









Sono le 14:30 di un normale martedì pomeriggio. Il team DevOps di un fornitore di servizi finanziari svizzero avvia come di consueto la propria pipeline Terraform per il test mensile di Disaster Recovery. 300 macchine virtuali, 150 backend di load balancer, 500 record DNS e innumerevoli regole di rete devono essere provisionati nella regione di backup.
Dopo 5 minuti, la pipeline si interrompe. HTTP 429: Too Many Requests.
Le successive 3 ore vengono spese dal team per ripulire manualmente le risorse parzialmente provisionate, mentre il management guarda nervosamente l’orologio.
Il test di DR è fallito prima ancora di iniziare.
Leggi tutto: Terraform @ Scale - Parte 5a: comprendere gli API Limits

La durata dei certificati TLS sarà drasticamente ridotta: i decisori IT devono agire ORA!
Da marzo 2026, la validità massima dei certificati server sarà dimezzata prima a 200 giorni, poi progressivamente a 100 e infine a 47 giorni.
Le aziende prive di una strategia Enterprise‑PKI rischiano colli di bottiglia operativi e problemi di compliance visibili ai clienti.
I fatti - Delibera del CA/Browser Forum
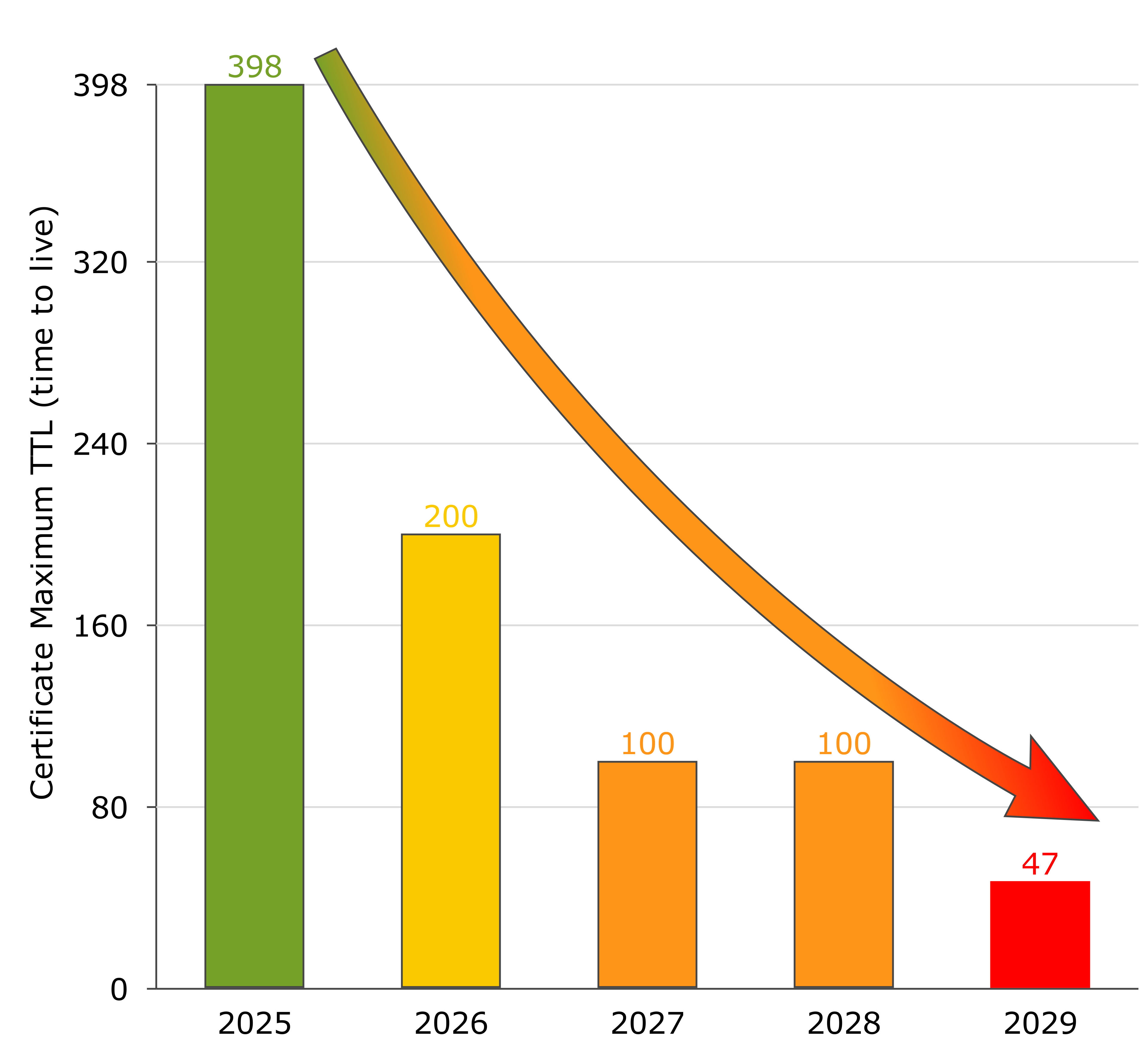 Il CA/Browser Forum ha adottato con il Ballot SC‑081 v3 dell'11 aprile 2025 una roadmap vincolante per la riduzione della durata dei certificati:
Il CA/Browser Forum ha adottato con il Ballot SC‑081 v3 dell'11 aprile 2025 una roadmap vincolante per la riduzione della durata dei certificati:
| Data chiave | Durata massima | Frequenza di rinnovo |
|---|---|---|
| 15 marzo 2026 | 200 giorni | ~2× all'anno |
| 15 marzo 2027 | 100 giorni | ~4× all'anno |
| 15 marzo 2029 | 47 giorni | ~8× all'anno |
Tutti i principali produttori di browser hanno annunciato che, a partire da tali date, bloccheranno i certificati più lunghi come non validi. (CA/Browser Forum, Business Wire)
Questa decisione è definitiva - non ci saranno proroghe.
Impatto sul business - Cosa significa per la Sua azienda
Il carico operativo aumenta quasi in modo esponenziale
Gli intervalli più brevi moltiplicano l’impegno richiesto ai Suoi team:
- Oggi: 1 rinnovo/anno
- 2026: 2 rinnovi/anno
- 2027: 4 rinnovi/anno
- 2029: 8 rinnovi/anno
Ora immagini di avere in uso circa 100 certificati TLS per i Suoi webserver pubblici e per la protezione dei servizi interni e della comunicazione interna. Nelle aziende di medie e grandi dimensioni, ciò può facilmente tradursi in diverse migliaia di certificati individuali.
Il tempo in cui gli ordini di nuovi certificati e la loro installazione potevano essere eseguiti manualmente è quindi finito.
Senza automazione, i Suoi ingegneri passerebbero la maggior parte del tempo a procurarsi, distribuire e controllare certificati.
Rischio di interruzione dovuto a errore umano
Già oggi, secondo uno studio del Ponemon Institute, il 73 % delle interruzioni non pianificate è causato da certificati scaduti o gestiti in modo errato. (mcpmag.com)
Un aumento di otto volte dei rinnovi moltiplica inevitabilmente il rischio che un certificato venga trascurato in produzione.
Compliance e complessità degli audit
Ogni riduzione della durata richiede prove supplementari - in particolare nei settori regolamentati. Il tracciamento manuale con fogli di calcolo o script isolati non è una soluzione scalabile.
Perché gli approcci standard non sono sufficienti
| Approccio | Punti di forza | Fattori limitanti |
|---|---|---|
| Let’s Encrypt | Gratuito, automazione via ACME | Nessun modello centrale di policy o ruoli, nessun log di audit, nessuna CA privata |
| Servizi Cloud‑PKI | Pronti all'uso | Vendor lock‑in, ostacoli in ambienti multi‑cloud, governance limitata |
| CA tradizionali | Ancora affidabili come ancore di fiducia | Processi di ordine manuali, mancanza di integrazione API, problemi di scalabilità |
La nostra offerta - La risposta Enterprise alla riduzione della durata dei certificati
 Implementiamo PKI e gestione dei certificati basandoci su HashiCorp Vault (dal Q4/2025 disponibile anche come IBM Vault). Che venga utilizzata la variante gratuita (Open Source) o la versione Enterprise dipende esclusivamente dalle Sue specifiche esigenze.
Implementiamo PKI e gestione dei certificati basandoci su HashiCorp Vault (dal Q4/2025 disponibile anche come IBM Vault). Che venga utilizzata la variante gratuita (Open Source) o la versione Enterprise dipende esclusivamente dalle Sue specifiche esigenze.
Governance PKI centralizzata
Vault funge da Certificate Authority interna e impone policy coerenti su tutti gli ambienti – On‑Premise, AWS, OCI o Multi‑Cloud.
Automazione senza vincoli di fornitore
L’approccio API‑first consente un'integrazione continua in CI/CD ed elimina i touchpoint manuali durante l'emissione, il rinnovo o la revoca.
Audit‑Trail a prova di compliance
Ogni passaggio – dalla generazione della chiave alla revoca – viene registrato in modo immutabile. La prontezza agli audit è quindi garantita sin dall'inizio.
ROI misurabile
Le esperienze documentate da HashiCorp mostrano una riduzione del carico operativo superiore al 60 % in ambienti comparabili. Più breve è la durata, maggiore è l’effetto.
Opzioni strategiche di azione
| Opzione | Rischio | Adatto per |
|---|---|---|
| Mantenere lo status quo | Rischio massimo: sovraccarico del personale, interruzioni, audit findings | Infrastrutture ridotte con pochi certificati esterni |
| Servizio Cloud‑PKI | Medio: lock‑in, strategia multi‑cloud limitata | Workload mono‑cloud senza vincoli normativi stringenti |
| Enterprise‑PKI con HashiCorp Vault | Basso: pieno controllo, scalabilità, auditabilità | Aziende con applicazioni critiche e roadmap multi‑cloud |
Considerazioni su tempistiche e budget
- Bloccare il budget entro il 2025 – La prima riduzione avverrà a metà dell’esercizio fiscale 2026.
- Pianificare un anticipo di 6–9 mesi per l’introduzione di processi e strumenti.
- Fase pilota: iniziare con servizi meno critici, raccogliere KPI e poi scalare.
Perché ICT.technology è il Suo Trusted Advisor

- Partner HashiCorp con consulenti Vault certificati
- Esperienza in ambito legale e normativo: profonda conoscenza in FinTech, Health‑Care, Industria
- Metodologia end‑to‑end: dalla consulenza strategica all’implementazione IaC (Terraform‑Stacks, Ansible, OCI, AWS) fino all’operatività PKI gestita
- Modelli di successo collaudati da numerosi progetti
Prossimi passi
Pronto per la trasformazione PKI?
Prenoti un appuntamento per un assessment non vincolante e una strategia Vault su misura.
Consigliamo poi il seguente approccio:
- Assessment PKI: analizzare l’inventario attuale e il livello di maturità
- Definire l’architettura target: On‑Premise, Cloud o ibrida
- Elaborare una strategia PKI: adattata alle Sue esigenze
- Pilot / Proof‑of‑Concept con Vault: a basso rischio, misurabile, scalabile
- Roll‑out: migrazione graduale dei sistemi critici per il business
Fonti
- CA/Browser Forum, Ballot SC‑081v3, 11 aprile 2025 (CA/Browser Forum)
- BusinessWire: “CA/Browser Forum Passes Ballot to Reduce SSL/TLS Certificates to 47 Day Maximum Term”, 14 aprile 2025 (Business Wire)
- Ponemon Institute: “Key and Certificate Errors Survey”, 2020 (73 % interruzioni) (mcpmag.com)
- HashiCorp Case Study “Running HashiCorp with HashiCorp”, 2021 – riduzione dei costi oltre il 60 % (HashiCorp - PDF download)

Nell'ultima parte di questa serie abbiamo mostrato come fonti dati apparentemente innocue all'interno di moduli Terraform possano trasformarsi in un serio problema di performance. Esecuzioni di terraform plan della durata di diversi minuti, pipeline instabili ed effetti di throttling delle API fuori controllo sono state le conseguenze.
Ma come si può evitare elegantemente e in modo sostenibile questa trappola di scalabilità?
In questa parte presentiamo pattern architetturali collaudati con cui centralizzare le Data Sources, iniettarle in modo efficiente dal punto di vista delle risorse e ottenere così esecuzioni Terraform rapide, stabili e prevedibili, anche con centinaia di istanze di moduli.
Inclusi: tre strategie scalabili, una guida passo-passo collaudata nella pratica e una checklist di Best Practices per moduli infrastrutturali pronti per la produzione.
Leggi tutto: Terraform @ Scale - Parte 4b: Best Practices per Data Sources scalabili

Le Data Sources di Terraform sono uno strumento molto usato per popolare dinamicamente le variabili con valori reali dell'ambiente cloud in uso. Tuttavia, il loro utilizzo in infrastrutture dinamiche richiede una certa lungimiranza. Basta ad esempio un innocuo data.oci_identity_availability_domains all'interno di un modulo - e all’improvviso ogni terraform plan impiega minuti anziché secondi. Perché 100 istanze del modulo significano 100 chiamate API, e il suo provider cloud inizia a limitare il traffico (throttling). Benvenuti nel mondo dell’amplificazione API indesiderata attraverso le Data Sources.
In questo articolo Le mostrerò perché le Data Sources nei moduli Terraform possono rappresentare un problema di scalabilità.
Leggi tutto: Terraform @ Scale - Parte 4a: le Data Sources sono pericolose!

Neanche l’architettura infrastrutturale più sofisticata può prevenire ogni errore. È quindi fondamentale monitorare in modo proattivo le operazioni Terraform - in particolare quelle che potrebbero avere effetti distruttivi. L’obiettivo è rilevare tempestivamente modifiche critiche e attivare automaticamente degli allarmi, prima che si verifichi un raggio d’azione incontrollato.
Certo – il suo System Engineer Le farà sicuramente notare che Terraform mostra l’intero piano prima dell’esecuzione di un apply e che tale esecuzione deve essere approvata manualmente digitando "yes".
Quello che però il suo Engineer non Le dice: in realtà non legge mai davvero il piano prima di eseguirlo.
«Andrà tutto bene.»
Leggi tutto: Terraform @ Scale - Parte 3c: Monitoraggio e allerta per eventi di Blast Radius