









现在是一个普通星期二下午的14:30。一家瑞士金融服务商的DevOps团队例行启动其Terraform流水线,执行每月的灾难恢复测试(Disaster-Recovery-Testing)。计划在备用区域(Backup-Region)中部署300台虚拟机、150个负载均衡器后端、500条DNS记录以及无数网络规则。
5分钟后,流水线中断。HTTP 429: Too Many Requests。
接下来的3个小时,团队花费大量时间手动清理部分已创建的资源,而管理层则紧张地盯着时钟。
灾备测试还未真正开始就已经宣告失败。

TLS 证书有效期将被大幅缩短:IT 决策者必须现在就做出战略决策!
自 2026 年 3 月起,服务器证书的最长期限将先缩短至 200 天,随后逐步降低至 100 天,最终为 47 天。
缺乏企业级 PKI 策略的组织将面临运营瓶颈以及客户可感知的合规性问题。
事实依据 - CA/Browser Forum 的决议
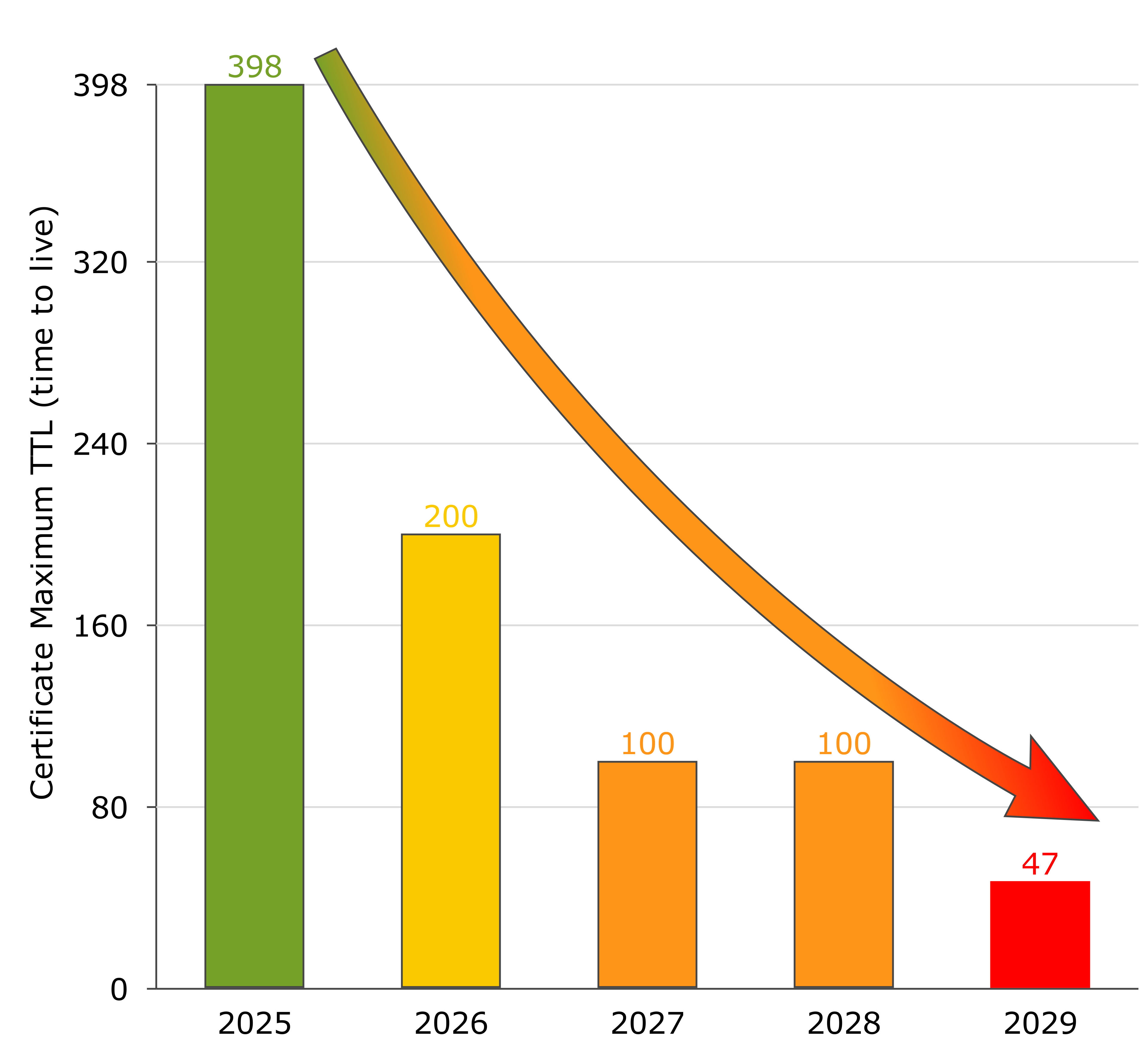 CA/Browser Forum 已于2025 年 4 月 11 日通过Ballot SC‑081 v3,正式制定了证书有效期缩短的执行时间表:
CA/Browser Forum 已于2025 年 4 月 11 日通过Ballot SC‑081 v3,正式制定了证书有效期缩短的执行时间表:
| 生效日期 | 最长期限 | 更新频率 |
|---|---|---|
| 2026 年 3 月 15 日 | 200 天 | 每年约 2 次 |
| 2027 年 3 月 15 日 | 100 天 | 每年约 4 次 |
| 2029 年 3 月 15 日 | 47 天 | 每年约 8 次 |
所有主流浏览器厂商均已宣布,从上述日期起将阻止接受超出规定期限的证书。(CA/Browser Forum, Business Wire)
该决议为最终决定 - 不会有宽限期。
业务影响 - 对贵企业意味着什么
运维压力呈指数级上升
缩短的证书更新周期将显著增加团队负担:
- 当前: 每年 1 次更新
- 2026 年: 每年 2 次更新
- 2027 年: 每年 4 次更新
- 2029 年: 每年 8 次更新
试想,贵企业可能正在为公共 Web 服务器、内部服务通信和系统安全部署了约 100 个 TLS 证书。对于中型或大型企业而言,这个数量轻松增长至数千个独立证书。
手动申请和安装证书的时代将不复存在。
如果不实现自动化,您的工程师将花费大量时间用于证书的申请、分发和验证。
人为错误导致的故障风险
根据 Ponemon 研究,目前73% 的计划外故障源于证书过期或管理不当。(mcpmag.com)
更新频率提升 8 倍,势必增加生产环境中被遗漏的证书数量,从而放大故障风险。
合规性与审计复杂度
每一次有效期缩短都将带来额外的证明义务,尤其是在高度监管的行业中。使用表格或脚本进行人工追踪将难以满足扩展性和合规性需求。
为何传统方法已不再适用
| 方案 | 优势 | 限制因素 |
|---|---|---|
| Let’s Encrypt | 免费,支持 ACME 自动化 | 缺乏集中策略管理、角色模型、审计日志,不支持私有 CA |
| 云端 PKI 服务 | 部署快速 | 厂商绑定风险高,跨云使用受限,治理能力有限 |
| 传统 CA | 具备成熟信任机制 | 流程手动化、缺乏 API 集成、扩展性差 |
我们的解决方案 - 应对缩短证书周期的企业级方案
 我们基于 HashiCorp Vault(自 2025 年第四季度起也称为 IBM Vault)为您构建 PKI 和证书管理体系。您可根据自身需求选择免费开源版本或 Enterprise 版本。
我们基于 HashiCorp Vault(自 2025 年第四季度起也称为 IBM Vault)为您构建 PKI 和证书管理体系。您可根据自身需求选择免费开源版本或 Enterprise 版本。
集中式 PKI 治理
Vault 可作为内部证书颁发机构(CA)运行,并在本地、AWS、OCI 或多云环境中强制执行统一策略。
无供应商绑定的自动化
以 API 为核心的架构支持端到端的 CI/CD 集成,彻底消除证书签发、续期及吊销过程中的人工干预。
具备合规性的审计追踪
从密钥生成到吊销,每一步均被不可变更地记录,原生支持审计合规。
可衡量的投资回报率
根据 HashiCorp 的经验案例显示,在相似环境中可降低超过 60% 的运维成本。证书周期越短,节省效果越显著。
战略性应对方案
| 选项 | 风险 | 适用场景 |
|---|---|---|
| 维持现状 | 高风险:人力负担、系统故障、审计问题 | 证书数量少、外部依赖低的小型系统 |
| 云端 PKI 服务 | 中等风险:厂商锁定,限制多云策略 | 单云部署、合规要求不高的工作负载 |
| 企业级 PKI + HashiCorp Vault | 低风险:完全可控、可扩展、可审计 | 关键业务系统及多云发展路线的企业 |
时间安排与预算规划
- 2025 年内确认预算 - 第一轮有效期缩短将在 2026 财年中期生效。
- 预留 6–9 个月用于流程与工具部署。
- 试点阶段:从非关键服务入手,积累 KPI 后再规模化扩展。
为何选择 ICT.technology 成为您的 Trusted Advisor

- HashiCorp 官方合作伙伴,拥有认证 Vault 顾问
- 法律与监管:深耕金融科技、医疗、工业等领域
- 端到端方法论:从战略咨询到 IaC 实施(Terraform Stacks、Ansible、OCI、AWS),直至托管 PKI 运维
- 基于成功经验的模板化落地,覆盖众多企业项目
下一步行动
准备好迎接 PKI 转型了吗?
立即预约,获取一次免费评估与定制化的 Vault 策略建议。
我们建议的后续步骤如下:
- PKI 评估:梳理现有证书资产与成熟度
- 定义目标架构:本地、云端或混合部署
- 设计 PKI 策略:充分契合您的个性化需求
- Vault 试点 / 概念验证:低风险、可度量、可扩展
- 分阶段 Roll‑out:逐步迁移关键系统
参考资料
- CA/Browser Forum, Ballot SC‑081v3, 2025 年 4 月 11 日(CA/Browser Forum)
- BusinessWire:“CA/Browser Forum Passes Ballot to Reduce SSL/TLS Certificates to 47 Day Maximum Term”,2025 年 4 月 14 日(Business Wire)
- Ponemon Institute:“Key and Certificate Errors Survey”,2020 年(73% 故障来源)(mcpmag.com)
- HashiCorp 案例研究 “Running HashiCorp with HashiCorp”,2021 年 – 节省超过 60% 运维成本(HashiCorp - PDF 下载)

在本系列的上一部分中,我们展示了看似无害的 Terraform 模块中 Data Sources 如何演变成严重的性能问题。结果包括长达数分钟的 terraform plan 执行时间、不稳定的流水线以及无法控制的 API 节流效应。
那么,如何优雅且可持续地避免这一扩展陷阱?
在本部分中,我们将介绍一些经过验证的架构模式,帮助您实现 Data Sources 的集中化管理,以资源友好的方式进行注入,从而即便在存在数百个模块实例的情况下,也能实现快速、稳定且可预测的 Terraform 执行。
内容包括:三种可扩展的解决策略、一份经过实战验证的逐步指南以及一份面向生产环境的基础设施模块最佳实践检查清单。

Terraform 的 Data Sources 是一种常用方式,用于动态地将各个云环境中真实存在的值填充到变量中。但在动态基础架构中使用它们则需要更长远的视角。比如,在某个模块中使用一个看似无害的 data.oci_identity_availability_domains 就足以让每次执行 terraform plan 的时间从几秒变为几分钟。因为 100 个模块实例就意味着 100 次 API 调用,而您的云服务提供商将开始限制请求频率。欢迎来到通过 Data Sources 意外触发 API 调用放大的世界。
本文将向您展示,为何在 Terraform 模块中使用 Data Sources 可能成为一个扩展性问题。

即使是最复杂的基础设施架构也无法防止所有错误。因此,主动监控 Terraform 操作至关重要 - 尤其是那些可能造成破坏性影响的操作。其目标是在出现不可控的 Blast-Radius(爆炸半径)之前,尽早识别关键变更并自动发出警报。
当然了 —— 您的系统工程师现在肯定会提醒您,Terraform 在执行 apply 之前会显示完整的计划,且需要在执行前手动输入 "yes" 进行确认。
但您的工程师没有告诉您的是:他在执行前并不会真正阅读这个计划。
“应该不会出问题。”