy non reviewate |
Moduli IAM standardizzati, security review, scan (ad es. tfsec/checkov) + policy gate |
Security |
|
R6 |
Secrets nel posto sbagliato (state, log, variabili, Git) |
Security/esercizio |
Secrets come plain variable, output, secret backend mancanti |
3 |
5 |
15 |
Secrets in plan/log, manca “sensitive”, leak in Git |
Integrazione Vault/Secret Manager, output sensitive, pre-commit scanning, redaction |
Security + Platform |
|
R7 |
Catene di dipendenze & “hidden coupling” tra moduli |
Tecnica |
Cascate di data source/output, dipendenze implicite, contract mancanti |
4 |
4 |
16 |
Piccola modifica → grande diff, replacement inattesi, dipendenze cicliche |
Contract dei moduli (input/output), regole per breaking change, test + disciplina SemVer |
Platform |
|
R8 |
API limit / throttling in apply grandi |
Esercizio/tecnica |
Modifiche massive, parallelismo, limiti del provider |
3 |
4 |
12 |
Tempeste di retry, timeout, errori sporadici del provider |
Strategie di rate limit, batch più piccoli, apply serializzati, tuning del provider |
Platform |
|
R9 |
Drift (realtà ≠ codice) |
Esercizio/governance |
Modifiche manuali in console cloud, drift detection mancante |
4 |
4 |
16 |
Plan inattesi, incident “fix in console”, deviazioni progressive |
Drift detection (scheduled plan), restrizioni di ruoli/permessi, policy “no clickops” nel normale esercizio (resta consentito il break-glass manuale con tracciamento). |
Platform + Ops |
|
R10 |
Modifiche non testate (nessun regression testing per i moduli) |
Tecnica/esercizio |
Nessun test harness, nessun gate pre-prod, nessuna fase canary |
4 |
4 |
16 |
Breaking change solo in prod, alto tasso di hotfix |
Test dei moduli (unit/integration), ephemeral environment, pipeline gate |
Platform |
|
R11 |
Rischi di costo (overprovisioning / scalabilità incontrollata) |
FinOps/esercizio |
Budget/guardrail mancanti, taglie standard mancanti, nessuna review |
4 |
4 |
16 |
Esplosioni di costo, tag mancanti, risorse senza owner |
Tagging come policy, budget alert, cost estimation nel PR, tier standard |
FinOps + Platform |
|
R12 |
Incertezza organizzativa (ownership, responsabilità, approvazione) |
Organizzazione |
Confini platform/prodotto non chiariti, “tutti possono fare tutto”, RACI mancante |
5 |
3 |
15 |
Blocchi, ticket ping pong, shadow repo/fork |
RACI, repo policy, responsabilità chiare, interfaccia platform-prodotto |
Management + Platform |
Compressione: top risk (score ≥ 16)
- R1, R2, R4, R5, R7, R9, R10, R11 sono i tipici “classici enterprise”: alti fino a critici, perché si rafforzano a vicenda.
Vediamo inoltre:
- dove la governance è davvero necessaria (R4/R5/R6).
- dove una struttura pulita consente la scalabilità (R1/R2/R7/R10).
- dove si bruciano soldi, se nessuno guarda (R11).
5. Modello RACI per Terraform @ Scale
La pipeline definisce cosa succede.
La matrice RACI definisce chi è responsabile.
Solo entrambe insieme danno un operating model robusto.
Ruoli:
- Platform Team - standard dei moduli, CI/CD, governance tecnica
- Security / organizzazione CISO - policy, risk control
- Product / application team - utilizzo & configurazione dell’infrastruttura
- FinOps / controlling - controllo costi & trasparenza di budget
Definizione RACI:
- R (Responsible) - esegue
- A (Accountable) - ha la responsabilità complessiva
- C (Consulted) - viene coinvolto attivamente
- I (Informed) - viene informato
Matrice RACI sul flusso end-to-end
|
Fase |
Platform |
Security |
Product |
FinOps |
|
Sviluppare modulo base |
R |
C |
I |
I |
|
Rilasciare modulo base (release) |
A |
C |
I |
I |
|
Definire/modificare policy |
C |
R/A |
I |
C |
|
Sviluppare modulo di servizio |
R |
C |
C |
I |
|
Modificare root module (modifica di prodotto) |
C |
C |
R/A |
I |
|
Verifica delle policy nel CI |
R |
A |
C |
I |
|
Security review per modifiche sensibili |
C |
R/A |
C |
I |
|
Verifica dei costi prima del merge |
C |
I |
R |
A |
|
Apply in DEV |
R |
I |
C |
I |
|
Apply in PROD |
R |
C |
C |
I |
|
Drift detection & monitoring |
R/A |
C |
I |
I |
|
Approvazione eccezione (policy exception) |
C |
R/A |
C |
I |
|
Incident per misconfigurazione |
R |
C |
C |
I |
|
Escalation dei costi |
C |
I |
C |
R/A |
Interpretazione (importante per il management)
- Platform è operativamente responsabile.
- Security è responsabile delle policy.
- Product è responsabile delle modifiche funzionali.
- FinOps ha la responsabilità del budget - non Platform.
Questo modello evita due errori classici:
- Security diventa il deployment blocker.
- La piattaforma viene resa responsabile dei costi o delle decisioni di business.
6. Implicazioni di executive governance
Terraform non è un meccanismo automatico. L’uso di Terraform e di Infrastructure-as-Code da solo non crea una governance realmente esistente. Piuttosto, Terraform amplifica metodi e workflow già presenti. E se questi non sono corretti, il colpo può ritorcersi contro.
L’automazione dell’infrastruttura amplifica l’effetto. Nel positivo come nel negativo.
Prendiamo ad esempio un’azienda di medie dimensioni con 25 team IT, ciascuno con le proprie abitudini e modalità di lavoro - il risultato sarebbe, nonostante Terraform, un intreccio impenetrabile di moduli, pipeline e dipendenze non allineati tra loro. Non serve a nulla se ogni team è nella propria barca e rema per conto suo. Voi, come leadership, dovete assicurarvi che tutti procedano nella stessa direzione e allo stesso ritmo, con pagaie identiche. Con IaC, altrimenti, questi team divergono molto più velocemente e in modo più lineare tra loro e non formano più un insieme armonico.
Per CIO e CISO Terraform @ Scale significa a prima vista:
- L’infrastruttura diventa codice
- Il codice diventa rilevante per la governance
- La governance diventa automatizzabile
Ulteriori misure consigliate:
- Costruzione di un team di piattaforma dedicato
- Introduzione di meccanismi Policy-as-Code vincolanti
- Repository centralizzato per i moduli
- Linee guida di versioning definite
- Gate CI/CD obbligatori
- Architecture review regolari
7. Conclusione & prospettive
Terraform in ambito enterprise non è un tema di tool.
È piuttosto un modello di architettura e organizzazione.
Chi introduce Terraform senza un operating model scala l’incertezza.
Chi gestisce Terraform con una governance chiara scala la stabilità.
Prossimi livelli di evoluzione:
- Infrastructure testing frameworks
- Design for failure patterns
- Modelli di maturità del team di piattaforma
- Integrazione con service catalog
- Report di compliance automatizzati
Terraform @ Scale significa:
- Controllo senza blocchi.
- Standardizzazione senza perdita di innovazione.
- Velocità senza perdita di controllo.
E proprio lì si decide se l’infrastruttura resta un rischio, o diventa un vantaggio competitivo.

