
Wenn ein einziges Modul-Update 47 Teams lahmlegt...
Es ist Montagmorgen, 10:30 Uhr. Das Platform-Engineering-Team eines großen Anbieters für Managed Cloud Services hat gerade ein "harmloses" Update des Basismoduls für VM-Instanzen von v1.3.2 auf v1.4.0 veröffentlicht. Die Änderung? Ein neues, aber obligatorisches Freeform-Tag zur Kostenstellenzuordnung von Ressourcen.
Was niemand auf dem Radar hat: Den Senior Engineer, der einst als Entscheidungsträger vehement darauf bestand, sämtliche Terraform-Module in einem einzigen Git-Repository abzulegen. “Versionierung ist zuviel Micromanagement. So ist es aufgeräumter. Und macht weniger Arbeit”, hat er damals gesagt.
Der gleiche Montag, 15:00 Uhr nachmittags: 47 Teams von unterschiedlichen Kunden melden bisher, dass ihre CI/CD-Pipelines fehlschlagen. Der Grund? Ihre Root-Module referenzieren die vom Anbieter bereitgestellten, aktualisierten Module, aber niemand hat die neuen Parameter in den eigenen Root-Modulen implementiert. Die Compliance-Prüfung des Anbieters ist aktiv und lehnt die Terraform-Runs wegen fehlender obligatorischer Tags ab. Was als Verbesserung geplant war, hat sich in einen organisationsweiten Stillstand mit massiver Außenwirkung auf Hostingkunden verwandelt.
Willkommen in der Welt der Modulabhängigkeiten bei Terraform @ Scale.
Weiterlesen: Terraform @ Scale - Teil 6a: Verstehen und Verwalten von verschachtelten Modulen

Im vorherigen Artikel 5a haben wir gesehen, wie schnell große Terraform‑Rollouts an API‑Limits prallen, etwa wenn DR‑Tests hunderte Ressourcen parallel erstellen und 429‑Fehler lawinenartig Retries auslösen. Diese Fortsetzung schließt jetzt dort an und zeigt, wie Sie mit dem API Gateway von Oracle Cloud Infrastructure und Amazon API Gateway Limits bewusst managen, sauber observieren und per „Policy as Code“ betriebsfest machen.
Es ist 14:30 Uhr an einem gewöhnlichen Dienstagnachmittag. Das DevOps-Team eines Schweizer Finanzdienstleisters startet routinemäßig seine Terraform-Pipeline für das monatliche Disaster-Recovery-Testing. 300 virtuelle Maschinen, 150 Load Balancer Backends, 500 DNS-Einträge und unzählige Netzwerkregeln sollen in der Backup-Region provisioniert werden.
Nach 5 Minuten bricht die Pipeline ab. HTTP 429: Too Many Requests.
Die nächsten 3 Stunden verbringt das Team damit, halb provisionierte Ressourcen manuell zu bereinigen, während das Management nervös auf die Uhr schaut.
Der DR-Test ist gescheitert, bevor er überhaupt begonnen hat.
Weiterlesen: Terraform @ Scale - Teil 5a: API Limits verstehen

TLS‑Zertifikat‑Laufzeiten werden drastisch verkürzt: IT‑Entscheider müssen die Weichen JETZT stellen!
Ab März 2026 halbiert sich die maximale Gültigkeit von Server-Zertifikaten zuerst auf 200 Tage, dann schrittweise auf 100 und schließlich 47 Tage.
Unternehmen ohne Enterprise‑PKI‑Strategie riskieren operative Engpässe und für die Kunden sichtbare Compliance-Probleme.
Die Fakten - Beschluss des CA/Browser Forums
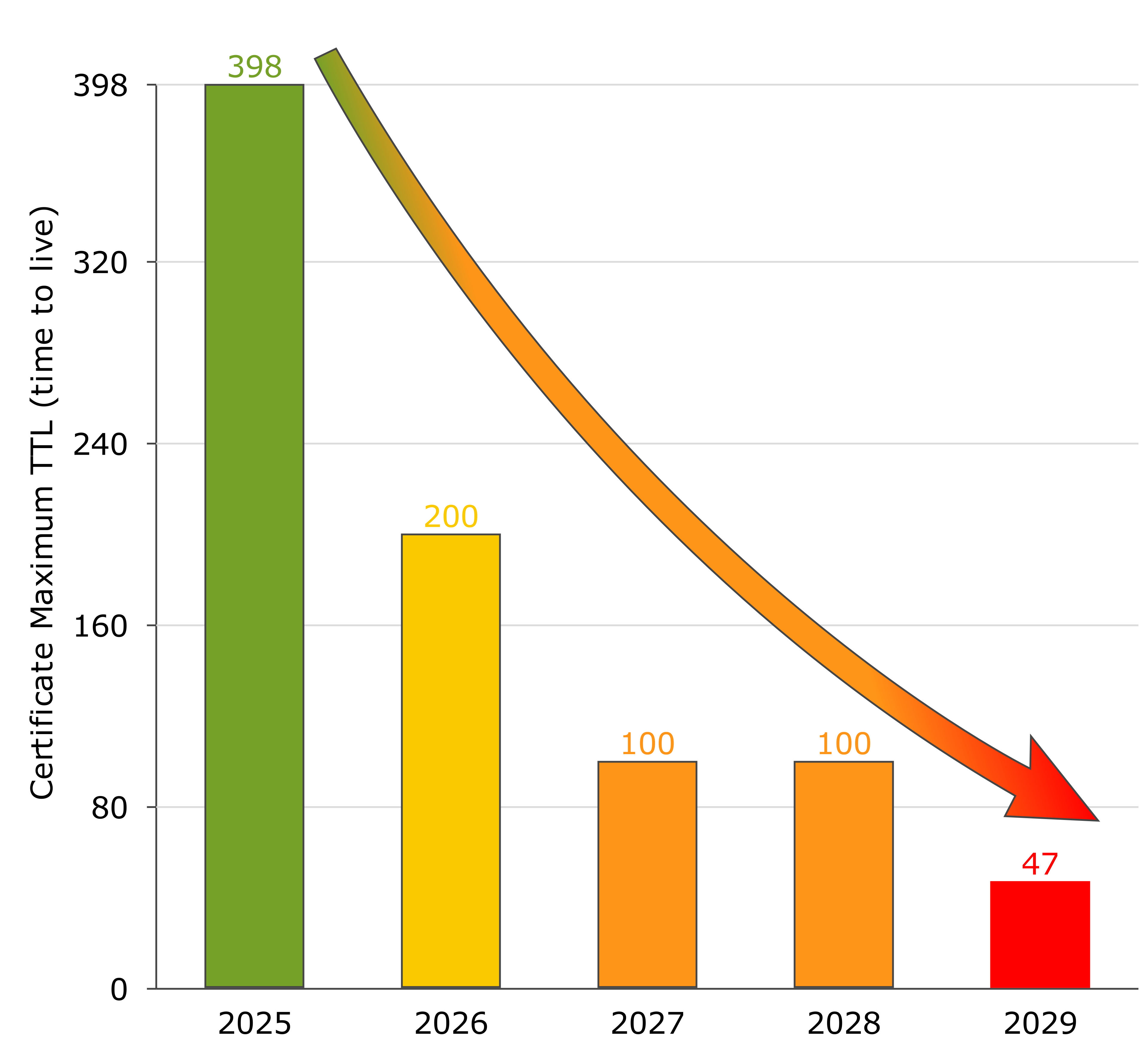 Das CA/Browser Forum hat mit Ballot SC‑081 v3 am 11. April 2025 einen verbindlichen Fahrplan zur Laufzeitverkürzung verabschiedet:
Das CA/Browser Forum hat mit Ballot SC‑081 v3 am 11. April 2025 einen verbindlichen Fahrplan zur Laufzeitverkürzung verabschiedet:
| Stichtag | Maximale Laufzeit | Erneuerungsrhythmus |
|---|---|---|
| 15. März 2026 | 200 Tage | ~2× pro Jahr |
| 15. März 2027 | 100 Tage | ~4× pro Jahr |
| 15. März 2029 | 47 Tage | ~8× pro Jahr |
Alle großen Browser‑Hersteller haben angekündigt, längere Zertifikate ab diesen Daten als ungültig zu blockieren. (CA/Browser Forum, Business Wire)
Diese Entscheidung ist final - es wird keine Gnadenfrist geben.
Business Impact - Was das für Ihr Unternehmen bedeutet
Operative Belastung steigt nahezu exponentiell
Die kürzeren Intervalle vervielfachen die Aufwände Ihrer Teams:
- Heute: 1 Erneuerung/Jahr
- 2026: 2 Erneuerungen/Jahr
- 2027: 4 Erneuerungen/Jahr
- 2029: 8 Erneuerungen/Jahr
Jetzt stellen Sie sich vor, Sie haben für Ihre öffentlichen Webserver und die Absicherung Ihrer internen Services und der internen Kommunikation vielleicht 100 TLS-Zertifikate im Einsatz. Bei mittleren und größeren Unternehmen werden daraus schnell mehrere tausend individuelle Zertifikate.
Die Zeiten, in denen Bestellungen neuer Zertifikate und deren Installation von Hand durchgeführt werden können, sind damit vorbei.
Ohne Automatisierung würden Ihre Engineers einen Großteil ihrer Zeit mit Beschaffung, Verteilung und Kontrolle von Zertifikaten verbringen.
Ausfallrisiko durch menschliche Fehler
Bereits heute führen laut Ponemon‑Studie 73 % der ungeplanten Ausfälle auf abgelaufene oder falsch verwaltete Zertifikate zurück.(mcpmag.com)
Eine Verachtfachung der Erneuerungen vervielfacht zwangsläufig das Risiko, dass ein Zertifikat im Produktivbetrieb übersehen wird.
Compliance‑ und Audit‑Komplexität
Jede Laufzeitverkürzung erzwingt zusätzliche Nachweise – insbesondere in regulierten Branchen. Manuelles Tracking mit Tabellen oder Einzelskripten skaliert hier nicht.
Warum Standard‑Ansätze nicht genügen
| Ansatz | Stärken | Limitierende Faktoren |
|---|---|---|
| Let’s Encrypt | Kostenfrei, ACME‑Automatisierung | Kein zentrales Policy‑ oder Rollenmodell, keine Audit‑Logs, keine privaten CAs |
| Cloud‑PKI‑Dienste | Schnell einsatzbereit | Vendor Lock‑in, Multi‑Cloud‑Hürden, eingeschränkte Governance |
| Traditionelle CAs | Bewährte Vertrauensanker | Manuelle Bestellprozesse, fehlende API‑Integration, Skalierungsprobleme |
Unser Angebot - Die Enterprise‑Antwort auf verkürzte Zertifikatslaufzeiten
 Wir implementieren PKI und Zertifikatsmangement auf Basis von HashiCorp Vault (ab Q4/2025 auch als IBM Vault bekannt). Ob hierbei die kostenfreie Variante (Open Source) oder die Enterprise-Version eingesetzt wird, entscheiden alleine Sie anhand Ihres genauen Bedarfsfalls.
Wir implementieren PKI und Zertifikatsmangement auf Basis von HashiCorp Vault (ab Q4/2025 auch als IBM Vault bekannt). Ob hierbei die kostenfreie Variante (Open Source) oder die Enterprise-Version eingesetzt wird, entscheiden alleine Sie anhand Ihres genauen Bedarfsfalls.
Zentrale PKI‑Governance
Vault fungiert als interne Certificate Authority und erzwingt konsistente Policies über alle Umgebungen – On‑Premise, AWS, OCI oder Multi‑Cloud.
Automatisierung ohne Anbieterbindung
Der API‑first‑Ansatz erlaubt durchgängige CI/CD‑Integration und eliminiert menschliche Touchpoints bei Ausstellung, Verlängerung oder Widerruf.
Compliance‑ready Audit‑Trails
Jeder Schritt – von der Schlüsselgenerierung bis zum Revoke – wird unveränderlich protokolliert. Audit‑Readiness ist damit ab Werk gegeben.
Messbarer ROI
HashiCorp‑Erfahrungsberichte zeigen über 60 % Reduktion des operativen Aufwands in vergleichbaren Umgebungen. Je kürzer die Laufzeiten, desto größer der Effekt.
Strategische Handlungsoptionen
| Option | Risiko | Geeignet für |
|---|---|---|
| Status quo beibehalten | Höchstes Risiko: Personelle Überlastung, Ausfälle, Audit‑Findings | Kleine Landschaften mit wenigen externen Zertifikaten |
| Cloud‑PKI‑Service | Mittel: Lock‑in, eingeschränkte Multi‑Cloud‑Strategie | Mono‑Cloud‑Workloads ohne strenge Regulatorik |
| Enterprise‑PKI mit HashiCorp Vault | Niedrig: Volle Kontrolle, skalierbar, auditierbar | Unternehmen mit kritischen Anwendungen und Multi‑Cloud‑Roadmap |
Timing‑ und Budget‑Überlegungen
- Budget noch 2025 sichern – Die erste Reduktion greift mitten im FY 2026.
- 6–9 Monate Vorlauf für Prozess‑ & Tool‑Einführung einplanen.
- Pilotphase: Starten Sie mit weniger kritischen Diensten, sammeln Sie KPIs, skalieren Sie dann.
Warum ICT.technology Ihr Trusted Advisor ist

- HashiCorp‑Partner mit zertifizierten Vault‑Consultants
- Recht & Regulatorik: Tiefe Erfahrung in FinTech, Health‑Care, Industrie
- End‑to‑End‑Methodik: Von der strategischen Beratung über IaC‑Implementierung (Terraform‑Stacks, Ansible, OCI, AWS) bis zum Managed PKI‑Betrieb
- Bewährte Erfolgsmuster aus einer Vielzahl von Projekten
Nächste Schritte
Bereit für die PKI‑Transformation?
Buchen Sie einen Termin für ein unverbindliches Assessment und eine maßgeschneiderte Vault‑Strategie.
Danach empfehle ich als Vorgehen:
- PKI‑Assessment: Aktuelles Inventar & Reifegrad bestimmen
- Zielarchitektur definieren: On‑Premise, Cloud oder Hybrid
- PKI-Strategie entwerfen: Individuell auf Ihre Bedürfnisse abgestimmt
- Pilot / Proof-of-Concept mit Vault: Risikoarm, messbar, skalierbar
- Roll‑out: Stufenweise Migration geschäftskritischer Systeme
Quellen
- CA/Browser Forum, Ballot SC‑081v3, 11. April 2025 (CA/Browser Forum)
- BusinessWire: „CA/Browser Forum Passes Ballot to Reduce SSL/TLS Certificates to 47 Day Maximum Term“, 14. April 2025 (Business Wire)
- Ponemon Institute: „Key and Certificate Errors Survey“, 2020 (73 % Ausfälle) (mcpmag.com)
- HashiCorp Case Study „Running HashiCorp with HashiCorp“, 2021 – 60 %+ Kostensenkung (HashiCorp - PDF download)

Im letzten Teil dieser Serie haben wir gezeigt, wie harmlos wirkende Data Sources in Terraform-Modulen zu einem ernsthaften Performance-Problem werden können. Minutenlange terraform plan-Laufzeiten, instabile Pipelines und unkontrollierbare API-Throttling-Effekte waren die Folge.
Doch wie vermeidet man diese Skalierungsfalle elegant und nachhaltig?
In diesem Teil stellen wir bewährte Architektur-Patterns vor, mit denen Sie Data Sources zentralisieren, ressourcenschonend injizieren und so auch bei hundertfachen Modulinstanzen schnelle, stabile und vorhersehbare Terraform-Ausführungen erreichen.
Mit dabei: drei skalierbare Lösungsstrategien, eine praxiserprobte Schritt-für-Schritt-Anleitung und eine Best Practices Checkliste für produktionsreife Infrastrukturmodule.
Weiterlesen: Terraform @ Scale - Teil 4b: Best Practices für skalierende Data Sources