
Terraform @ Scale ist keine Frage der Tool-Nutzung. Es ist eine Frage des Operating Models.
Ohne strukturiertes Governance-Modell entstehen:
- unkontrollierte Modul-Forks
- divergierende Sicherheitsstandards
- unklare Verantwortlichkeiten
- steigende Betriebsrisiken
- regulatorische Angriffsflächen
- erheblicher finanzieller Impact durch Fehlkonfigurationen
Dieser abschließende Artikel unserer Serie beschreibt zusammen:
- ein übergreifendes Terraform Operating Model
- Governance- und Strukturprinzipien
- organisatorische Verantwortlichkeiten
- CI/CD- und Policy-Integration
- Risikoaggregation auf Unternehmensebene
- einen vollständigen Blueprint für Terraform @ Scale
Zielgruppe: CIO, CISO, Head of Platform Engineering, Cloud Architects.
Operational Guide für Entscheider und Architekten
1. Das Terraform Operating Model (Referenzarchitektur)
Terraform skaliert nicht durch mehr Code. Es skaliert vielmehr durch eine saubere Struktur.
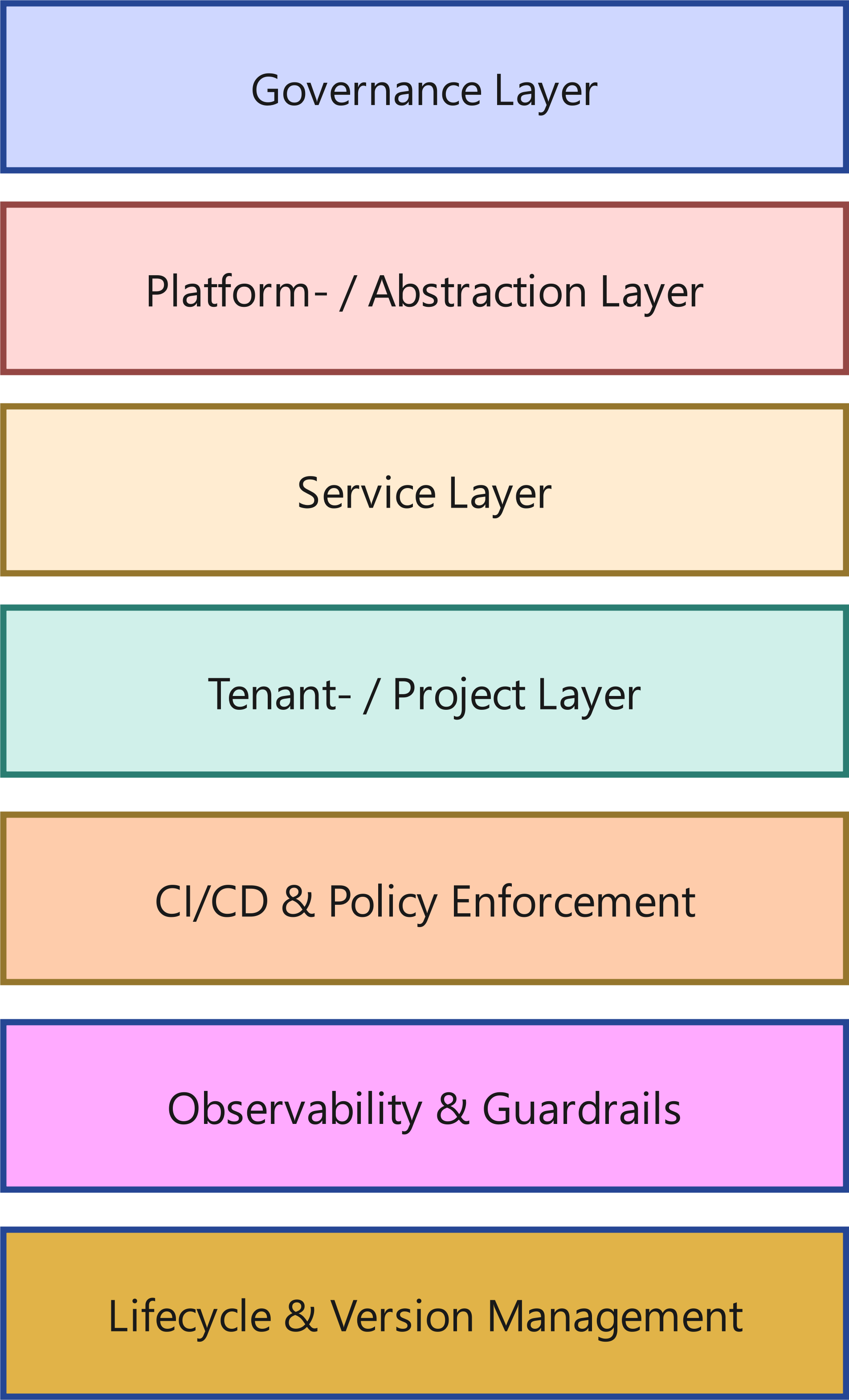 Ein belastbares Operating Model besteht aus klar getrennten Ebenen:
Ein belastbares Operating Model besteht aus klar getrennten Ebenen:
1.1 Governance Layer
- Policy-as-Code (Sentinel, OPA)
- Compliance-Regeln
- Naming-Standards
- Sicherheitsvorgaben
- Cost-Control-Mechanismen
1.2 Plattform- / Abstraktionslayer
- Basismodule
- Netzwerk-Standards
- IAM-Patterns
- Logging- & Monitoring-Grundlagen
- Security-Controls
1.3 Service Layer
- Wiederverwendbare Servicemodule
- Applikationsnahe Infrastruktur
- Datenbank-Patterns
- Messaging-Patterns
1.4 Tenant- / Project Layer
- Produkt- oder Projektkonfiguration
- Environment-spezifische Parameter
- Rootmodule
1.5 CI/CD & Policy Enforcement
- Automatisierte Pipelines
- Mandatory Reviews
- Plan-Validierung
- Policy-Checks vor Apply
1.6 Observability & Guardrails
- Drift Detection
- Monitoring von Deployments
- Audit-Trails
- Alerting bei Policy-Verletzungen
1.7 Lifecycle- & Versionsmanagement
- Modulversionierung
- Semantische Versionierung
- Deprecation-Strategien
- Migrationspfade
Das Entscheidende: Diese Ebenen existieren bewusst getrennt – technisch wie organisatorisch.
2. So orchestrieren Sie Terraform auf Unternehmensebene
Terraform im Enterprise-Kontext ist keine Sammlung von Repositories.
Es ist ein orchestriertes System.
2.1 GitOps-Struktur
Empfohlene Struktur:
- Basismodul-Repositories
- Servicemodul-Repositories
- Environment-/Root-Repositories
- Zentrale Policy-Repositories
Branch-Strategien:
- Protected Main Branches
- Pull-Request-Reviews
- Version-Tags für produktive Releases
2.2 Rollen & Verantwortlichkeiten
- Plattformteam: Basismodule & Governance
- Produktteams: Servicemodule & Rootmodule
- Security: Policy-Definition & Review
- FinOps: Kostenkontrolle & Reporting
Ohne klare Rollentrennung entsteht Chaos.
Mit klarer Rollentrennung entsteht Skalierbarkeit.
2.3 Workspaces / Stacks / Environments
- Klare Trennung zwischen Dev / Stage / Prod
- Keine impliziten Environment-Switches
- Keine manuelle State-Manipulation
2.4 Basismodule vs. Servicemodule vs. Rootmodule
- Basismodule: technische Standards
- Servicemodule: wiederverwendbare Services
- Rootmodule: konkrete Implementierung
Diese Trennung reduziert den Blast Radius erheblich.
2.5 Migrationsprozesse
- Version-Upgrade-Strategien
- Canary-Deployments
- Stufenweise Rollouts
- Regression Testing vor Propagation
2.6 Review- und Automatisierungsprozesse
- Pflicht-Pipelines
- Policy-Checks
- Automatisierte Tests
- Keine direkten Apply-Rechte in Produktion
3. Blueprint: Terraform @ Scale in der Praxis
Dieser Blueprint zeigt einen End-to-End-Referenzfluss, der im Enterprise-Kontext zuverlässig funktioniert: von der Moduländerung bis zum auditierbaren Rollout in mehrere Produktteams – inklusive Governance, Testing, Propagation und Observability.
3.1 Zielbild in einem Satz
Plattformteam liefert versionierte Basismodule + Guardrails; Produktteams konsumieren diese über klar definierte Rootmodule; CI/CD erzwingt Tests, Policy und kontrolliertes Apply; Drift und Audit laufen kontinuierlich mit.
3.2 Modul-Typen & Verträge
3.2.1 Basismodule
- definieren technische Standards (Netz, IAM-Baseline, Logging, Encryption Defaults)
- dürfen breaking changes machen – aber nur kontrolliert und selten
- sind SemVer-strikt: MAJOR.MINOR.PATCH
3.2.2 Servicemodule
- kapseln wiederkehrende Services
- nutzen Basismodule
- haben stabile Interfaces (Inputs/Outputs)
3.2.3 Rootmodule
- „Assemblies“: kombinieren Service- und Basismodule für ein konkretes Environment
- enthalten keine Logik, die in Module gehört
- sind die Stelle, an der produkt-/env-spezifisch parametrisiert wird (sogenannte "T-Shirt Sizes" mit Implementation von verbindlichen Vorgaben und Rahmenbedingungen)
3.2.4 Contract-Regel (einfach, aber wirksam):
- Module liefern Outputs, die wie APIs behandelt werden.
- Breaking Output Changes = Major Version.
- Optional: Deprecation-Phase (Warnung), dann Removal.
3.3 Artefakt-Landkarte: Was existiert wo?
3.3.1 Repositories (Beispiel-Struktur)
A) Basismodule (Platform-owned)
- terraform-<provider>-network
- terraform-<provider>-iam
- terraform-<provider>-logging
- terraform-<provider>-kms
B) Servicemodule (shared, häufig platform-kuratiert)
- terraform-<service>-rds
- terraform-<service>-kafka
- terraform-<service>-ecs
- terraform-<service>-oke
C) Rootmodule / Environments (Product-owned, unter Governance)
- terraform-prod-app1
- terraform-stage-app1
- terraform-prod-app2
- terraform-prod-shared
D) Policies & Controls (Security-owned, platform integriert)
- policies-opa oder policies-sentinel
- terraform-standards (Tagging, Naming, Conventions)
E) CI/CD Templates (Platform-owned)
- pipelines-terraform-template
- pipelines-policy-gates
3.4 Governance-Gates: Was darf wo passieren?
Es gilt das Prinzip: Wenn etwas wichtig genug ist, um in Produktion zu laufen, ist es wichtig genug, um automatisiert geprüft zu werden.
Beispiel: Sentinel als Mandatory Gate (AWS & OCI)
Damit “Policy-as-Code” nicht nur eine PowerPoint-Vokabel bleibt, hier zwei minimale Beispiele, die in der Praxis sofort Sinn ergeben: Verschlüsselung muss an sein – und zwar automatisch, nicht nach Bauchgefühl.
AWS-Beispiel: S3 darf nicht ohne Default Encryption
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.aws_s3_bucket as bucket {
bucket.applied.server_side_encryption_configuration is not null
}
}OCI-Beispiel: Block Volumes müssen verschlüsselt sein
import "tfplan/v2" as tfplan
main = rule {
all tfplan.resources.oci_core_volume as volume {
volume.applied.is_encrypted is true
}
}Wichtig: Das sind absichtlich “kleine” Policies – aber sie zeigen den Punkt: Governance wird nicht diskutiert, sie wird geprüft. Alles andere ist Hoffnung mit Audit-Label.
Mandatory Gates (vor jedem Apply in non-dev / prod)
- terraform fmt / validate
- terraform plan im CI, Plan als Artefakt
- Policy-as-Code (OPA/Sentinel)
- Security Scans (z. B. tfsec/checkov) oder äquivalent
- Cost Estimation (FinOps Gate) – mindestens Delta-Indikation
- Reviews (min. 2 Eyes, davon 1 Plattform oder Security bei sensiblen Änderungen)
- Apply nur über Pipeline (kein „Laptop-Apply“)
3.5 Beispiel-Repo-Layout (Rootmodule)
Wichtig: Rootmodule sind lesbar, klein, und folgen Standards. Die Komplexität liegt in Modulen, nicht im Root. Das bedeutet auch: Rootmodule sollten möglichst nur Module komponieren; Ressourcen sollen nur in begründeten Ausnahmen direkt deklariert werden.
terraform-prod-app1/
main.tf
variables.tf
outputs.tf
backend.tf
env/
prod.tfvars
stage.tfvars
README.md
3.6 Der End-to-End-Flow (Blueprint)
 Phase 0 – Ausgangslage
Phase 0 – Ausgangslage
- Basismodule sind versioniert (Tags)
- Rootmodule pinnen Modulversionen (keine „main branch“-Referenzen)
- Policies sind im CI aktiviert
Blueprint in Code: Rootmodule konsumieren versionierte Module (OCI-Beispiel)
So sieht das in der Praxis aus: ein Rootmodule, das bewusst “dumm” bleibt und nur zusammensetzt. Die Intelligenz liegt in den Modulen – und die Stabilität in den gepinnten Versionen.
# main.tf (Rootmodule: terraform-prod-app1)
module "network" {
source = "git::ssh://git@repo/platform/terraform-oci-network.git?ref=v2.4.0"
compartment_id = var.compartment_id
vcn_cidr = var.vcn_cidr
}
module "db" {
source = "git::ssh://git@repo/services/terraform-oci-db.git?ref=v1.3.2"
compartment_id = var.compartment_id
subnet_id = module.network.private_subnet_id
db_name = var.db_name
shape = var.db_shape
}Merke: Dieses Rootmodule kann man reviewen. Dieses Rootmodule kann man auditieren. Und wenn etwas kaputtgeht, wissen Sie, welches Modul-Release dafür verantwortlich war, statt in einem diff-basierten Horrorfilm aufzuwachen.
Phase 1 – Änderung im Basismodul (Platform Team)
Beispiel: Anpassung im Netzwerkmodul (z. B. zusätzliche Subnet-Option, Logging Default, restriktivere SG-Regeln).
Regeln:
- PR mit klarer Change-Classification: PATCH/MINOR/MAJOR
- Changelog-Eintrag + Migrationshinweis (bei Breaking)
- Tests laufen automatisch (siehe 3.7)
Output:
Tag v2.4.0 (oder v3.0.0 bei Breaking)
Phase 2 – Modul-Release & Distribution
Release-Artefakte:
- Git Tag + Release Notes
- Modul-Dokumentation aktualisiert
- „Upgrade Notes“ für Consumer
Distribution-Mechanik:
- Rootmodule referenzieren Module via Version (Registry oder Git Tag)
- Optional: interne Registry, um Freigaben zu zentralisieren
Phase 3 – Propagation in Servicemodule (optional, aber häufig sinnvoll)
Wenn Servicemodule das Basismodul nutzen:
- PRs in Servicemodulen, die neue Basismodul-Version übernehmen
- Regression Tests auf Servicemodul-Ebene
- Release Tag für Servicemodule
Phase 4 – Update in Rootmodulen (Product Teams)
Mechanik (empfohlen):
- Automatischer PR (Dependency Bot / Renovate) hebt Modulversion an:
- base-network v2.3.1 → v2.4.0
- CI erzeugt Plan-Diff
- PR zeigt:
- Ressourcenänderungen
- Policy-Ergebnisse
- Kostenindikationen
Entscheidung:
Merge nur, wenn Gates grün sind und die Änderung verstanden ist.
Phase 5 – Pipeline Apply (kontrolliert)
Apply erfolgt:
- zuerst in DEV / INT
- danach STAGE
- danach PROD
Rollout-Strategie (für kritische Änderungen):
- Canary: 1–2 nichtkritische Tenants zuerst
- danach Wellen-Rollout (Wave 1–N)
Prinzip:
Sie skalieren nicht den Mut – Sie skalieren das Verfahren.
Phase 6 – Observability & Audit
Nach Apply:
- Log/Audit Trail:
- Wer hat gemerged?
- Welcher Plan wurde applied?
- Welche Policy-Checks liefen?
- Drift Detection:
- Scheduled plan (read-only) + Alarm bei Drift
- Incident Hooks:
- Wenn Drift / Policy Violation: Ticket/Alert
3.7 Testing-Blueprint: Was wird wie getestet?
A) Modul-Unit/Contract Tests
- Input Validation Tests (Variable Validations)
- Output Contract Tests (Breaking detection)
- Static Analysis
B) Integration Tests (Ephemeral Environments)
- temporäre Stacks pro PR
- Apply + Assertions (z. B. Ressourcen existieren, Tags gesetzt, Encryption aktiv)
- Destroy am Ende (Cleanup)
C) Regression Tests
- Snapshot-basierte Diff-Prüfung für kritische Module
- „Golden“ Testcases pro Modulversion
Minimalstandard:
Mindestens ein Ephemeral Apply-Test pro Basismodul-Release muss durchgeführt werden, ideal wären Contract-Tests und ggf. Integration Tests der Basismodule mittels terraform test und dem integrierten Terraform Testing Framework (empfohlen, da in Terraform integriert und standardisiert) oder einem äquivalenten Testing Harness. Ansonsten ist es kein Release, sondern ein Münzwurf.
Beispiel: terraform test als Contract-/Default-Test
Ein Test muss nicht “groß” sein, um wirksam zu sein. Schon eine einzelne Assertion schützt Sie vor dem Klassiker: jemand dreht stillschweigend ein Default um – und Wochen später fragt sich jeder, warum plötzlich Log-Volumen und Kosten explodieren.
# tests/network_defaults.tftest.hcl
run "validate_defaults" {
command = plan
assert {
condition = module.network.enable_flow_logs == true
error_message = "Flow Logs müssen standardmäßig aktiv sein."
}
}Das ist kein akademischer Test. Das ist ein Sicherheitsgurt. Und ja: Wenn Sie so etwas nicht automatisiert prüfen, ist jedes Release am Ende ein Münzwurf – nur eben mit Produktionsbudget.
3.8 Policy-Blueprint: Was muss immer wahr sein?
Beispiele für Policies, die praktisch immer Sinn ergeben:
- Tagging/Owner/CostCenter Pflicht
- Verschlüsselung by default (Storage, DB, Secrets)
- Keine offenen Security Groups (0.0.0.0/0) ohne Ausnahmeprozess
- IAM Least Privilege Patterns (keine Wildcards ohne Begründung)
- Region/Account/Subscription Restriktionen
- Genehmigungspflicht für kostentreibende Klassen
Exception-Handling:
- Ausnahme nur via Pull Request (PR). Ausnahmen müssen als maschinenlesbarer Code markiert sein (z. B. Annotation/Tag/Policy-Input), sonst wird es wieder Diskussion statt Prozess. Ein Pull Request erzwingt Transparenz, Review durch mindestens eine andere Person, Dokumentation und einen Audit-Trail.
- mit Ablaufdatum (Expiry)
- mit Owner
- mit Ticket/Begründung
3.9 Rollback- und Recovery-Blueprint
Rollback ist bei IaC nicht immer „git revert und alles ist gut“. Deshalb:
- Prefer forward-fix bei nicht-destruktiven Fehlern
- State-Operationen nur mit Notfallprozess
- Breaking Changes müssen Migrationspfad haben
- Backup/Versioning für State & kritische Ressourcen
- Runbooks für häufige Failure Modes (Locking, throttling, provider bugs)
3.10 Ergebnis: Was Sie damit erreichen
- Skalierbare Modul-Governance ohne Bottleneck
- Reproduzierbare Changes mit klaren Verantwortlichkeiten
- Sichtbarkeit (Plan/Policy/Cost) vor dem Apply
- Kontrollierter Rollout statt „Big Bang“
- Auditierbarkeit, die nicht auf Zuruf entsteht
Das ist der Punkt: Terraform @ Scale ist nicht nur „mehr Terraform“. Es ist ebenso ein Framework für Betriebsorganisation und Change Management.
3.11 Pipeline-Blueprint-Checkliste: Terraform Deployment Control Flow (Stage-by-Stage)
Das hier ist der kompakte Kontrollrahmen für Entscheider. Wenn diese Schritte eingehalten werden, ist Terraform kontrollierbar.
Ein Terraform-Deployment darf nur stattfinden, wenn:
- Code valide ist
- Plan transparent ist
- Policies erfüllt sind
- Reviews erfolgt sind
- Apply ausschließlich über Pipeline läuft
- Audit & Drift Detection aktiv sind
Fehlt einer dieser Punkte, ist es kein kontrollierter Betrieb.
Stage 1 – Static Validation (Shift Left)
Ziel: Fehler stoppen, bevor Infrastruktur betroffen ist.
- terraform fmt
- terraform validate
- Variable Validations
- Linting
- Static Security Scan
Gate:
❌ Fehler → kein PR-Merge möglich
Stage 2 – Plan & Transparenz
Ziel: Vollständige Sicht auf Änderungen.
- terraform plan im CI
- Plan-Artefakt speichern
- Diff-Analyse (Add/Change/Destroy)
- Kosten-Differenz anzeigen
Gate:
❌ Ungeprüfter Plan → kein Merge
Stage 3 – Policy Enforcement
Ziel: Governance erzwingen, nicht diskutieren.
- OPA/Sentinel Policy Checks
- Tagging-Validierung
- Encryption-Policy
- IAM-Restriktionen
- Region-/Account-Beschränkungen
Gate:
❌ Policy-Verstoß → Merge blockiert
✔ Ausnahme nur via Pull Request mit Begründung & Ablaufdatum
Stage 4 – Review & Freigabe
Ziel: Menschliche Kontrolle ergänzend zur Automatisierung.
- Mindestens 2 Reviewer
- Security-Review bei sensiblen Änderungen
- Platform-Review bei Basismodul-Änderungen
Gate:
❌ Kein genehmigter PR → kein Apply
Stage 5 – Controlled Apply
Ziel: Reproduzierbares, auditierbares Deployment.
- Apply nur über Pipeline
- Kein manuelles Apply
- Serialisierte Produktion-Deployments
- Optional: Canary / Wave Rollout
Stage 6 – Post-Apply Observability
Ziel: Nachhaltige Kontrolle nach dem Deployment.
- Audit-Log speichern
- Drift Detection (scheduled plan)
- Monitoring auf Fehlkonfiguration
- Incident Hooks
4. Zentrale Risikomatrix: Das Gesamt-Risikobild
Terraform-Risiken entstehen nicht isoliert, sondern sie addieren sich.
Eine Risikomatrix ist kein Deko-Element. Sie ist ein Navigationsgerät: Wo knallt’s am ehesten - und was kostet es, wenn es knallt?
Skala: Eintrittswahrscheinlichkeit (EW) und Auswirkung (AW) jeweils 1 (niedrig) bis 5 (hoch).
Score = EW × AW.
Risikoklasse: 1–5 niedrig, 6–10 mittel, 11–15 hoch, 16–25 kritisch.
|
ID |
Risiko |
Kategorie |
Typische Ursache |
EW |
AW |
Score |
Frühindikatoren |
Kontrollen / Gegenmaßnahmen |
Owner (typisch) |
|
R1 |
Blast Radius durch „zu große“ Rootmodule |
Betrieb |
Monolithische Rootmodule, fehlende Segmentierung, fehlende Stacks/Workspaces-Trennung |
4 |
5 |
20 |
Große Plans (viele Ressourcen), lange Apply-Zeiten, häufige Rollbacks |
Rootmodule schneiden (Domänen/Services), getrennte Stacks/Envs, progressive Rollouts/Canaries |
Platform + Product |
|
R2 |
Version Drift (Provider/Module/Terraform) |
Technik/Betrieb |
Ungepinnt/inkonsistent, unterschiedliche Toolchains, fehlender Upgrade-Prozess |
5 |
4 |
20 |
Unterschiedliche Lockfiles, „works on my machine“, unerklärliche Plan-Diffs |
Version Pinning + Lockfile-Policy, Renovate/Dependabot-Flow, definierte Upgrade-Windows |
Platform |
|
R3 |
State-Risiken (Corruption, Locking-Probleme, manuelle Eingriffe) |
Betrieb |
Manuelle State-Operationen, fehlendes Locking, parallele Applies |
3 |
5 |
15 |
Häufige Lock-Konflikte, „force-unlock“, State-Edits in Tickets |
Remote State mit Locking, Apply-Serialisierung, Notfallprozess für State-Operationen |
Platform |
|
R4 |
Policy fehlt oder ist nicht durchgesetzt (Policy Drift) |
Security/Governance |
Policies existieren „als Dokument“, aber nicht als Gate; Ausnahmen ohne Ablaufdatum |
4 |
5 |
20 |
Wiederkehrende Findings, manuelle Freigaben, „temporäre“ Ausnahmen bleiben |
Policy-as-Code (OPA/Sentinel) als Pflicht-Gate, Exception-Workflow mit Expiry |
Security + Platform |
|
R5 |
IAM-Fehlkonfiguration (Over-Permissioning, Privilege Escalation) |
Security |
Wiederverwendung unsicherer Patterns, fehlende Least-Privilege-Review, unklare Ownership |
4 |
5 |
20 |
Breite Rollen, zu viele Admins, unreviewte Policies |
Standardisierte IAM-Module, Security Reviews, Scans (z.B. tfsec/checkov) + Policy Gates |
Security |
|
R6 |
Secrets im falschen Ort (State, Logs, Variablen, Git) |
Security/Betrieb |
Secrets als plain variables, Outputs, fehlende Secret-Backends |
3 |
5 |
15 |
Secrets in Plans/Logs, „sensitive“ fehlt, Git-Leaks |
Vault/Secret Manager Integration, sensitive Outputs, Pre-Commit-Scanning, Redaction |
Security + Platform |
|
R7 |
Abhängigkeitsketten & „Hidden Coupling“ zwischen Modulen |
Technik |
Datenquellen-/Outputs-Kaskaden, implizite Abhängigkeiten, fehlende Contracts |
4 |
4 |
16 |
Kleine Änderung → großer Diff, unerwartete Replacements, zyklische Abhängigkeiten |
Modul-Contracts (Inputs/Outputs), Breaking-Change-Regeln, Tests + SemVer diszipliniert |
Platform |
|
R8 |
API Limits / Throttling bei großen Applies |
Betrieb/Technik |
Massenänderungen, Parallelität, Provider-Limits |
3 |
4 |
12 |
Retry-Stürme, timeouts, sporadische Provider-Fehler |
Rate-Limit-Strategien, kleinere Batches, serialisierte Applies, Provider-Tuning |
Platform |
|
R9 |
Drift (Realität ≠ Code) |
Betrieb/Governance |
Manuelle Änderungen in Cloud-Konsole, fehlende Drift-Erkennung |
4 |
4 |
16 |
Unerwartete Plans, Incident „Fix in Console“, schleichende Abweichungen |
Drift Detection (scheduled plans), Rollen-/Rechte-Restriktionen, „No ClickOps“-Policy im Normalbetrieb (manuelles Break-Glass mit Protokollierung bleibt zulässig). |
Platform + Ops |
|
R10 |
Ungetestete Änderungen (kein Regression Testing für Module) |
Technik/Betrieb |
Kein Test-Harness, kein Pre-Prod-Gate, keine Canary-Stufen |
4 |
4 |
16 |
Breaking Changes erst in Prod, hohe Hotfix-Rate |
Modul-Tests (unit/integration), Ephemeral Environments, Pipeline-Gates |
Platform |
|
R11 |
Kostenrisiken (Overprovisioning / unkontrollierte Skalierung) |
FinOps/Betrieb |
Fehlende Budgets/Guardrails, fehlende Standardgrößen, kein Review |
4 |
4 |
16 |
Kostenexplosionen, fehlende Tags, Ressourcen ohne Owner |
Tagging als Policy, Budget Alerts, Cost Estimation im PR, Standard-Tiers |
FinOps + Platform |
|
R12 |
Organisatorische Unklarheit (Ownership, Verantwortung, Genehmigung) |
Organisation |
Plattform-/Produktgrenzen ungeklärt, „jeder kann alles“, fehlende RACI |
5 |
3 |
15 |
Blockaden, Ticket-Pingpong, Schatten-Repos/Forks |
RACI, Repo-Policy, klare Zuständigkeiten, Plattform-Produkt-Interface |
Management + Platform |
Verdichtung: Top-Risiken (Score ≥ 16)
- R1, R2, R4, R5, R7, R9, R10, R11 sind die typischen „Enterprise-Klassiker“: hoch bis kritisch, weil sie sich gegenseitig verstärken.
Wir sehen außerdem:
- wo Governance wirklich nötig ist (R4/R5/R6).
- wo eine saubere Struktur eine Skalierung ermöglicht (R1/R2/R7/R10).
- wo Geld verbrennt, wenn niemand hinsieht (R11).
5. RACI-Modell für Terraform @ Scale
Die Pipeline definiert was passiert.
Die RACI-Matrix definiert wer verantwortlich ist.
Erst beides zusammen ergibt ein belastbares Operating Model.
Rollen:
- Platform Team – Modul-Standards, CI/CD, technische Governance
- Security / CISO-Organisation – Policies, Risiko-Controls
- Product / Application Teams – Nutzung & Konfiguration der Infrastruktur
- FinOps / Controlling – Kostenkontrolle & Budget-Transparenz
RACI-Definition:
- R (Responsible) – führt aus
- A (Accountable) – trägt Gesamtverantwortung
- C (Consulted) – wird aktiv eingebunden
- I (Informed) – wird informiert
RACI-Matrix über den End-to-End-Flow
|
Phase |
Platform |
Security |
Product |
FinOps |
|
Basismodul entwickeln |
R |
C |
I |
I |
|
Basismodul freigeben (Release) |
A |
C |
I |
I |
|
Policy definieren/ändern |
C |
R/A |
I |
C |
|
Servicemodul entwickeln |
R |
C |
C |
I |
|
Rootmodul ändern (Produktänderung) |
C |
C |
R/A |
I |
|
Policy-Prüfung im CI |
R |
A |
C |
I |
|
Security-Review bei sensiblen Änderungen |
C |
R/A |
C |
I |
|
Kostenprüfung vor Merge |
C |
I |
R |
A |
|
Apply in DEV |
R |
I |
C |
I |
|
Apply in PROD |
R |
C |
C |
I |
|
Drift Detection & Monitoring |
R/A |
C |
I |
I |
|
Ausnahmegenehmigung (Policy Exception) |
C |
R/A |
C |
I |
|
Incident bei Fehlkonfiguration |
R |
C |
C |
I |
|
Kosteneskalation |
C |
I |
C |
R/A |
Interpretation (wichtig für Führungsebene)
- Platform ist operativ verantwortlich.
- Security ist policy-verantwortlich.
- Product verantwortet fachliche Änderungen.
- FinOps trägt Budgetverantwortung – nicht Platform.
Dieses Modell verhindert zwei klassische Fehler:
- Security wird zum Deployment-Blocker.
- Plattform wird für Kosten oder Business-Entscheidungen verantwortlich gemacht.
6. Executive Governance Implikationen
Terraform ist kein Selbstläufer. Der Einsatz von Terraform und Infrastructure-as-Code alleine sorgt noch nicht für eine real existierende Governance. Vielmehr verstärkt Terraform bereits vorhandene Methoden und Workflows. Und wenn diese nicht stimmen, kann der Schuss auch nach hinten losgehen.
Eine Infrastruktur-Automatisierung verstärkt die Wirkung. Im Positiven wie im Negativen.
Nehmen Sie als Beispiel ein mittleres Unternehmen mit 25 IT-Teams an, von welchen jedes seine eigenen Gewohnheiten und Arbeitsweisen lebt - das Ergebnis wäre, trotz Terraform, dann ein undurchdringliches Geflecht aus nicht aufeinander abgestimmten Modulen, Pipelines und Abhängigkeiten. Es bringt nichts, wenn jedes Team in seinem eigenen Boot sitzt und rudert. Sie als Führungskraft müssen sicherstellen, dass alle auch in die gleiche Richtung und im gleichen Takt mit identischen Paddeln unterwegs sind. Mit IaC driften diese Teams ansonsten nur viel schneller und geradliniger voneinander weg und bilden kein harmonisches Ganzes mehr.
Für CIO und CISO bedeutet Terraform @ Scale auf den ersten Blick:
- Infrastruktur wird Code
- Code wird Governance-relevant
- Governance wird automatisierbar
Empfohlene weitere Maßnahmen:
- Aufbau eines dedizierten Plattformteams
- Einführung verbindlicher Policy-as-Code-Mechanismen
- Zentralisiertes Modul-Repository
- Definierte Versionierungsrichtlinien
- Verpflichtende CI/CD-Gates
- Regelmäßige Architektur-Reviews
7. Fazit & Ausblick
Terraform im Enterprise-Umfeld ist kein Tool-Thema.
Es ist vielmehr ein Architektur- und Organisationsmodell.
Wer Terraform ohne Operating Model einführt, skaliert Unsicherheit.
Wer Terraform mit klarer Governance betreibt, skaliert Stabilität.
Nächste Ausbaustufen:
- Infrastructure Testing Frameworks
- Design for Failure Patterns
- Plattformteam-Reifegradmodelle
- Integration mit Service Catalogs
- Automatisierte Compliance-Reports
Terraform @ Scale bedeutet:
- Kontrolle ohne Blockade.
- Standardisierung ohne Innovationsverlust.
- Geschwindigkeit ohne Kontrollverlust.
Und genau dort entscheidet sich, ob Infrastruktur ein Risiko bleibt, oder ein Wettbewerbsvorteil wird.
